
Nuevas Capacidades para el Descubrimiento de Datos Sensibles en Amazon S3 por DataSunrise
Introducción
Según una encuesta reciente, más del 50% de las empresas albergan una gran cantidad de datos sensibles en el almacenamiento en la nube, como S3 de Amazon.
DataSunrise Sensitive Data Discovery está disponible para la búsqueda, clasificación y gestión rápida de datos. Buscar y analizar datos en sus almacenamientos de datos asegura que pueda identificar datos sensibles en Amazon S3 a tiempo, de manera rápida y sin esfuerzo. Hemos mejorado nuestra herramienta. Antes podíamos descubrir datos semi-estructurados y no estructurados en S3 gracias a la función de NLP, y ahora podemos aún más.
DataSunrise Sensitive Data Discovery
El Descubrimiento de Datos para Amazon S3 tiene nuevas capacidades para la detección y protección de datos sensibles. Ahora el Descubrimiento de Datos está disponible para:
- Formato de archivo Apache Parquet;
- Archivos semi-estructurados como XML, JSON, CSV;
- Formatos de texto no estructurados como documentos de Microsoft Word;
- Imágenes.
El Descubrimiento de Datos para S3 analiza no solo los objetos, sino también sus nombres y caminos hacia ellos. DataSunrise conecta relaciones semánticas con el contexto del objeto para un descubrimiento completo y exhaustivo de datos sensibles. Así que no es necesario que se preocupe con los nombres específicos de los objetos que contienen información sensible y privada.
Plantillas predefinidas y personalizadas para PII. DataSunrise tiene muchas plantillas predefinidas para la búsqueda de datos sensibles como números de tarjetas de crédito, pasaportes, licencias de conducir. Para una búsqueda más flexible, puede aprovechar tipos de información personalizados (se pueden configurar utilizando expresiones regulares, scripts de Lua, etc.). Gracias a estos filtros, tendrá una imagen exhaustiva de los datos sensibles recopilados. La afinación del descubrimiento le ahorrará tiempo y otros recursos. Lo más importante es que estará seguro de que no hay datos sensibles que no estén bajo su control y que puedan llevar a la exposición de datos.
Descubrimiento de Datos Bajo Demanda. Puede crear y ejecutar Data Discovery no solo manualmente a través de la Consola Web. Utilice el terminal del sistema con la Interfaz de Línea de Comandos para crear sistemas automatizados que respondan a eventos de seguridad sin intervención manual.
Descubrimiento de Datos Sensibles en imágenes. Las empresas que almacenan datos sensibles en imágenes (licencia de conducir, SSN, etc.) estarán encantadas de utilizar DataSunrise Data Discovery con reconocimiento óptico de caracteres (OCR). El uso del descubrimiento de imágenes le permite buscar datos sensibles en imágenes gracias al motor OCR. Extrae texto de las imágenes, luego analiza esta información y encuentra datos privados de documentos. Nuestro Descubrimiento de Datos en Imágenes admite los siguientes formatos de archivo: JPG, PNG, GIF, TIFF, PSD.
Datos comprimidos y archivados Descubrimiento. Junto con los objetos y diferentes formatos de archivo, el Descubrimiento de Datos para S3 también puede buscar datos sensibles en formatos comprimidos y archivados. Los archivos comprimidos le permiten reducir el espacio utilizado, ahorrando así costos. Los archivos archivados le permiten recopilar y agrupar archivos en un solo lugar combinándolos. No importa el tamaño del archivo, los datos sensibles serán descubiertos.
Rendimiento del Descubrimiento de Datos Sensibles
El Descubrimiento de Datos Sensibles funciona en diferentes niveles en S3. Primero, puede descubrir sus cubos S3 y objetos para buscar información sensible. Es la manera más simple de encontrar información privada que debe ser protegida. Pero cuando tiene muchos cubos S3 y objetos en ellos, esta tarea será lenta y agotadora. Con DataSunrise, podrá ahorrar tiempo, presupuesto y otros recursos, ya que ahora DataSunrise admite varias técnicas para aumentar el rendimiento.
