
Le Mélange de Noms
Introduction
Les entreprises sont confrontées au défi de maintenir la confidentialité des données tout en utilisant des données réalistes pour les environnements de test et de développement. C’est là qu’interviennent le mélange de noms et la masquage des données.
Fait intéressant : l’ASS (Administration de la sécurité sociale) publie des données sur les prénoms donnés chaque année. En moyenne, il y a environ 30 000 à 35 000 prénoms uniques utilisés pour les nouveau-nés par an.
Cet article explorera le concept de mélange, sa mise en œuvre et ses avantages pour créer des données de test sécurisées.
DataSunrise offre des solutions de masquage des données de pointe, intégrant des techniques de mélange puissantes. Notre plateforme avancée garantit une protection robuste des données tout en maintenant leur utilité. Avec DataSunrise, les organisations peuvent en toute confiance se conformer aux réglementations sur la confidentialité et protéger les informations sensibles. Faites l’expérience d’un équilibre parfait entre sécurité et utilisabilité dans vos processus de gestion des données.
DataSunrise permet la sélection aléatoire de valeurs à partir de lexiques définis par l’utilisateur. Ces lexiques peuvent être créés manuellement ou remplis avec des valeurs issues de la base de données. Cette approche permet non seulement le mélange mais aussi la sélection aléatoire de valeurs.
Qu’est-ce que le Masquage de Données ?
Avant de plonger dans le mélange de noms, abordons brièvement le masquage de données. Le masquage de données est une méthode utilisée pour créer une version structurellement similaire mais inauthentique des données d’une organisation. Il remplace les informations sensibles par des données réalistes mais fausses. Cela permet aux entreprises d’utiliser des données masquées pour les tests, le développement et les analyses sans risquer l’exposition d’informations confidentielles.
Comprendre le Mélange de Noms
Qu’est-ce que le Mélange de Noms ?
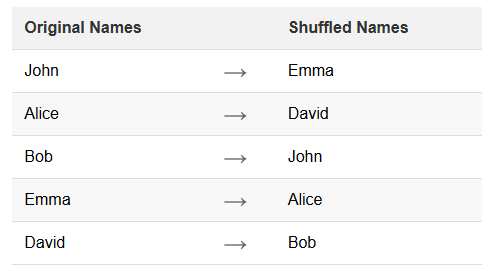
Le mélange de noms est une technique spécifique de masquage de données. Il consiste à réarranger les données existantes dans un ensemble de données. Cette méthode maintient l’intégrité et le réalisme des données tout en masquant les identités individuelles. Le mélange est particulièrement utile pour protéger les informations personnelles dans les bases de données.
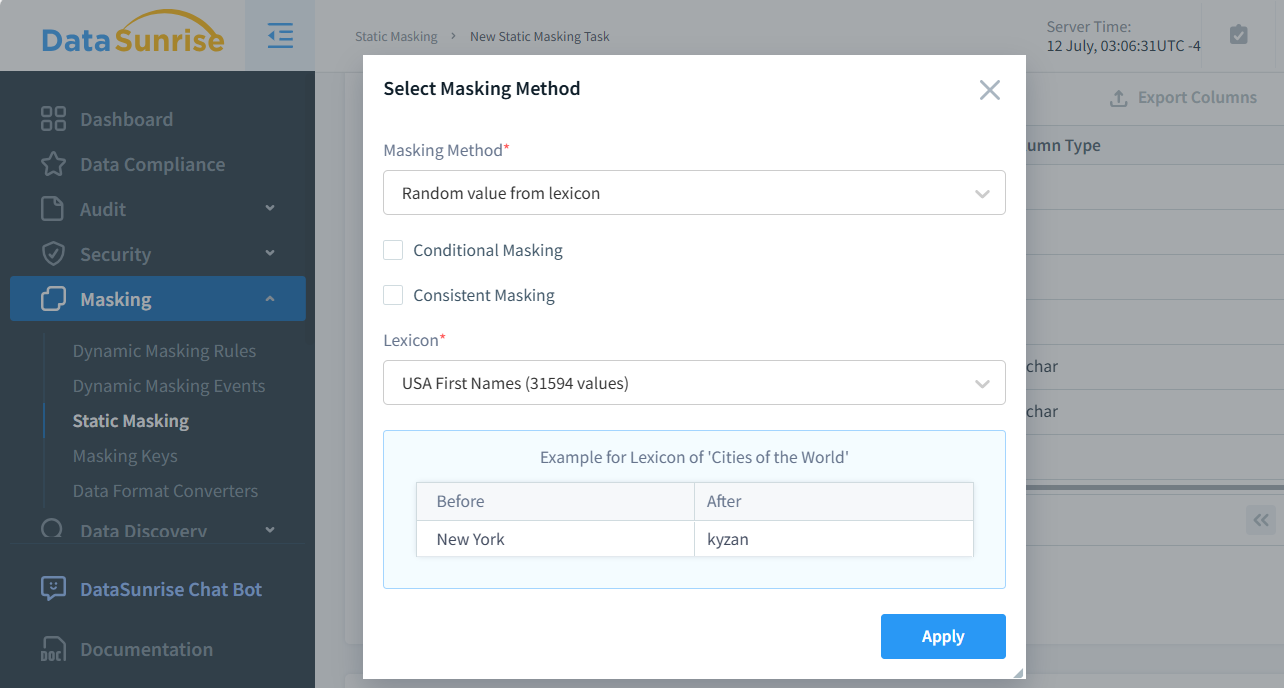
Comme mentionné dans l’introduction, DataSunrise vous permet de créer une sélection aléatoire de valeurs basée sur des lexiques pour le masquage. La figure ci-dessous montre la sélection de cette méthode de masquage dans l’interface utilisateur de DataSunrise. Comme vous pouvez le voir, 31 594 valeurs sont disponibles, ce qui est beaucoup plus fiable que le simple mélange d’un ensemble donné. Cette fiabilité accrue est due au fait que, lorsqu’il y a n valeurs uniques dans une colonne, la probabilité qu’une seule valeur soit mappée à elle-même est de 1/n.
