
Classification des Données : Étape Cruciale dans l’Optimisation des Bases de Données

À l’ère numérique, les données sont la force motrice des entreprises, des organisations et même de nos vies personnelles. Nous créons et utilisons beaucoup d’informations chaque jour. Savoir comment prendre soin de cet actif précieux est important. Il est également important de le garder en sécurité. C’est là que la classification des données entre en jeu.
C’est le processus d’organisation des données en catégories en fonction de leur sensibilité, de leur valeur et de leur criticité. En mettant en œuvre un système de classification des données bien structuré, vous pouvez améliorer la sécurité des données, assurer la conformité aux réglementations et améliorer la gestion globale des données.
Nous explorerons les bases de la classification des données et fournirons des conseils utiles pour maximiser son potentiel.
Pourquoi la Classification des Données est Importante
Traiter toutes les données de manière égale peut entraîner des risques de sécurité et des inefficacités, car toutes les données ne sont pas créées égales. Voici pourquoi la classification est cruciale :
Sécurité Améliorée
En identifiant et en catégorisant les données sensibles, vous pouvez mettre en œuvre des mesures de sécurité appropriées pour les protéger contre l’accès non autorisé, les violations de données et les cybermenaces.
Conformité Réglementaire
De nombreuses industries doivent respecter des réglementations spécifiques qui régissent la manière dont elles manipulent les données, telles que le RGPD, HIPAA et PCI-DSS. La classification des données vous aide à vous conformer à ces réglementations en veillant à ce que vous identifiiez et protégiez correctement les données sensibles.
Gestion Améliorée des Données
Comprendre la sensibilité et la valeur de vos données vous aide à prendre des décisions éclairées. Vous pouvez décider comment les stocker, en contrôler l’accès et gérer leur cycle de vie.
Efficacité Accrue
La classification des données rationalise les processus de gestion des données, facilitant la localisation et la récupération des informations lorsque nécessaire.
Les Quatre Niveaux de Classification des Données
La plupart des organisations utilisent une approche en quatre niveaux, qui comprend :
Données Publiques
Vous pouvez partager librement ces informations avec n’importe qui, à la fois à l’intérieur et à l’extérieur de l’organisation. Des exemples incluent les communiqués de presse, les brochures sur les produits et le contenu des sites web publics.
Données Internes
Cette catégorie comprend des données réservées à l’usage interne et qui ne doivent pas être partagées avec des parties externes. Des exemples incluent les politiques de l’entreprise, les manuels des employés et les mémos internes.
Données Confidentielles
Seules les personnes autorisées sur une base de besoin de savoir doivent accéder à ces informations sensibles. Des exemples incluent les dossiers financiers, les données clients et la propriété intellectuelle.
Données Restreintes
C’est la catégorie de données la plus sensible, nécessitant le plus haut niveau de protection. Un accès non autorisé à ces données pourrait causer des dommages graves à l’organisation ou aux individus. Des exemples incluent les secrets commerciaux, les informations de santé personnelles et les documents gouvernementaux classifiés.
Mettre en Œuvre un Système de Classification des Données
Explorons maintenant comment mettre en œuvre un système de classification dans votre organisation.
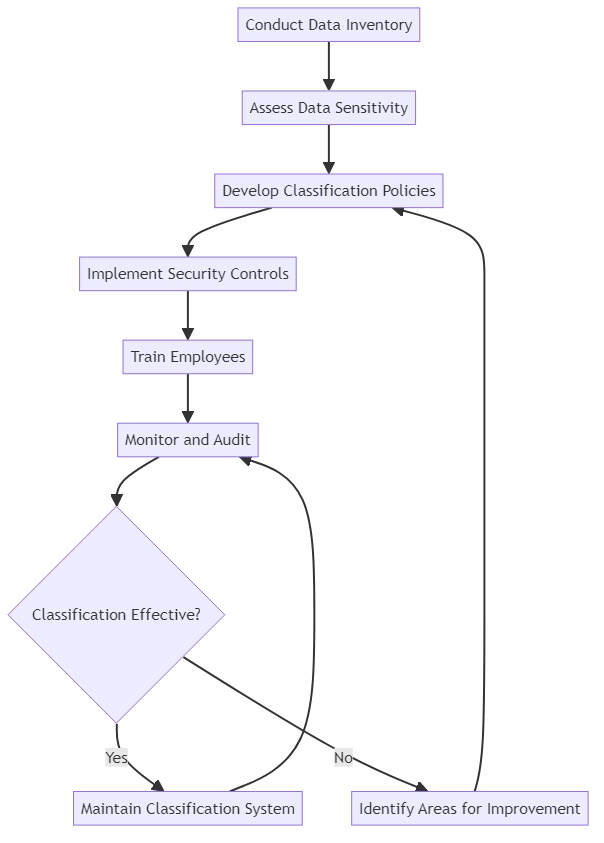
Effectuer un Inventaire des Données
Commencez par identifier et localiser toutes les données au sein de votre organisation. Cela inclut les données stockées sur les serveurs, les plateformes cloud, les appareils des employés et les documents physiques. Créez un inventaire complet des données qui répertorie tous les actifs de données, leurs emplacements et leurs propriétaires.
