Enmascaramiento en su lugar
Una de las formas de proteger los datos sensibles dentro de las bases de datos es el enmascaramiento de datos. En este artículo vamos a aprender más sobre el enmascaramiento de datos en su lugar y los pasos para enmascarar sus datos en el lugar utilizando DataSunrise Database Security.
Enmascaramiento Estático y Enmascaramiento en su Lugar
El enmascaramiento en su lugar se asemeja al enmascaramiento estático, ya que los datos enmascarados permanecen enmascarados de manera persistente y este proceso no se puede revertir.
La diferencia entre el enmascaramiento en su lugar y el enmascaramiento estático es que en el enmascaramiento estático tenemos 2 bases de datos:
- base de datos fuente que contiene los datos originales
- base de datos de destino con los datos enmascarados
En el caso del enmascaramiento en su lugar, tenemos solo una base de datos que actúa como fuente y destino al mismo tiempo.
El enmascaramiento en su lugar se usa mejor como parte de un enfoque híbrido de protección de bases de datos donde diferentes bases de datos son protegidas utilizando diferentes tipos de enmascaramiento:
- enmascaramiento estático
- enmascaramiento en su lugar
- enmascaramiento dinámico
Todos estos tipos de enmascaramiento están disponibles en el DataSunrise Database Protection Suite para garantizar que sus bases de datos estén protegidas en todo momento.
Enmascaramiento en su Lugar en la Práctica
A veces el enmascaramiento estático no es una buena opción:
- impone una carga adicional a la base de datos de producción.
- requiere acceso al entorno de producción desde el entorno de prueba. En algunas arquitecturas de sistemas, esto es físicamente imposible.
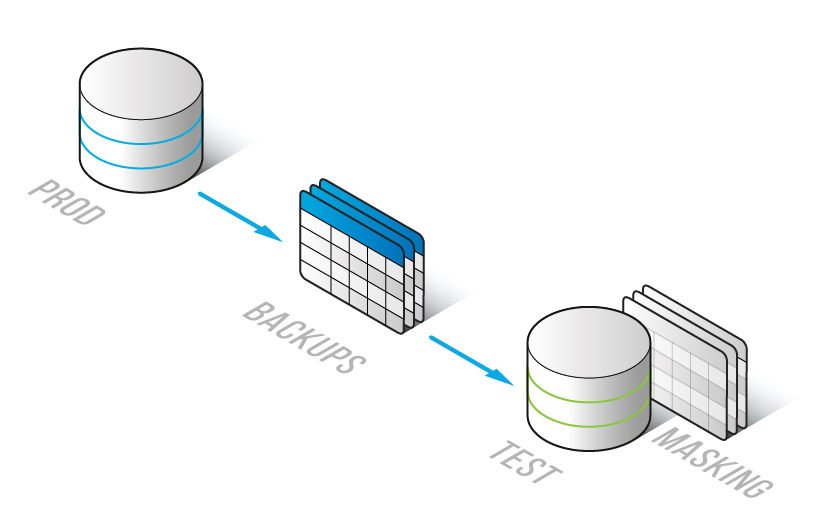
En este caso, los datos se pueden replicar en el entorno de pruebas utilizando copias de seguridad de la base de datos de producción. Las copias de seguridad de cualquier base de datos de producción se hacen regularmente. Así que solo necesitamos:
- restaurar la base de datos en el entorno de prueba
- enmascarar los datos en nuestro entorno de prueba, donde los datos sensibles originales se pierden al ser reemplazados por datos enmascarados
Este método de enmascaramiento se llama “enmascaramiento en su lugar” porque los datos se enmascaran donde residen. Utilice este método solo en bases de datos no productivas.
DataSunrise intenta preservar (reconstruir después del enmascaramiento) todas las restricciones únicas, claves foráneas, índices, restricciones de verificación y restricciones predeterminadas en una base de datos. Sin embargo, no siempre es posible. También se conservan los contadores de auto-incremento (excepto para las bases de datos Redshift).
El filtrado de tablas en su lugar funciona de la misma manera que en el enmascaramiento estático, es decir, los datos que no cumplen con las condiciones de filtrado se eliminan permanentemente.
