
¿Qué es la Particionación?
La particionación implica dividir grandes objetos de base de datos, como tablas, índices y vistas, en partes más pequeñas y manejables. Este método mejora la organización de los datos, facilitando la gestión de grandes conjuntos de datos y mejorando el rendimiento, especialmente para datos complejos o voluminosos.
Las principales ventajas de la particionación son una mejor controlabilidad, rendimiento y disponibilidad. Permite a los administradores optimizar y mantener diferentes partes de la base de datos de manera independiente, mejorando la eficiencia de las consultas y el tiempo de actividad del sistema, al mismo tiempo que permite estrategias de gestión más enfocadas.
- En algunos casos, la particionación mejora el rendimiento al acceder a las tablas particionadas.
- La particionación puede desempeñar un papel en las columnas principales de los índices, lo que disminuye el tamaño del índice y aumenta la posibilidad de encontrar los índices más buscados en la memoria. Cuando una gran parte de una sección se utiliza en el conjunto de resultados, la exploración de esta sección puede realizarse mucho más rápido que un acceso ocasional a los datos distribuidos en toda la tabla por el índice.
- La carga masiva y la eliminación de datos pueden realizarse añadiendo y eliminando secciones, lo que ayuda a aumentar el rendimiento.
- Los datos de uso poco frecuente pueden cargarse en dispositivos de almacenamiento de datos más baratos.
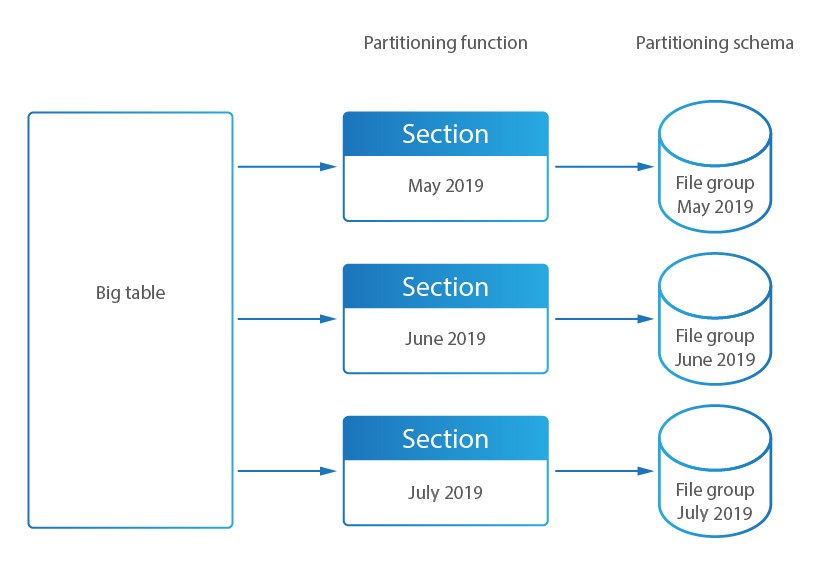
En DataSunrise, la particionación se utiliza para dividir las tablas de la base de datos de Almacenamiento de Auditoría en secciones (tablas más pequeñas). El Almacenamiento de Auditoría es una base de datos que se utiliza para almacenar los resultados de la Monitorización de Actividad de Base de Datos de DataSunrise.
- Hace que la administración del Almacenamiento de Auditoría sea más simple, ya que los datos particionados se distribuyen por particiones según el tiempo de particionación. El administrador de la base de datos puede deshabilitar la consulta de particiones, archivarlas, etc.
- Aumenta el rendimiento al acceder, recuperar datos y escribir datos en las tablas particionadas.
- Aumenta el rendimiento al eliminar datos de auditoría obsoletos del Almacenamiento de Auditoría.
DataSunrise admite la particionación para los siguientes tipos de bases de datos de Almacenamiento de Auditoría:
- PostgreSQL
- MySQL
- MS SQL Server
Parámetros de Particionación
Se pueden encontrar en Configuración del Sistema -> Parámetros adicionales.
