Cómo Descargar los Datos de la Base de Datos de Auditoría a AWS S3 y Leerlos Usando el Servicio AWS Athena
Archivado de Auditoría es una función opcional de la Tarea de Limpieza de la Base de Datos de Auditoría en DataSunrise Database Security. Esta función permite a un administrador de instalación de DataSunrise eliminar datos de auditoría más antiguos para almacenarlos en el servicio AWS S3, proporcionando un método más eficiente y rentable de almacenamiento de datos expirados. Con el uso del Servicio Athena de AWS, el equipo de seguridad y los auditores externos pueden examinar los datos históricos necesarios para auditorías e investigaciones de incidentes. Además, el uso del archivado de auditoría permite a los clientes de DataSunrise mantener conjuntos de datos más grandes de eventos auditados sin almacenar todo en una única base de datos de almacenamiento de auditoría y experimentar tiempos de reporte incrementados. Además, el uso de S3 para datos fríos es una solución más rentable, lo que puede ayudar a optimizar el presupuesto del proyecto manteniendo el tamaño de la base de datos de auditoría bajo control.
Para el Archivado de Auditoría, el equipo de DataSunrise proporciona el script dedicado para implementaciones en Linux que se puede ajustar para colocar los datos eliminados en una ubicación S3 personalizable. Esto forma parte del paquete de instalación predeterminado de DataSunrise, por lo que no necesitas descargarlo de ningún lugar adicionalmente.
Este artículo te guiará a través del proceso de configuración y la tarea de limpieza de auditoría, descargando los datos eliminados en la ubicación de tu elección del Bucket S3 y configurando el entorno en AWS Athena para la forense.
Configurar una Tarea de Limpieza de Datos de Auditoría con la opción de Archivado de Auditoría
- Abre la interfaz web de DataSunrise y navega hasta Configuración → Tareas Periódicas. Haz clic en el botón Nueva Tarea y proporciona la información general como Nombre, Tipo de Tarea (por ejemplo, Limpiar Datos de Auditoría) y selecciona el servidor para ejecutar la tarea en caso de que estés usando un clúster de nodos de DataSunrise.
- Configura las Opciones de Archivo en la sección Limpiar Datos de Auditoría:
- Marca la opción de Archivar Datos Eliminados antes de limpiar.
- Especifica la ruta de la Carpeta de Archivo donde los datos de auditoría deben almacenarse temporalmente antes de moverlos a S3.
- Especifica la ruta al script que carga los datos en AWS S3 usando el campo de entrada “Ejecutar Comando Después de Archivar”. Ruta predeterminada – /opt/datasunrise/scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
(requerido) - Proporciona parámetros adicionales para el script para ajustar el comportamiento (ver abajo para los argumentos opcionales del script)
- Ajusta la Frecuencia de la Tarea en la sección “Frecuencia de Inicio”, puedes configurar con qué frecuencia debe ejecutarse la tarea (por ejemplo, diariamente, semanalmente, mensualmente) según las necesidades de la organización para la retención y archivo de datos de auditoría.
- Guarda la tarea después de configurar todos los ajustes necesarios.
- Inicia la tarea manual o automáticamente. Si el usuario configuró la tarea para iniciarse manualmente, el usuario puede iniciarla seleccionando la tarea y haciendo clic en Iniciar Ahora. Si está configurada para comenzar según un horario, se ejecutará automáticamente en los tiempos especificados.
- Después de realizar la tarea, se creará una carpeta de archivo en el sistema de archivos del servidor de DataSunrise donde la tarea fue ejecutada (en distribuciones Linux, la ruta predeterminada será /opt/datasunrise/).
