
Commutation de Données

Introduction
Dans le monde actuel axé sur les données, protéger les informations sensibles est d’une importance capitale. Les violations de données et les accès non autorisés aux données confidentielles peuvent entraîner de graves conséquences pour les particuliers et les organisations. C’est là que la commutation de données intervient.
La commutation de données est une technique utilisée pour obscurcir les données sensibles tout en préservant leur format et leur structure. Cet article explique les bases de la commutation de données, les différentes techniques et des conseils pour la mettre en œuvre dans votre organisation.
Qu’est-ce que la commutation de données ?
La commutation de données, également connue sous le nom de masquage des données, remplace les informations sensibles par des données fictives pour protéger la confidentialité. L’objectif est de protéger les données originales tout en maintenant leur utilité pour les tests, le développement ou les analyses. Les données permutées ressemblent aux données originales et sont utilisables dans des environnements non productifs.
Par exemple, imaginez une base de données contenant des informations sur les clients. Vous pouvez utiliser des techniques de commutation de données au lieu d’utiliser de vrais noms, adresses et numéros de carte de crédit à des fins de test.
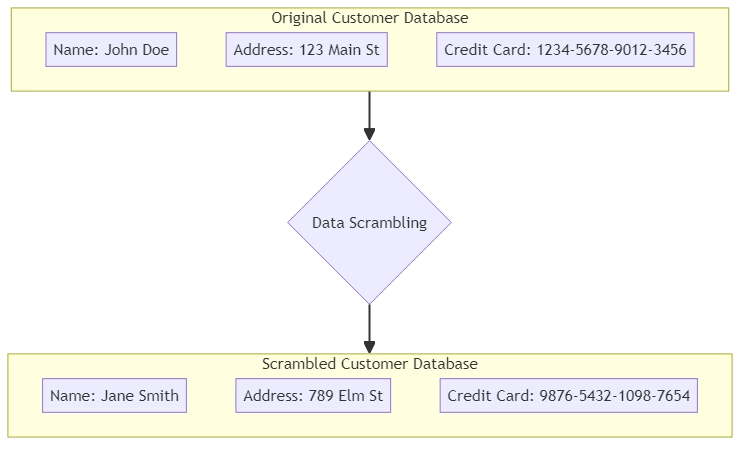
Ces méthodes remplacent les données sensibles par des valeurs générées aléatoirement qui imitent les informations originales.
Commutation de Données vs Masquage des Données
Bien que souvent utilisés de manière interchangeable, la commutation de données et le masquage des données présentent des distinctions importantes. La commutation de données se concentre principalement sur la randomisation ou la réorganisation des données tout en maintenant le format. Elle implique généralement des transformations irréversibles et est couramment utilisée pour la préparation des données de test où les valeurs exactes sont moins importantes que le maintien des propriétés statistiques.
En revanche, le masquage des données met l’accent sur le remplacement des données sensibles par des valeurs de substitution fonctionnelles, réalistes, qui “préservent l’apparence et la sensation des données tout en dissimulant les informations sensibles”. Contrairement à la commutation, le masquage peut être réversible pour les utilisateurs autorisés et est souvent employé dans les environnements de production où le maintien de la structure des données et de l’intégrité référentielle est crucial.
Les deux techniques sont reconnues dans les cadres de conformité tels que le RGPD, HIPAA et PCI DSS. De nombreuses organisations implémentent les deux dans le cadre d’un cadre de sécurité des données complet, appliquant la méthode appropriée en fonction du contexte spécifique et de la sensibilité des données à protéger.
Pourquoi la commutation de données est-elle importante ?
La commutation de données joue un rôle crucial dans la protection des informations sensibles et l’assurance de la conformité aux régulations de confidentialité des données. Voici quelques raisons clés pour lesquelles la commutation de données est essentielle :
- Protéger les données sensibles : En remplaçant les données sensibles par des valeurs fictives, la commutation de données aide à prévenir les accès non autorisés aux informations confidentielles. Même si les données permutées tombent entre de mauvaises mains, elles ne révèlent aucune information sensible réelle.