Pasos del Enmascaramiento en su Lugar desde DataSunrise
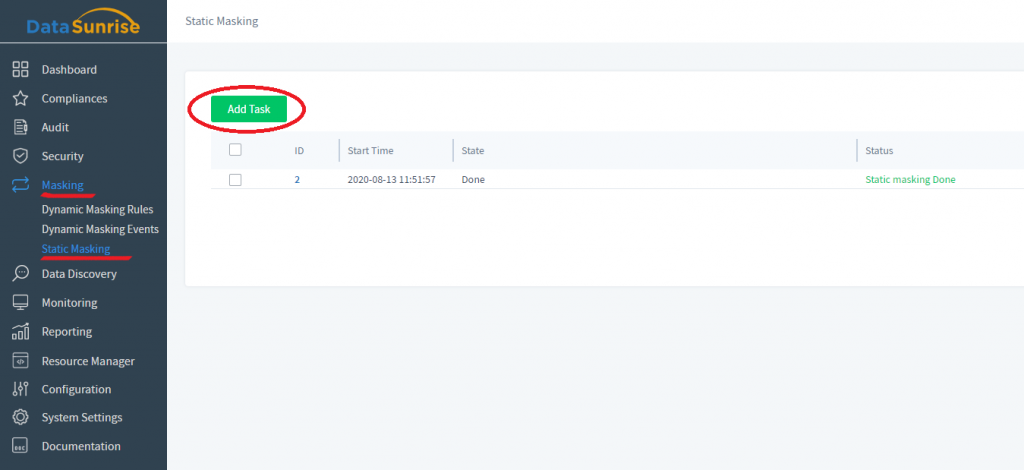
1) Si desea enmascarar datos en su lugar, elija Enmascaramiento → Enmascaramiento estático en el panel izquierdo de la interfaz de DataSunrise. Luego haga clic en Agregar Tarea. Todas las tareas anteriores de enmascaramiento en su lugar se guardarán aquí para su referencia.
2) Después de eso, elija la instancia fuente. En el campo de instancia de destino, elija Enmascarar en su lugar. Por favor, no olvide hacer una copia de seguridad de sus datos, porque como resultado del enmascaramiento en su lugar los datos originales se reemplazan permanentemente con datos enmascarados. Después de eso, elija la base de datos que desea enmascarar en el lugar y un esquema. En la siguiente imagen, esta base de datos se llama “sales_summer” y el esquema es “public”. En la sección Tablas Transferidas a continuación, algunas casillas de verificación se marcan automáticamente para asegurar un mejor enmascaramiento.
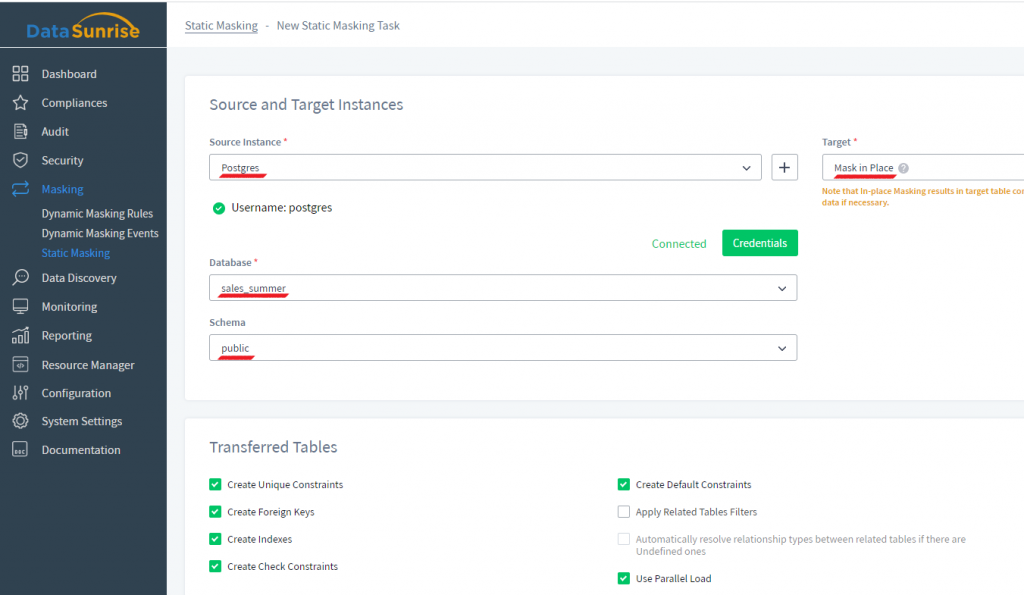
Aquí está lo que hacen estas casillas de verificación:
- Crear Restricciones Únicas, Crear Claves Foráneas, Crear Índices, Crear Restricciones de Verificación, Crear Restricciones Predeterminadas significan que estos elementos se reconstruirán en el esquema enmascarado, si es posible.