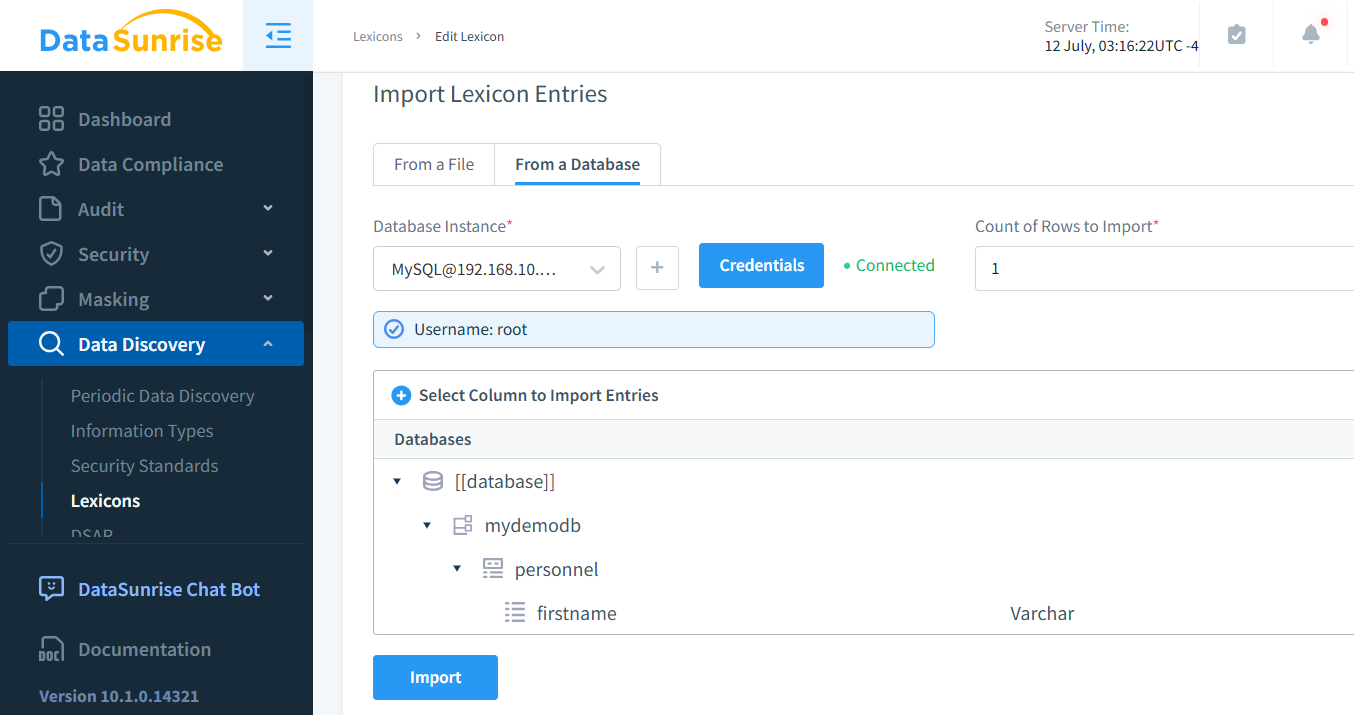
Si vous préférez mapper avec des valeurs existantes, vous pouvez facilement le faire en créant un lexique personnalisé. Cette approche est particulièrement bénéfique dans les situations où les valeurs mélangées ne sont pas des prénoms américains, car elle permet un masquage des données plus contextuellement approprié.
Comment Fonctionne le Mélange de Noms ?
Le processus est simple :
- Sélectionnez une colonne contenant des noms (prénoms, noms de famille, ou les deux).
- Réorganisez aléatoirement les valeurs dans cette colonne.
- Remplacez les valeurs originales par celles mélangées.
Cette technique conserve la distribution et les caractéristiques des données originales. Cependant, elle rompt le lien entre les individus et leurs informations.