Inventario de AWS S3. Guarda todos los metadatos de sus cubos S3 en un solo lugar en forma de un archivo CSV archivado. Para reducir el consumo de tráfico y el costo de operación, DataSunrise puede obtener estos metadatos utilizando el Inventario de S3 sin llamadas a la API de AWS.
Descubrimiento de Datos Incremental. Con el Descubrimiento de Datos Incremental, no hay necesidad de descubrimientos repetitivos de los mismos objetos y cubos para la presencia de datos sensibles. El modo de escaneo incremental omite cubos y objetos descubiertos anteriormente. Escanea solo objetos nuevos o actualizados, comparándolos con la última hora escaneada. Le ayuda a ahorrar tiempo y dinero al trabajar con grandes volúmenes de datos. Además, el escaneo incremental es opcional, por lo que puede desactivarlo en cualquier momento que lo necesite.
Descubrimiento de Datos Paralelo. Para la búsqueda rápida de datos sensibles en grandes volúmenes de datos, puede utilizar el multiproceso implementado. Permite el uso de múltiples servidores de DataSunrise para el descubrimiento de datos en paralelo. Con el descubrimiento paralelo, podrá optimizar la utilización de la CPU y la memoria. El uso del multiproceso simplifica el trabajo de descubrimiento de datos cuando necesita procesar una gran cantidad de datos. También reduce la carga en el servidor y no impacta los procesos paralelos que tiene. Con el multiproceso, puede elegir múltiples atributos de búsqueda y excluir objetos específicos del escaneo.
Descubrimiento de Datos Aleatorios. Permite escanear archivos aleatorios en cubos S3 para acelerar el proceso de Descubrimiento de Datos. Es posible elegir el porcentaje de datos sensibles que se descubrirán en grandes volúmenes de datos.
Dividir archivos grandes en trozos. Los objetos grandes consumen espacio adicional, haciendo cálculos en memoria. Ahora podemos dividir cualquier objeto en trozos para aumentar el rendimiento y optimizar el uso de la memoria. Con parámetros adicionales como “DataDiscoveryChunkSize” y otros, podemos descubrir fácilmente estos trozos y encontrar cualquier información sensible.
Configuraciones y Personalización del Descubrimiento de Datos Sensibles
Puede ajustar el proceso de descubrimiento afinando algunos parámetros adicionales.
DataSunrise tiene más de 25 parámetros personalizables. Por ejemplo:
- “DataDiscoveryMatchesSaveStrategy” permite guardar las ocurrencias del Descubrimiento de Datos en el Diccionario dependiendo de sus necesidades particulares: guardar los primeros coincidencias, todas las coincidencias o coincidencias únicas;
- “DataDiscoveryChunkSize” permite la descarga parcial de los archivos para el Descubrimiento de Datos, para evitar el desbordamiento de la memoria. Puede establecer el tamaño del trozo y el límite de suma del trozo;
- “DataDiscoveryMaxFileSizeForChunkProcessing” es para el tamaño total del archivo a escanear como una SUMA de trozos. El procesamiento de trozos escanea hasta que se alcance el valor de este parámetro;
- “DataDiscoveryS3FilePartToRead” es para el tamaño máximo de archivo (Mb) para el Descubrimiento de Datos en S3. Este parámetro funciona junto con DataDiscoveryFilesThreadPools. Define el número de hilos utilizados para el procesamiento de archivos. Cada hilo procesa un archivo a la vez. Entonces, el valor de este parámetro depende de los recursos del sistema disponibles.
- “DataDiscoveryBatchSplitFactor” identifica en cuántas partes se dividirá el lote fallido para la nueva ejecución de la tarea de descubrimiento de datos.
Informes del Descubrimiento de Datos Sensibles
DataSunrise proporciona protección multinivel para AWS S3. Como resultado, DataSunrise opera con una gran cantidad de datos. Le permite obtener toda la información más detallada sobre sus bases de datos y los datos que contienen creando informes personalizados en formato CSV o PDF.