- Duración de Particiones (días) – duración de la partición, días (si AuditPartitionShort == 1, entonces minutos). Se puede encontrar en Configuración del Sistema -> Almacenamiento de Auditoría. Si Duración de Particiones se cambia, todas las particiones creadas con anticipación se eliminarán y se crearán nuevas particiones con los nuevos parámetros de Duración de Partición.
- AuditPartitionCountCreatedInAdvance – número de particiones creadas con anticipación. Por lo tanto, particiones vacías creadas para llenarse en el futuro. Esto permite que DataSunrise escriba datos en particiones existentes sin demoras.
- AuditPartitionFirstEndDateTime – fecha/hora de finalización de la primera partición. Esta hora es necesaria para el ajuste de los límites de partición alrededor de un valor “redondo”. Por ejemplo: lunes 00:00:00 (si la duración de la partición es de 7 días).
Particionación en Entornos Modernos de Datos
La particionación se ha vuelto esencial en los entornos de big data. Muchas plataformas en la nube ofrecen opciones de particionación automática. AWS Redshift utiliza estilos de distribución para la mejor disposición de datos. Azure Synapse emplea métodos de distribución para mejorar el rendimiento de las consultas. La partición funciona bien con los lagos de datos que almacenan petabytes de información. Permite una recuperación de datos más rápida en aplicaciones de inteligencia empresarial. Muchas organizaciones implementan estrategias de particionación basadas en el tiempo. Este enfoque funciona bien para datos históricos y series temporales. Una particionación adecuada reduce costos al optimizar la utilización del almacenamiento. También mejora el cumplimiento de las políticas de retención de datos.
Estrategias Efectivas de Distribución de Datos
Crear estrategias efectivas de distribución de bases de datos requiere una planificación cuidadosa basada en patrones de acceso y requisitos empresariales. La organización por rangos funciona mejor para valores secuenciales como fechas, permitiendo que los equipos accedan rápidamente a datos recientes mientras archivan información más antigua.
La distribución por hash distribuye datos de manera uniforme a través de segmentos de almacenamiento, ideal para balancear la carga en entornos de alta concurrencia. Los enfoques basados en listas organizan los registros por valores categóricos específicos, haciéndolos perfectos para segmentación geográfica o departamental.
Muchas organizaciones implementan métodos híbridos, combinando múltiples técnicas de distribución para maximizar los beneficios de rendimiento mientras minimizan la sobrecarga de mantenimiento. Los análisis de poda regulares aseguran que las consultas apunten consistentemente solo a los segmentos de datos necesarios, ofreciendo un rendimiento óptimo a medida que los volúmenes de datos crecen.
Gestión de Particiones en DataSunrise
DataSunrise incluye mecanismos de gestión de particiones: DataSunrise crea tablas adicionales necesarias para la operación (para PostgreSQL), crea y mantiene funciones de particionamiento actualizadas, esquemas particionados, grupos de archivos e índices (para MS SQL), modifica claves e índices para cumplir con los requisitos de particionamiento (MySQL), habilita la particionación, crea y elimina particiones.
Las consultas SELECT se realizan a través de la tabla maestra. Las consultas INSERT/UPDATE se realizan directamente en la partición (excepto en MS SQL Server). Esto ayuda a aumentar la velocidad de escritura.
Nombres de Particiones y Tablas
Las particiones para PostgreSQL se organizan como tablas hijas nombradas <table_name>_p<datetime>, donde <table_name> es la tabla maestra, <datetime> es el tiempo límite superior de la partición en el siguiente formato: YYYYMMDDhhmm.
Para MySQL, la particionación se implementa utilizando mecanismos nativos. Los nombres de las particiones se forman según el siguiente esquema: p<datetime>, donde <datetime> es el tiempo límite superior de la partición en el siguiente formato: YYYYMMDDhhmm.
Para MS SQL Server, la partición se implementa a través del esquema.