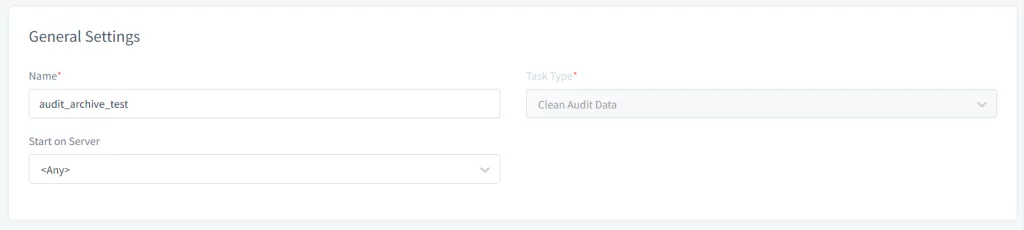
Imagen 1. Configuraciones Generales
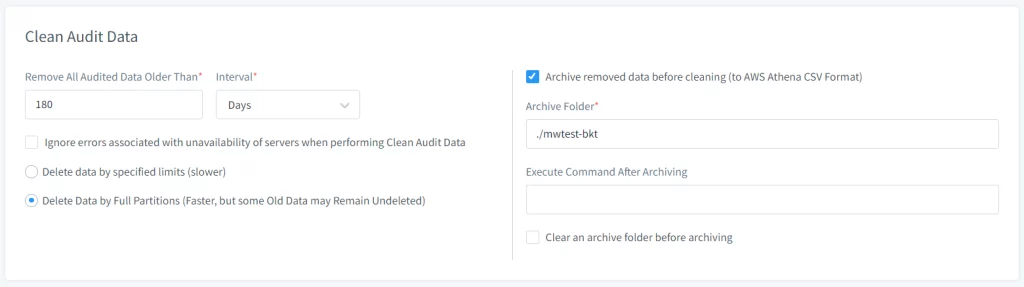
Imagen 2. Tarea Periódica de Limpieza de Datos de Auditoría
Nota: si estás ejecutando DataSunrise en AWS ECS Fargate, utiliza ecs_upload_ds_audit_to_aws_s3.sh en su lugar ubicado en el mismo directorio.
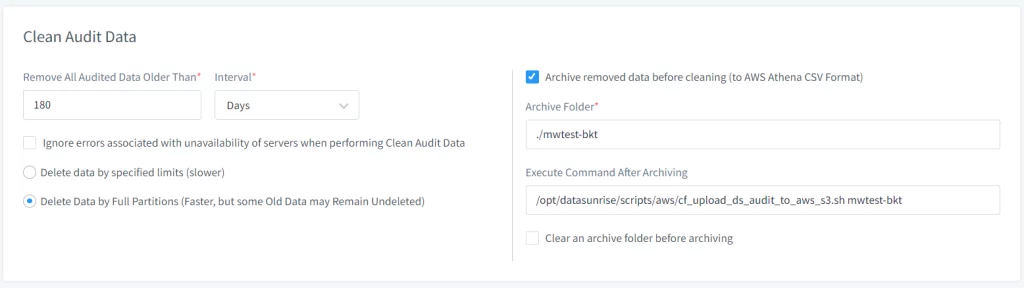
Imagen 3. Comandos Extra para la Tarea de Limpieza de Auditoría
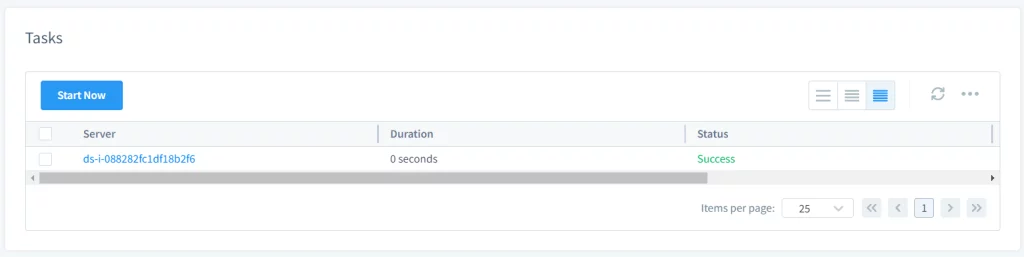
Imagen 4. Iniciar la Tarea
Nota: Los pasos anteriores también se pueden usar para gestionar la retención de datos de auditoría en DataSunrise, los usuarios pueden utilizar la función “Limpieza Periódica de Auditoría” para eliminar regularmente los datos de auditoría obsoletos. Esto garantiza la eficiencia del servidor de DataSunrise al prevenir un desbordamiento de almacenamiento con datos desactualizados.
El Script de Carga de Datos de Auditoría Archivados
Para cargar la carpeta de archivo en un bucket de AWS S3 utiliza el script proporcionado por DataSunrise ubicado en la carpeta
Para personalizar el procedimiento, puedes utilizar las siguientes opciones opcionales:
- –-carpeta-archivo: anula la carpeta predeterminada en el servidor de DataSunrise para colocar los archivos de datos de auditoría archivados. De forma predeterminada, se creará la carpeta ds-audit-archive en la ubicación /opt/datasunrise/.