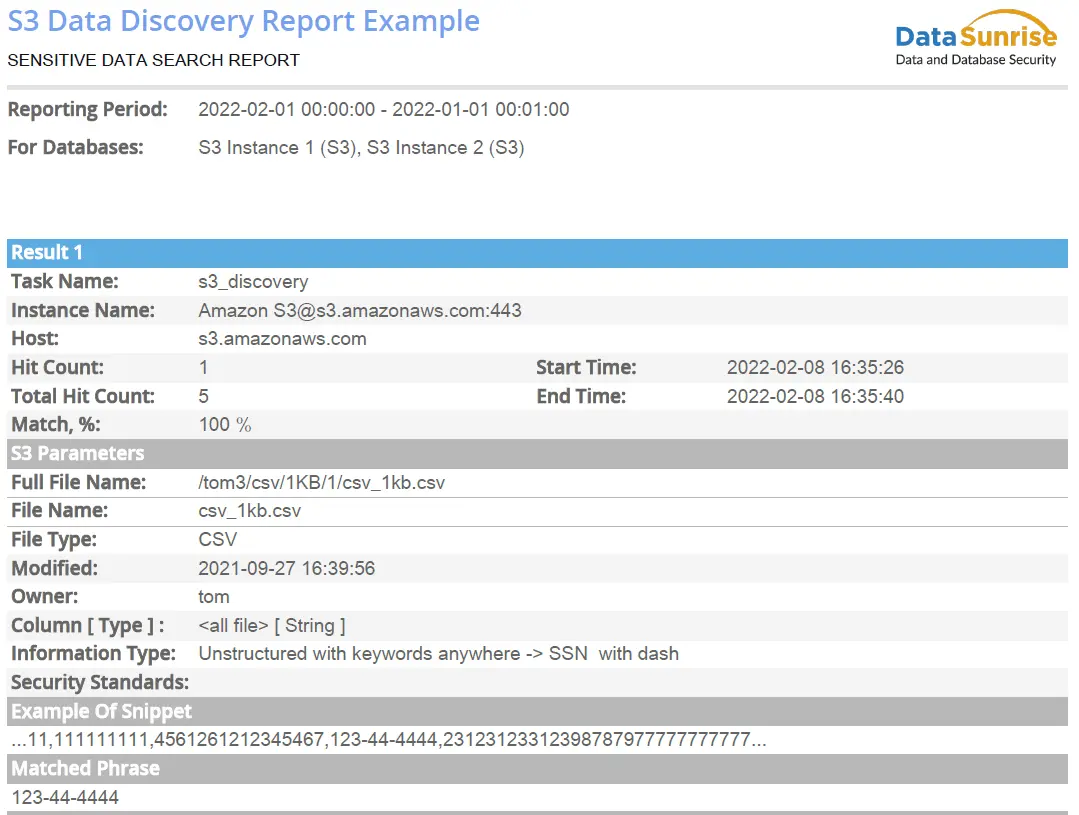
Imagen 1: Ejemplo de Informe PDF de Descubrimiento de Datos Sensibles
Disponibilidad de informes. Ahora la generación de informes es posible durante el proceso de la tarea de Descubrimiento, no hay necesidad de esperar a que la tarea se complete. Le permite ver resultados intermedios y utilizarlos para análisis.
Uso de los informes. A través de los resultados de los informes, puede recopilar análisis y obtener estadísticas sobre la velocidad de procesamiento de datos y atributos, y utilizar los datos recibidos para fines específicos, incluyendo el aprendizaje de su propia IA.
Con un sistema flexible de informes personalizables, ya no necesita monitorear manualmente la información sobre los niveles de protección de sus bases de datos.
Conclusión
El Descubrimiento de Datos Sensibles le permite saber dónde residen los datos sensibles en sus cubos AWS S3 y aprovechar los medios de protección de datos respectivamente.
DataSunrise proporciona una gran variedad de formatos y formas de descubrir datos sensibles en AWS S3 dondequiera que residan. Con el rendimiento mejorado, el Descubrimiento de Datos será menos consume mucho tiempo. Puede ajustar DataSunrise Sensitive Data Discovery para evitar búsquedas repetitivas innecesarias en grandes volúmenes de datos. Los patrones de búsqueda editables le permiten realizar una búsqueda de cualquier pieza específica de datos. Con los informes puede obtener la información más detallada que le permitirá ver resultados intermedios para análisis, aprendizaje de IA y otros procesos comerciales.
Para comenzar con DataSunrise con Amazon, visite DataSunrise en AWS Marketplace.
