
Comment auditer Apache Hive

Introduction
Apache Hive est largement utilisé par de nombreuses organisations pour traiter et analyser d’immenses quantités de données structurées stockées dans Hadoop. Avec l’augmentation du volume de données sensibles traitées via Hive, la mise en œuvre de mécanismes d’audit efficaces devient essentielle non seulement pour la sécurité mais aussi pour la conformité réglementaire.
Ce guide vous accompagne dans le processus de mise en place et de configuration des capacités d’audit pour Apache Hive, allant des fonctionnalités d’audit natives aux solutions améliorées avec DataSunrise, vous assurant ainsi la visibilité nécessaire pour surveiller l’accès aux données, détecter les activités non autorisées et maintenir la conformité.
Comment auditer Apache Hive à l’aide des capacités natives
Apache Hive offre plusieurs mécanismes intégrés pour l’audit que l’on peut configurer afin de suivre les activités des utilisateurs et les opérations effectuées sur les données. Explorons comment configurer ces capacités d’audit natives :
Étape 1 : Activer l’autorisation basée sur les normes SQL
L’autorisation basée sur les normes SQL dans Hive fournit un modèle de contrôle d’accès basé sur les rôles qui inclut des fonctionnalités d’audit de base. Ce modèle enregistre les opérations et les changements de privilèges effectués par les utilisateurs.
Pour activer l’autorisation basée sur les normes SQL, modifiez votre fichier de configuration hive-site.xml :
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
Après avoir effectué ces modifications, redémarrez les services Hive pour appliquer la configuration.
Étape 2 : Configurer le système de journalisation
Apache Hive utilise Log4j pour consigner les événements, lequel peut être configuré pour capturer les informations d’audit. Pour améliorer la journalisation des audits, modifiez le fichier hive-log4j2.properties :
# Journalisation de l'audit Hive
appender.AUDIT.type = RollingFile
appender.AUDIT.name = AUDIT
appender.AUDIT.fileName = ${sys:hive.log.dir}/${sys:hive.log.file}.audit
appender.AUDIT.filePattern = ${sys:hive.log.dir}/${sys:hive.log.file}.audit.%d{yyyy-MM-dd}
appender.AUDIT.layout.type = PatternLayout
appender.AUDIT.layout.pattern = %d{ISO8601} %p %c: %m%n
appender.AUDIT.policies.type = Policies
appender.AUDIT.policies.time.type = TimeBasedTriggeringPolicy
appender.AUDIT.policies.time.interval = 1
appender.AUDIT.policies.time.modulate = true
appender.AUDIT.strategy.type = DefaultRolloverStrategy
appender.AUDIT.strategy.max = 30
# Journal d'audit
logger.audit.name = org.apache.hadoop.hive.ql.audit
logger.audit.level = INFO
logger.audit.additivity = false
logger.audit.appenderRef.audit.ref = AUDIT
Ces paramètres créent un fichier de journal d’audit dédié qui capture tous les événements d’audit dans un format structuré.
Étape 3 : Activer les journaux d’audit HDFS
Puisque les opérations Hive impliquent en fin de compte des opérations HDFS, l’activation des journaux d’audit HDFS fournit une couche supplémentaire d’audit. Modifiez le fichier hdfs-site.xml :
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.audit.log.async</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.audit.log.debug.cmdlist</name>
<value>open,create,delete,append,rename</value>
</property>
Redémarrez les services HDFS pour appliquer ces modifications.
Étape 4 : Tester la journalisation d’audit
Pour vérifier que l’audit fonctionne correctement, effectuez diverses opérations Hive et vérifiez les journaux d’audit :
-- Créer une base de données de test
CREATE DATABASE audit_test;
-- Créer une table
USE audit_test;
CREATE TABLE employee (
id INT,
name STRING,
salary FLOAT
);
-- Insérer des données
INSERT INTO employee VALUES (1, 'John Doe', 75000.00);
INSERT INTO employee VALUES (2, 'Jane Smith', 85000.00);
-- Interroger les données
SELECT * FROM employee WHERE salary > 80000;
-- Mettre à jour les données
UPDATE employee SET salary = 90000.00 WHERE id = 1;
-- Supprimer la table
DROP TABLE employee;
Après avoir exécuté ces opérations, vérifiez les journaux d’audit pour vous assurer qu’ils enregistrent toutes les activités :
cat ${HIVE_LOG_DIR}/hive.log.audit