- Usar Carga Paralela – aumenta la velocidad de enmascaramiento para tablas grandes.
- Aplicar Filtros de Tablas Relacionadas – el filtro se aplicará no solo a una tabla especificada, sino también a las tablas relacionadas con esta tabla a través de claves foráneas.
- Resolver automáticamente los tipos de relación entre las tablas relacionadas si hay tipos indefinidos – esto significa que las tablas relacionadas no solo se descubrirán por la herramienta de Relaciones de Tablas (Configuración → Relaciones de Tablas en la interfaz de DataSunrise), sino también según un algoritmo que utiliza relaciones indirectas de tablas.
3) Desplácese hacia abajo y haga clic en Seleccionar en la sección Tablas Transferidas.
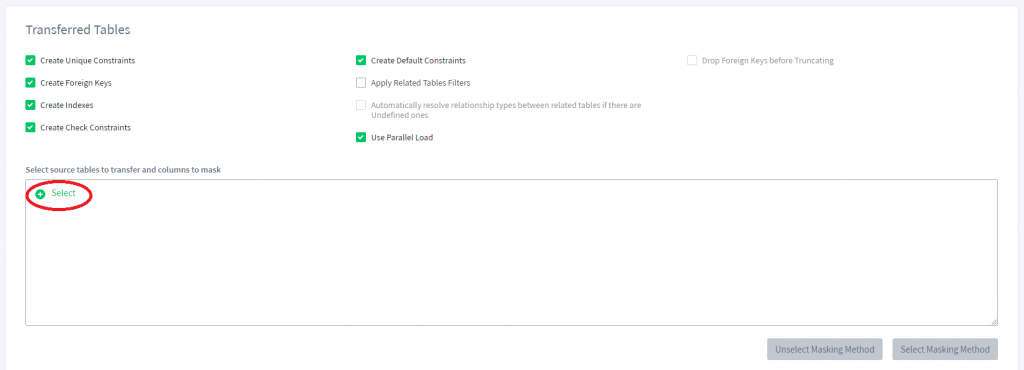
4) Ahora seleccionemos todo el esquema donde queremos que varias tablas sean seleccionadas (para nosotros es el esquema “public”) y hagamos clic en Hecho.
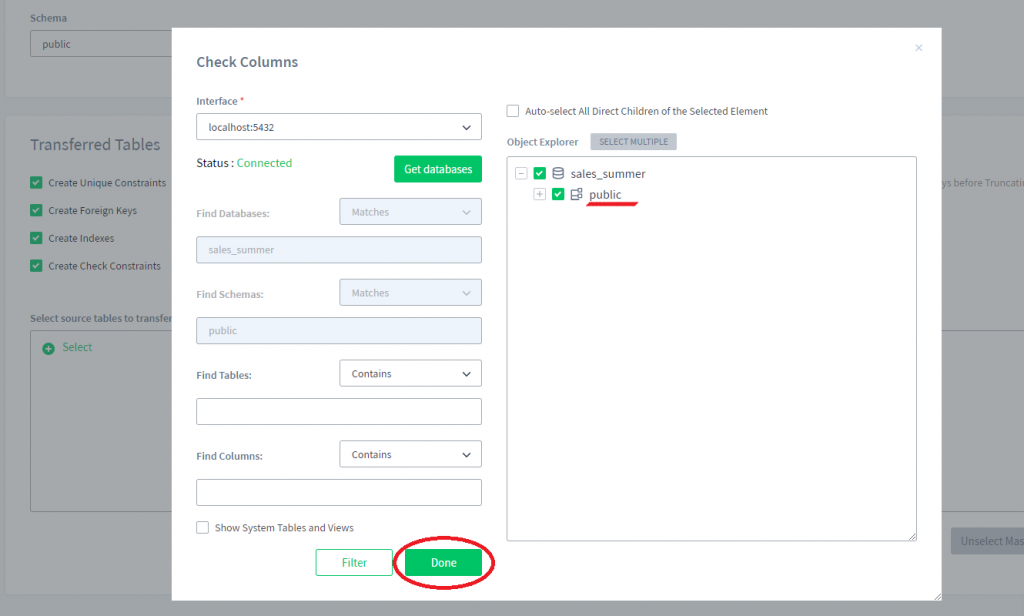
5) Ahora podemos expandir el esquema “public” seleccionado y seleccionar columnas para enmascarar.