- Conformité aux réglementations : De nombreuses industries sont soumises à des réglementations strictes sur la confidentialité des données, telles que le RGPD, HIPAA, ou le PCI-DSS. La commutation de données aide les organisations à se conformer à ces règlements en désidentifiant les données sensibles avant de les utiliser à des fins de test, de développement ou d’analyse.
- Permettre des tests et développements réalistes : Les données permutées ressemblent aux données originales. Les développeurs et testeurs peuvent les utiliser pour travailler avec des données similaires aux données de production. Cela garantit que les tests sont plus précis et réduit le risque de problèmes lors du déploiement de l’application en production.
- Faciliter le partage de données : La commutation de données permet aux organisations de partager des données avec des parties externes, comme des partenaires ou des fournisseurs, sans risquer la confidentialité des informations sensibles. Les utilisateurs peuvent utiliser les données permutées pour la collaboration ou l’analyse tout en maintenant la confidentialité des données originales.
Techniques de Commutation
Différentes techniques utilisent la commutation de données, chacune avec ses propres forces et cas d’utilisation. Découvrons quelques techniques de commutation courantes :
1. Substitution
Dans la substitution, nous remplaçons les données sensibles par des valeurs aléatoires à partir d’un ensemble ou d’un modèle. Par exemple, vous pouvez remplacer des noms par des noms inventés à partir d’une liste. Vous pouvez également remplacer les numéros de carte de crédit par des numéros qui ressemblent à de vrais numéros de carte de crédit.
Exemple :
Données originales : John Doe, 1234-5678-9012-3456 Données permutées : Jane Smith, 9876-5432-1098-7654
2. Mélange
Le mélange implique de réorganiser l’ordre des valeurs des données dans une colonne ou entre plusieurs colonnes. Cette technique maintient la distribution des données originales mais rompt la relation entre différentes colonnes. Le mélange est utile lorsque les valeurs individuelles dans chaque colonne ne sont pas importantes. L’objectif principal est de maintenir la sécurité globale de la combinaison des valeurs.
Exemple : Données originales :
Nom Age Salaire John Doe 35 50000 Jane Doe 28 60000
Données permutées (colonnes Age et Salaire mélangées) :
Nom Age Salaire John Doe 28 60000 Jane Doe 35 50000
3. Cryptage
Le cryptage consiste à convertir les données sensibles dans un format illisible en utilisant un algorithme de cryptage et une clé secrète. Vous pouvez déchiffrer les données permutées pour les ramener à leur forme originale en utilisant la clé de décryptage correspondante. Le cryptage offre un haut niveau de sécurité mais peut affecter les performances et nécessite une gestion sécurisée des clés.
Exemple :
Données originales : John Doe Données permutées : a2VsZmF0aG9uIGRvb3IgZ
4. Tokenisation
La tokenisation remplace les données sensibles par un jeton ou identifiant généré aléatoirement. Le système stocke en toute sécurité les données sensibles dans une base de données ou un coffre-fort séparé. L’utilisateur utilise alors le jeton pour récupérer les informations originales lorsque c’est nécessaire. Les entreprises utilisent couramment la tokenisation pour protéger les numéros de carte de crédit et d’autres données financières sensibles.
Exemple :
Données originales : 1234-5678-9012-3456 Données permutées : TOKEN-1234
5. Masquage
Trois techniques de masquage courantes incluent le masquage de caractères, le masquage partiel et le masquage par expression régulière. Le masquage de caractères implique de remplacer les caractères par un symbole. Le masquage partiel ne montre qu’une partie des données. Le masquage par expression régulière remplace les données en fonction d’un modèle.