Étape 5 : Intégrer Apache Ranger (optionnel)
Pour des capacités d’audit plus complètes, intégrez Apache Hive avec Apache Ranger. Ranger offre une administration centralisée de la sécurité et des journaux d’audit détaillés pour les composants Hadoop.
Installez Apache Ranger en utilisant le guide d’installation officiel.
Configurez le plugin Ranger pour Hive en modifiant
hive-site.xml:
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value>
</property>
- Configurez les paramètres d’audit Ranger dans
ranger-hive-audit.xml:
<property>
<name>xasecure.audit.is.enabled</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db</name>
<value>true</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.driver</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>xasecure.audit.destination.db.jdbc.url</name>
<value>jdbc:postgresql://ranger-db:5432/ranger</value>
</property>
Limitations de l’audit natif
Bien que ces mécanismes d’audit natifs offrent des fonctionnalités de base, ils présentent plusieurs limitations :
- Données d’audit fragmentées : Les informations d’audit sont dispersées sur plusieurs fichiers journaux et systèmes.
- Configuration complexe : La mise en place d’un audit complet nécessite la configuration de plusieurs composants.
- Outils de surveillance limités : Les journaux d’audit natifs manquent d’interfaces conviviales pour l’analyse.
- Rapports de conformité manuels : La génération de rapports de conformité nécessite des scripts personnalisés ou une extraction manuelle.
- Consommateur de ressources : Un audit intensif peut impacter les performances dans des environnements à fort volume.
Comment auditer Apache Hive efficacement avec DataSunrise
Pour les organisations qui nécessitent des solutions d’audit plus complètes, DataSunrise offre des capacités avancées qui répondent aux limitations de l’audit natif de Hive. Explorons comment configurer DataSunrise pour auditer Apache Hive :
Étape 1 : Déployer DataSunrise
Commencez par déployer DataSunrise dans votre environnement. DataSunrise propose des options de déploiement flexibles incluant des configurations sur site, cloud et hybrides.
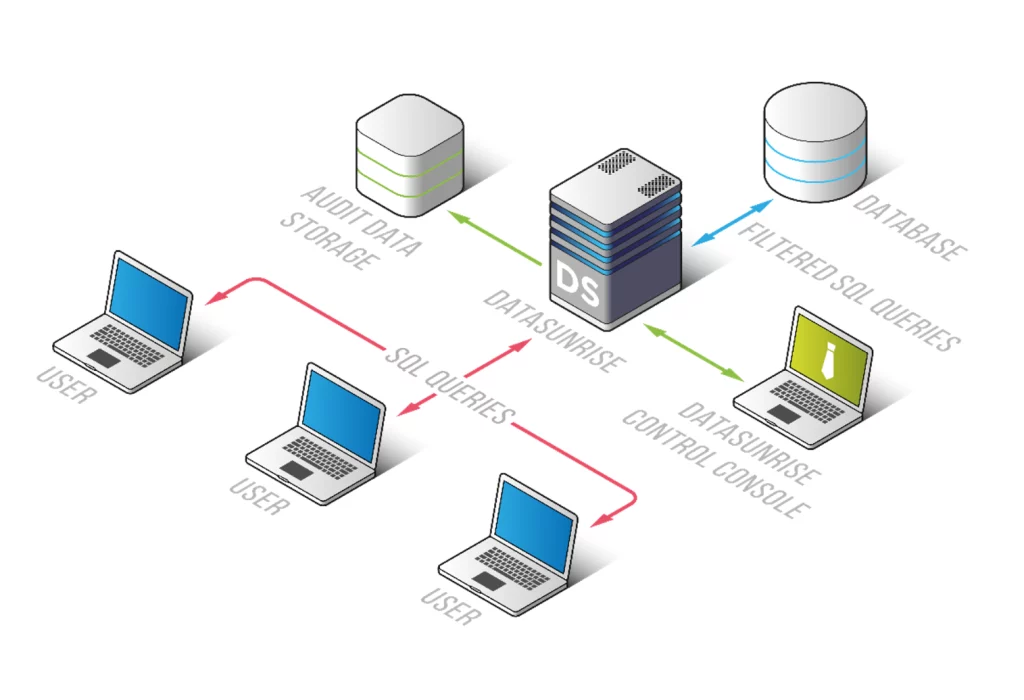
Étape 2 : Se connecter à Apache Hive
Une fois DataSunrise déployé, connectez-le à votre environnement Apache Hive :
- Accédez à la console de gestion de DataSunrise.
- Allez dans « Bases de données » et sélectionnez « Ajouter une base de données ».
- Sélectionnez « Apache Hive » comme type de base de données.
- Saisissez les détails de connexion pour votre instance Hive, y compris l’hôte, le port et les identifiants d’authentification.
- Testez la connexion pour vous assurer qu’elle est correctement configurée.

Étape 3 : Configurer les règles d’audit
Créez des règles d’audit pour définir quelles activités doivent être surveillées :
- Allez dans « Règles » et sélectionnez « Ajouter une règle ».
- Choisissez « Audit » comme type de règle.
- Configurez les paramètres de la règle, notamment :
- Nom et description de la règle
- Objets cibles (bases de données, tables, vues)
- Utilisateurs et rôles à surveiller
- Types d’opérations à auditer (SELECT, INSERT, UPDATE, DELETE, etc.)
- Conditions basées sur le temps (si nécessaire)
- Enregistrez et activez la règle.

Étape 4 : Tester et valider l’audit
Effectuez diverses opérations Hive pour valider que DataSunrise audite correctement les activités :
- Exécutez les mêmes requêtes de test utilisées précédemment pour valider l’audit natif.
- Accédez à la section « Journal d’audit » dans DataSunrise pour consulter les événements d’audit capturés.
- Vérifiez que toutes les opérations sont correctement enregistrées avec des informations détaillées comprenant :
- Identité de l’utilisateur
- Horodatage
- Requête SQL
- Type d’opération
- Objets affectés
- Adresse IP source

Conclusion
Un audit efficace d’Apache Hive est essentiel pour maintenir la sécurité, assurer la conformité et obtenir une visibilité sur les schémas d’accès aux données. Alors que les capacités d’audit natives de Hive offrent des fonctionnalités de base, les organisations ayant des besoins avancés bénéficient de solutions complètes comme DataSunrise.
DataSunrise améliore l’audit d’Apache Hive grâce à une gestion centralisée, des pistes d’audit détaillées, des alertes en temps réel et des rapports de conformité automatisés. En mettant en place une solution d’audit robuste, les organisations peuvent protéger leurs données sensibles, maintenir la conformité réglementaire et répondre rapidement aux incidents de sécurité.
Prêt à améliorer vos capacités d’audit d’Apache Hive ? Planifiez une démonstration pour voir comment DataSunrise peut vous aider à implémenter un audit complet pour votre environnement Hive.