- –carpeta-en-bucket: proporciona tu propio prefijo para colocar los datos auditados. Por defecto, el script descarga datos en el prefijo
/ds-audit-archive. - –credenciales-predefinidas: En caso de que estés ejecutando DataSunrise fuera de AWS, para poder cargar datos a S3, necesitarás ya sea un archivo de credenciales o el par de claves ACCESS/SECRET para el Usuario IAM autorizado para acceder al Bucket S3 deseado. No requiere ninguna entrada.
Nota: El tamaño de la carpeta es monitorizado durante la descarga de auditoría, y cuando excede un cierto límite, se ejecuta el comando. Si no se especifica ningún script, ocurre un error cuando se excede el umbral. El umbral se establece utilizando el Parámetro Adicional “AuditArchiveFolderSizeLimit”, con un valor predeterminado de 1 GB. Un usuario puede limpiar previamente una carpeta de archivo usando la opción “Limpiar una carpeta de archivo antes de archivar”.
Consideraciones
- El nombre del bucket para cargar los datos archivados debe ser proporcionado sin el esquema s3://
Estructura de la Carpeta de Archivo de Auditoría
La estructura de la carpeta de archivo donde DataSunrise almacena los datos de auditoría sigue típicamente un formato jerárquico organizado por fecha. Esta organización ayuda a gestionar los datos de manera eficiente y hace que sea más fácil localizar registros de auditoría específicos en función de la fecha. Aquí tienes un esquema general de cómo podría lucir la estructura:
Plantilla Generalizada de Estructura de Carpeta
Directorio Base: /opt/datasunrise/ds-audit-archive/
└── Año: {YYYY}/
└── Mes: {MM}/
└── Día: {DD}/
└── Archivos de Auditoría: audit_data_{YYYY}-{MM}-{DD}.csv.gzNota: Los archivos estarán en forma comprimida y deberán descomprimirse para leer la información (por ejemplo, los usuarios pueden usar el comando gunzip).
Una vez que los datos de auditoría se cargan en S3, la estructura se conserva de la misma manera que se almacenó en el servidor de DataSunrise:
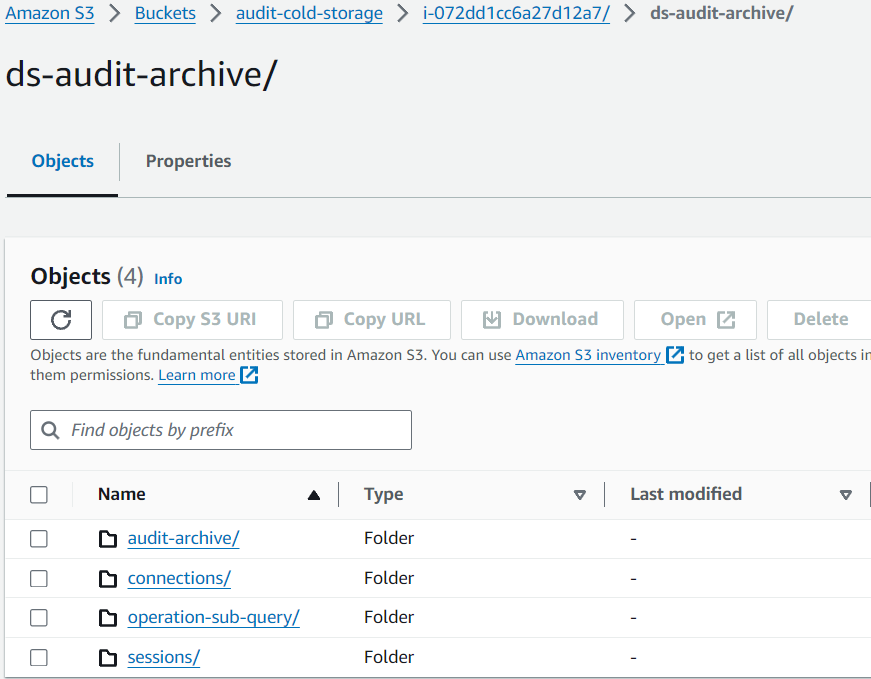
Imagen 5. Datos en el Bucket de Amazon S3
Usando AWS Athena para leer Datos de Archivo de Auditoría desde S3
Una vez que los datos de auditoría están cargados en S3, puedes crear el esquema de la Base de Datos de Auditoría en el Servicio AWS Athena para un análisis posterior. Prosigue a AWS Athena en la Consola de Gestión de AWS para configurar una Base de Datos y objetos de Tabla Externa para leer tus datos archivados.