Évaluer la Sensibilité des Données
Une fois que vous avez un inventaire des données, évaluez la sensibilité de chaque actif de données. Tenez compte de facteurs tels que l’impact potentiel d’un accès non autorisé, les exigences réglementaires et la valeur des données pour l’organisation. Attribuez un niveau de classification à chaque actif de données en fonction de sa sensibilité.
Développer des Politiques de Classification
Créez des politiques de classification claires et concises qui définissent les critères pour chaque niveau, ainsi que les mesures de sécurité et les contrôles d’accès correspondants. Ces politiques doivent être facilement compréhensibles et communiquées à tous les employés.
Mettre en Œuvre des Contrôles de Sécurité
En fonction du niveau de classification de chaque actif de données, mettez en œuvre des contrôles de sécurité appropriés. Cela peut inclure le chiffrement, le contrôle d’accès, la surveillance et les outils de prévention des pertes de données (DLP). Assurez-vous de revoir et de mettre à jour régulièrement ces contrôles pour suivre l’évolution des menaces et des réglementations.
Former les Employés
Éduquez vos employés sur l’importance de la classification des données et leur rôle dans le maintien de la sécurité des données. Offrez des sessions de formation régulières pour vous assurer que chacun comprend les politiques de classification et sait comment manipuler correctement les données.
Surveiller et Auditer
Surveillez en continu votre système de classification des données pour garantir qu’il reste efficace et à jour. Effectuez des audits réguliers pour identifier toute lacune ou zone d’amélioration. Soyez prêt à adapter vos politiques de classification au fur et à mesure que l’écosystème de données de votre organisation évolue.
Exemples Pratiques
Pour mieux comprendre les applications pratiques, examinons quelques exemples concrets :
- Dans le secteur de la santé, les réglementations telles que HIPAA protègent les données des patients hautement sensibles. En étiquetant les données des patients comme “restreintes”, les organisations de santé peuvent s’assurer que seul le personnel médical autorisé peut les voir. Cela aide à prévenir les violations de données et à maintenir la confidentialité des informations des patients.
- E-commerce : Les détaillants en ligne collectent une grande quantité de données clients, y compris des informations personnelles, des historiques d’achats et des détails de paiement. Les entreprises de commerce électronique peuvent protéger les données des clients en les étiquetant comme “confidentielles” et en utilisant des mesures de sécurité robustes. Cela aide à établir la confiance dans leur marque.
- Éducation : Les institutions éducatives manipulent une variété de données sensibles, y compris les dossiers des étudiants, les informations d’aide financière et les données de recherche. Les universités et les écoles peuvent protéger la vie privée des étudiants et la propriété intellectuelle en organisant les données en fonction de leur sensibilité et en utilisant les contrôles d’accès appropriés.
Surmonter les Défis de la Classification des Données
Bien que la classification soit essentielle, elle n’est pas sans défis. Certains obstacles courants incluent :
- Volume de Données : Avec la croissance exponentielle des données, les classer et les gérer peut être une tâche ardue. Les outils automatisés et l’apprentissage automatique peuvent aider à classer les données plus rapidement. Cela est particulièrement utile à mesure que le volume de données continue d’augmenter.
- Consistance : Assurer une classification uniforme à travers une organisation peut être difficile, surtout si différents départements ont des pratiques de gestion des données différentes. Établir des politiques claires et fournir une formation régulière peut aider à maintenir la cohérence.
- Adoption par les Utilisateurs : Les employés peuvent résister au changement ou trouver les politiques de classification contraignantes. Pour créer une culture de la sécurité des données, incluez les employés dans le processus de classification. Fournissez des outils conviviaux pour la classification. Expliquez les avantages de la classification à tout le monde.
Conclusion
La classification des données est un outil essentiel pour protéger les actifs de données précieux. En reconnaissant l’importance de la classification et en mettant en place un système bien organisé, vous pouvez améliorer la sécurité des données. Cela aide à assurer la conformité aux réglementations et à améliorer la gestion globale des données. Pour atteindre ces avantages, il est crucial de suivre les meilleures pratiques lors de la classification de vos données.
Rappelez-vous, la classification des données n’est pas un projet ponctuel, mais un processus continu. Au fur et à mesure que votre écosystème de données évolue, vos politiques et pratiques de classification doivent également évoluer. Pour libérer tout le potentiel de vos données et les garder en sécurité, restez vigilant et adaptez-vous aux nouveaux défis.
Commencez par évaluer vos données, développer des politiques de classification et former votre équipe. Vous serez bien équipé pour naviguer dans le monde complexe de la gestion et de la sécurité des données.
Suivant