Exemple :
Données originales : 1234-5678-9012-3456 Données masquées : XXXX-XXXX-XXXX-3456
Bonnes Pratiques de Commutation de Données
Pour mettre en œuvre efficacement la commutation de données dans votre organisation, considérez les bonnes pratiques suivantes :
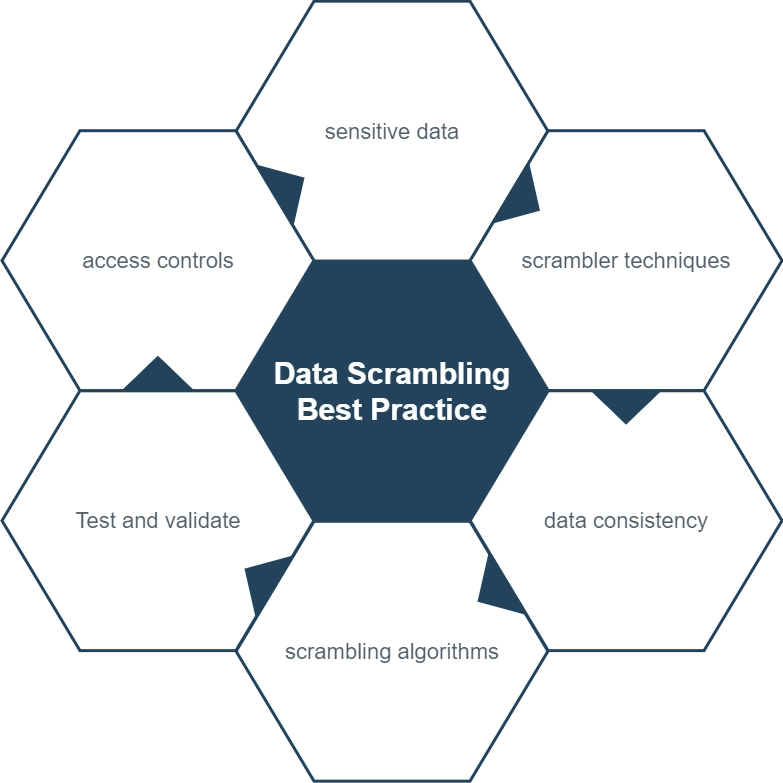
- Identifier les données sensibles : Effectuez un examen complet de votre environnement de données pour identifier les composants de données sensibles qui nécessitent une obfuscation. Prenez en compte les exigences légales et réglementaires, ainsi que les politiques internes de classification des données de votre organisation.
- Choisir des techniques de commutation appropriées : Sélectionnez la méthode la plus adaptée pour chiffrer les données en fonction du type de données et de son utilisation prévue. Prenez en compte des facteurs tels que le format des données, la complexité et le niveau de sécurité requis.
- Maintenir la cohérence des données : Assurez-vous que les données permutées maintiennent l’intégrité référentielle et la cohérence entre les tables et systèmes liés. Utilisez des techniques de commutation et des valeurs de graines cohérentes pour générer des données permutées cohérentes.
- Protéger les algorithmes et clés de permutation : Protégez les algorithmes, règles et clés de cryptage utilisés pour la commutation de données. Stockez-les en toute sécurité et limitez l’accès au personnel autorisé uniquement.
- Tester et valider les données permutées : Examinez attentivement les données permutées pour vous assurer qu’elles respectent les standards de format, de qualité et de cohérence requis. Assurez-vous que les données permutées ne contiennent aucune information confidentielle et qu’elles conviennent à l’utilisation prévue.
- Établir des contrôles d’accès : Utilisez des contrôles stricts et une surveillance pour empêcher l’accès non autorisé aux données sensibles et aux données permutées. Révisez et mettez régulièrement à jour les autorisations d’accès.
- Documenter et maintenir les processus de permutation : Documentez le processus d’intégration des données, y compris le volume des données impliquées et les configurations ou directives spécifiques. Maintenez le contrôle des versions et mettez à jour la documentation.
Conclusion
La commutation de données est une méthode utile pour protéger les données sensibles. Elle permet l’utilisation des données pour les tests, le développement et les analyses. En remplaçant les données sensibles par des données fictives mais réalistes, les organisations peuvent protéger les informations confidentielles, se conformer aux réglementations sur la confidentialité des données et faciliter le partage sécurisé des données.
Lors de l’utilisation de la commutation de données, il est important de choisir les bonnes techniques pour vos données et vos besoins. Pour garantir que votre processus de commutation de données soit efficace et sécurisé, suivez les bonnes pratiques. Gardez les données cohérentes, protégez les algorithmes et les clés, et mettez en place des contrôles d’accès. Cela aidera à maintenir la sécurité de vos données.
En utilisant la commutation de données dans votre plan de protection des données, vous pouvez équilibrer l’utilité des données et la confidentialité. Cela permet à votre organisation d’utiliser les données tout en conservant la confiance des clients et des parties prenantes.
Suivant