Crear tablas de Archivo de Auditoría en AWS Athena
Los scripts SQL suponen lo siguiente para la cláusula LOCATION de las consultas CREATE EXTERNAL TABLE:
- El nombre del Bucket S3 es datasunrise-audit
El archivo SQL DDL para las tablas de Archivo de Auditoría de AWS Athena también está disponible desde la distribución de DataSunrise con la ruta predeterminada /opt/datasunrise/scripts/aws/aws-athena-create-audit-archive-tables.sql.
-- La siguiente consulta crea una base de datos en Athena
CREATE DATABASE IF NOT EXISTS datasunrise_audit;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.audit_archive (
operations__id STRING,
operations__session_id STRING,
operations__begin_time STRING,
operations__end_time STRING,
operations__type_name STRING,
operations__sql_query STRING,
operations__exec_count STRING,
sessions__user_name STRING,
sessions__db_name STRING,
sessions__service_name STRING,
sessions__os_user STRING,
sessions__application STRING,
sessions__begin_time STRING,
sessions__end_time STRING,
connections__client_host_name STRING,
connections__client_port STRING,
connections__server_port STRING,
connections__sniffer_id STRING,
connections__proxy_id STRING,
connections__db_type_name STRING,
connections__client_host STRING,
connections__server_host STRING,
connections__instance_id STRING,
connections__instance_name STRING,
operation_rules__rule_id STRING,
operation_rules__rule_name STRING,
operation_rules__chain STRING,
operation_rules__action_type STRING,
operation_exec__row_count STRING,
operation_exec__error STRING,
operation_exec__error_code STRING,
operation_exec__error_text STRING,
operation_group__query_str STRING,
operations__operation_group_id STRING,
operations__all_exec_have_err STRING,
operations__total_affected_rows STRING,
operations__duration STRING,
operations__type_id STRING,
connections__db_type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/audit-archive/' -- ruta a carpeta S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La siguiente consulta carga particiones para poder consultar los datos.
MSCK REPAIR TABLE datasunrise_audit.audit_archive;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.sessions (
partition_id STRING,
id STRING,
connection_id STRING,
host_name STRING,
user_name STRING,
scheme STRING,
application STRING,
thread_id STRING,
process_id STRING,
begin_time STRING,
end_time STRING,
error_str STRING,
params STRING,
db_name STRING,
service_name STRING,
os_user STRING,
external_user STRING,
domain STRING,
realm STRING,
sql_state STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/sessions/' -- ruta a carpeta S3
TBLPROPERTIES ('has_encrypted_data'='false','skip.header.line.count'='1');
-- La siguiente consulta carga particiones para poder consultar los datos.
MSCK REPAIR TABLE datasunrise_audit.sessions;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.connections (
partition_id STRING,
id STRING,
interface_id STRING,
client_host STRING,
client_port STRING,
begin_time STRING,
end_time STRING,
client_host_name STRING,
instance_id STRING,
instance_name STRING,
proxy_id STRING,
sniffer_id STRING,
server_host STRING,
server_port STRING,
db_type_id STRING,
db_type_name STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/connections/' -- ruta a carpeta S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La siguiente consulta carga particiones para poder consultar los datos.
MSCK REPAIR TABLE datasunrise_audit.connections;
--------------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.operation_sub_query (
operation_sub_query__operation_id STRING,
operation_sub_query__session_id STRING,
operation_sub_query__type_name STRING,
operations__begin_time STRING,
operation_sub_query__type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/operation-sub-query/' -- ruta a carpeta S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La siguiente consulta carga particiones para poder consultar los datos.
MSCK REPAIR TABLE datasunrise_audit.operation_sub_query;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.session_rules (
session_id STRING,
rule_id STRING,
rule_name STRING,
chain STRING,
action_type STRING,
sessions__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/session-rules/' -- ruta a carpeta S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La siguiente consulta carga particiones para poder consultar los datos.