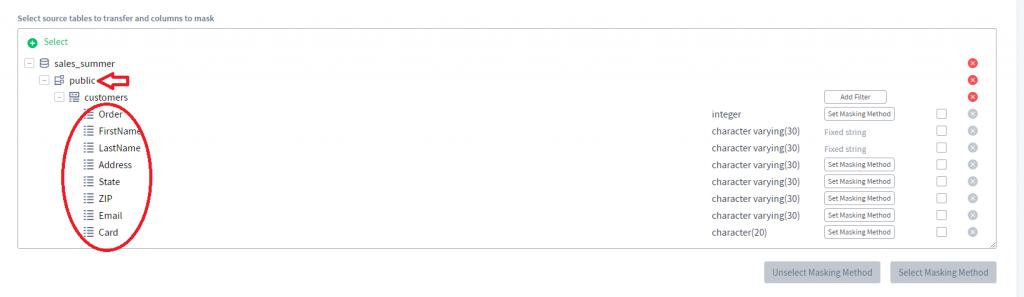
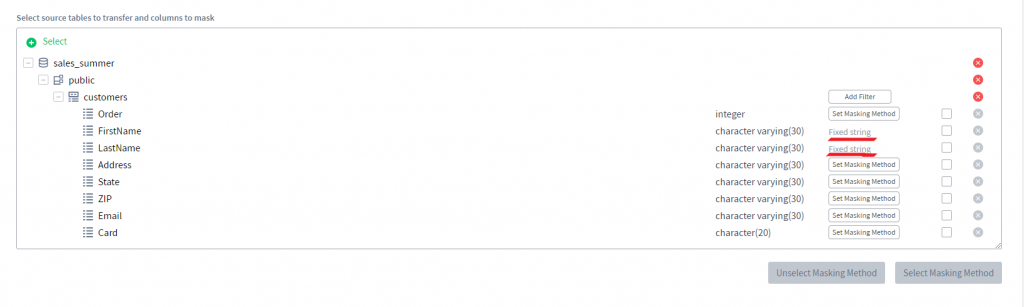
6) Para cada una de las columnas, puede configurar un método de enmascaramiento haciendo clic en el botón Configurar Método de Enmascaramiento. Vamos a enmascarar las columnas FirstName y LastName usando una cadena fija.
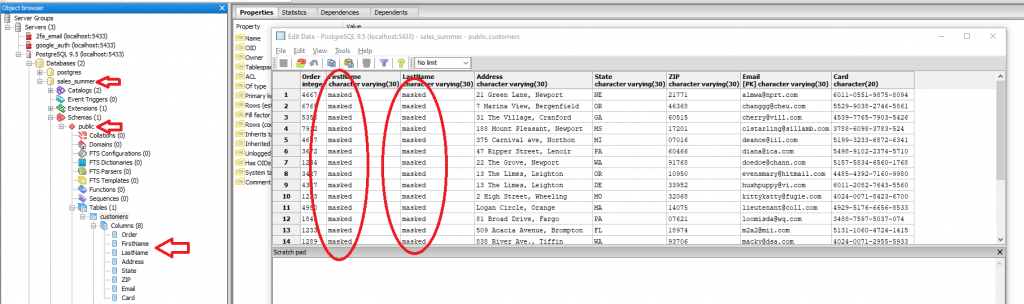
En la imagen a continuación, puede ver cómo se ven nuestros datos ahora en nuestra tabla PostgreSQL. Como puede ver, las columnas FirstName y LastName están enmascaradas en su lugar ahora.
El enmascaramiento en su lugar de DataSunrise es una herramienta muy conveniente para mantener sus datos sensibles enmascarados y bajo control en todo momento.