Implémentation du Mélange de Noms en R et Python
Explorons comment implémenter le mélange de noms le plus simple dans deux langages de programmation populaires : Python et R.
Il est important de noter que le niveau d’utilisabilité offert par DataSunrise est inégalé dans ce contexte. Créer une solution flexible et tout-en-un avec seulement quelques lignes de code n’est pas réalisable en utilisant des langages de programmation standards. Notre objectif ici est de mettre en évidence les capacités des outils spécialisés comme DataSunrise par rapport aux langages de programmation généraux.
Mélange de Noms en Python
Python offre des moyens simples et efficaces pour mélanger les données. Voici un exemple utilisant pandas, une bibliothèque puissante de manipulation de données :
import pandas as pd
import numpy as np
# Créer un ensemble de données d'exemple
data = pd.DataFrame({
'FirstName': ['John', 'Alice', 'Bob', 'Emma', 'David'],
'LastName': ['Smith', 'Johnson', 'Williams', 'Brown', 'Jones'],
'Age': [32, 28, 45, 36, 51],
'Salary': [50000, 60000, 75000, 65000, 80000]
})
# Mélanger la colonne FirstName
data['FirstName'] = np.random.permutation(data['FirstName'])
# Mélanger la colonne LastName
data['LastName'] = np.random.permutation(data['LastName'])
print(data)Ce script crée un ensemble de données d’exemple et mélange les colonnes FirstName et LastName. Le résultat maintient les noms originaux mais en randomise l’ordre, masquant ainsi efficacement les identités individuelles.
Mélange de Noms en R
R propose également des méthodes simples pour mélanger les données. Voici un exemple :
# Créer un ensemble de données d'exemple
data <- data.frame(
FirstName = c("John", "Alice", "Bob", "Emma", "David"),
LastName = c("Smith", "Johnson", "Williams", "Brown", "Jones"),
Age = c(32, 28, 45, 36, 51),
Salary = c(50000, 60000, 75000, 65000, 80000)
)
# Mélanger la colonne FirstName
data$FirstName <- sample(data$FirstName)
# Mélanger la colonne LastName
data$LastName <- sample(data$LastName)
print(data)Ce script R obtient le même résultat que l'exemple Python. Il mélange les colonnes FirstName et LastName, préservant l'intégrité des données tout en masquant les identités individuelles.
Avantages du Mélange de Noms
Le mélange de noms offre plusieurs avantages :
- Maintient le réalisme des données : Les données mélangées conservent les caractéristiques de l'ensemble de données original.
- Préserve la distribution des données : La fréquence des noms reste la même, utile pour l'analyse statistique.
- Implémentation simple : C'est facile à appliquer et à comprendre.
- Réversible : Si nécessaire, le processus peut être inversé avec la bonne clé.
Défis et Considérations
Bien que le mélange de noms soit efficace, il est important de considérer :
- Unicité : Les noms rares peuvent encore être identifiables.
- Consistance : Assurez-vous que le mélange soit cohérent à travers les tables connexes.
- Informations contextuelles : D'autres champs de données peuvent encore révéler les identités.
Meilleures Pratiques pour le Mélange de Noms
Pour maximiser l'efficacité du mélange de noms :
- Utilisez de grands ensembles de données : Plus l'ensemble de données est grand, plus le mélange est efficace.
- Combinez les techniques : Utilisez le mélange de noms avec d'autres méthodes de masquage pour une meilleure protection.
- Application cohérente : Appliquez le mélange de manière cohérente à travers toutes les données connexes.
- Mises à jour régulières : Réalisez régulièrement des mélanges pour éviter le rétro-engagement.
Le Mélange de Noms dans la Création de Données de Test
Le mélange de noms est particulièrement utile dans la création de données de test. Il permet aux développeurs et testeurs de travailler avec des données réalistes sans compromettre leur confidentialité. Voici pourquoi c'est crucial :
- Tests réalistes : Les noms mélangés maintiennent les caractéristiques des données réelles.
- Conformité à la confidentialité : Il aide à respecter les réglementations de protection des données.
- Développement simplifié : Les développeurs peuvent utiliser des données qui imitent étroitement les environnements de production.
Conclusion
Le mélange de noms est une technique puissante de masquage de données. Il offre un équilibre entre utilisation des données et protection de la vie privée. En mettant en œuvre le mélange de noms, les organisations peuvent créer des données de test réalistes tout en protégeant les informations sensibles. Alors que les préoccupations concernant la confidentialité des données augmentent, des méthodes comme le mélange deviendront de plus en plus importantes dans la gestion des données.
Pour ceux qui recherchent des solutions avancées de masquage de données, DataSunrise offre des outils conviviaux et flexibles pour la sécurité des bases de données. Notre outil complet de masquage de données dynamique et statique comprend des capacités robustes de mélange et de cryptage. Visitez le site web de DataSunrise pour une démo en ligne et découvrez comment nos solutions peuvent améliorer vos stratégies de protection des données.