MSCK REPAIR TABLE datasunrise_audit.session_rules;
--------------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.col_objects (
operation_id STRING,
session_id STRING,
obj_id STRING,
name STRING,
tbl_id STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/col-objects/' -- ruta a carpeta S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La siguiente consulta carga particiones para poder consultar los datos.
MSCK REPAIR TABLE datasunrise_audit.col_objects;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.tbl_objects (
tbl_objects__operation_id STRING,
tbl_objects__session_id STRING,
tbl_objects__obj_id STRING,
tbl_objects__sch_id STRING,
tbl_objects__db_id STRING,
tbl_objects__tbl_name STRING,
tbl_objects__sch_name STRING,
tbl_objects__db_name STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/tbl-objects/' -- ruta a carpeta S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La siguiente consulta carga particiones para poder consultar los datos.
MSCK REPAIR TABLE datasunrise_audit.tbl_objects;
Consulta los datos en la Consola de AWS Athena usando consultas estándar SQL:
--ejecución de SELECT contra la tabla audit_archive con los filtros por año, mes y día
SELECT * FROM audit_archive WHERE year = '2024' and month = '05' and day = '16';
--seleccionar datos de múltiples tablas a través de la cláusula JOIN
SELECT
r.operations__type_name,
s.operation_sub_query__type_name,
r.operations__sql_query
FROM audit_archive AS r
JOIN operation_sub_query AS s
ON
r.operations__id = s.operation_sub_query__operation_id
AND
r.operations__session_id = s.operation_sub_query__session_id;
–-ejecución de un SELECT simple consultando toda la tabla sin filtros aplicados
select * from audit_archive;
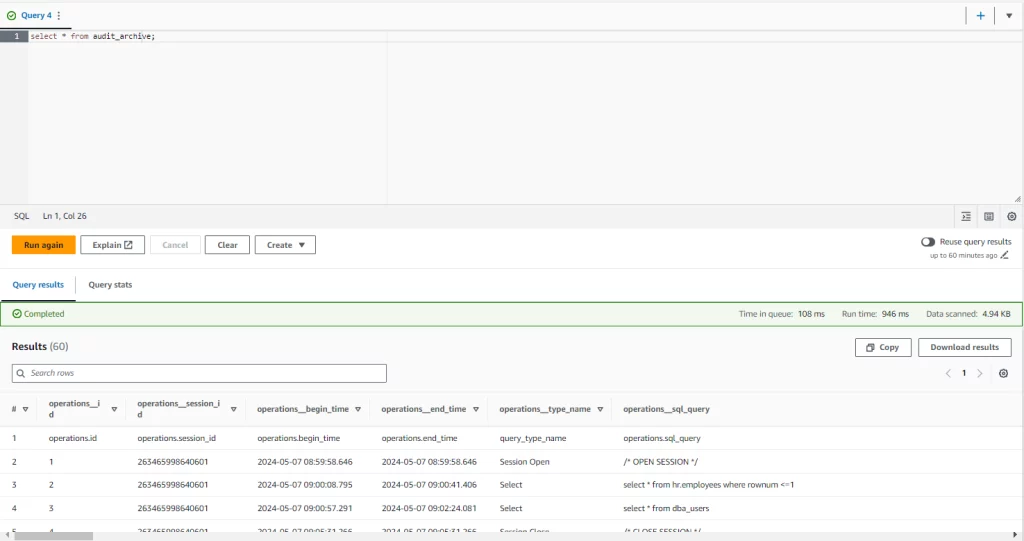
Imagen 6. Archivo de Auditoría
Conclusión
Un largo período de retención de datos para información sensible como eventos auditados puede ser un verdadero desafío y una carga adicional en el presupuesto para mantener grandes conjuntos de datos dentro de los archivos de la base de datos. El Archivado de Auditoría de DataSunrise proporciona una solución eficiente y segura para mantener los datos más antiguos legibles, descargando la capa de almacenamiento de la base de datos y permitiendo a nuestros clientes una solución resiliente y rentable basada en los Servicios AWS S3 Athena para mantener los datos antiguos dentro de tu Organización y accesibles para auditoría y cumplimiento.