
Données de Cluster : Comment Elles Fonctionnent & Comment Les Utiliser

Les données de cluster sont une technique puissante qui aide à révéler des motifs et tendances cachés dans de grands ensembles de données. Elles regroupent des objets similaires, ce qui facilite l’analyse et la compréhension des informations complexes. Les scientifiques des données utilisent le clustering pour identifier rapidement des thèmes, détecter des anomalies et tirer des informations précieuses de quantités massives de données.
Qu’est-ce que le Clustering de Données?
À sa base, le clustering des données est une méthode d’apprentissage automatique non supervisé. Elle ne nécessite pas de données étiquetées ou de catégories pré-définies. Au lieu de cela, l’algorithme trouve des groupements naturels au sein de l’ensemble de données basé sur la similarité. Nous mettons des objets similaires dans le même groupe et séparons les objets différents.
Le processus est flexible et peut fonctionner avec différents types de données :
- Documents
- Points sur un graphique
- Réponses à des enquêtes
- Séquences génétiques
Tant qu’il y a un moyen de mesurer la similarité entre deux objets, le clustering peut être appliqué. Cette diversité en fait un outil incontournable pour l’analyse exploratoire de données dans de nombreux secteurs.
Analyse des Clusters de Données en Action
Imaginez que vous dirigez un site de commerce électronique avec des milliers de produits. Vous voulez mieux comprendre le comportement des clients et personnaliser les recommandations. En clusterisant vos données de produits, vous pourriez découvrir des groupes intéressants :
- Meilleures ventes souvent achetées ensemble
- Articles de niche attirant des démographies spécifiques
- Tendances saisonnières autour des vacances ou des événements
Ces informations peuvent influencer les stratégies marketing, la gestion des stocks et la conception de votre site web. Vous pouvez mettre en avant des ensembles de produits populaires, adapter les campagnes par e-mail aux segments de clientèle, et optimiser la navigation en fonction des modèles de navigation.
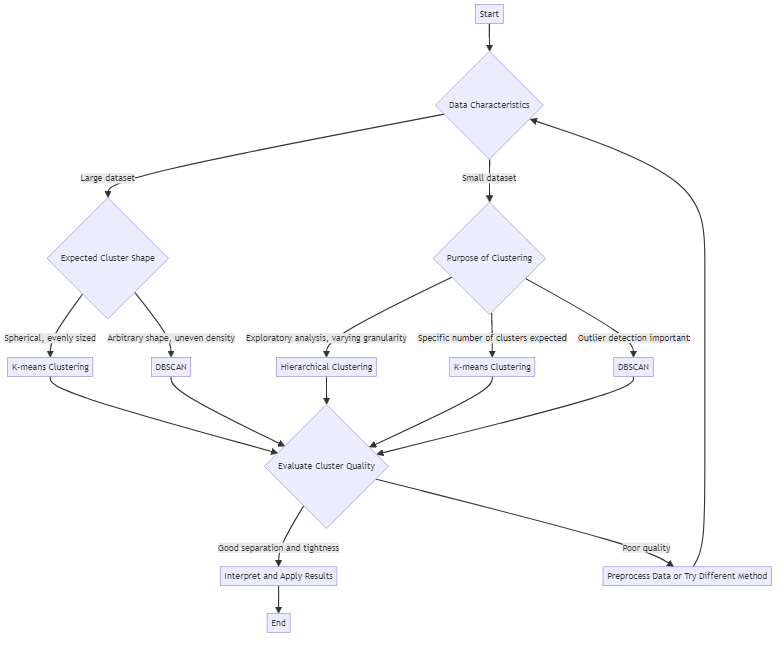
Choisir le Bon Algorithme de Clustering
Différents algorithmes de clustering conviennent à différents objectifs. Parmi les plus courants, on trouve :
- K-means : Divise les données en un nombre prédéfini (k) de clusters. Fonctionne bien lorsque vous avez une idée du nombre de groupes à attendre.
- Clustering hiérarchique : Construit des clusters imbriqués dans une structure arborescente. Utile pour visualiser les données à différents niveaux de granularité.
- DBSCAN : Identifie les clusters de forme arbitraire et marque les points aberrants. Gère les ensembles de données avec bruit et densité inégale.
Le choix dépend de facteurs comme la taille des données, la forme attendue des clusters, et la tolérance aux points aberrants. Essayer plusieurs approches vaut souvent la peine pour voir laquelle produit les résultats les plus significatifs.
Évaluer la Qualité des Clusters de Données
Les clusters ne sont pas tous égaux. Un bon résultat de clustering a des groupes serrés et bien séparés. Les objets au sein d’un cluster doivent être très similaires, tandis que les objets dans différents clusters devraient être distincts. Les scores de silhouette et les techniques de visualisation peuvent aider à évaluer la qualité des clusters.
Valider les clusters par rapport aux connaissances du domaine est crucial pour garantir l’exactitude et la pertinence des résultats du clustering. Nous pouvons voir si les clusters s’alignent avec les avis des experts ou les objectifs commerciaux. Cela nous aide à déterminer s’ils sont adaptés à un domaine ou une industrie spécifique. Ce processus de validation aide à confirmer que les clusters sont significatifs et utiles pour la prise de décision.
Le clustering aide à trouver des motifs dans les données, mais ce n’est que le début. Les humains doivent interpréter les résultats du clustering pour en extraire des informations exploitables et prendre des décisions éclairées. En utilisant à la fois les chiffres et les avis d’experts, nous pouvons mieux comprendre les données et comment elles affectent l’entreprise.
En résumé, valider les clusters par rapport aux connaissances du domaine et interpréter les résultats sont des étapes essentielles du processus de clustering. Nous nous assurons que les groupes sont utiles et pratiques en utilisant les connaissances et le jugement dans un domaine spécifique. Cela contribuera en fin de compte au succès de l’entreprise.
Applications des Données de Cluster
Les cas d’utilisation des données de cluster couvrent divers domaines :
- Segmentation de la clientèle pour le marketing ciblé
- Détection d’anomalies dans la prévention des fraudes
- Compression d’images et reconnaissance de motifs
- Bioinformatique et analyse de l’expression génétique
- Analyse des réseaux sociaux et détection de communautés
Partout où il y a des données complexes à démêler, le clustering fournit un point de départ précieux. Il simplifie le paysage des données et met en lumière des structures clés pour une investigation plus approfondie.
Meilleures Pratiques pour les Données de Cluster
Pour tirer le meilleur parti des données de cluster, gardez ces conseils à l’esprit :
- Prétraiter et normaliser les données pour assurer des comparaisons équitables
- Expérimenter avec différents métriques de distance et algorithmes
- Valider les résultats à l’aide de mesures statistiques et des connaissances du domaine
- Visualiser les clusters de données pour communiquer efficacement les aperçus
- Itérer et affiner le processus à mesure que de nouvelles données deviennent disponibles
Avec une mise en œuvre appropriée, les données de cluster peuvent changer la donne. Elles transforment des ensembles de données écrasants en intelligence exploitable, permettant aux organisations de prendre des décisions plus judicieuses.
Mettre en Œuvre les Données de Cluster
Déverrouillez la puissance de vos données avec le clustering. L’analyse des clusters est un outil crucial pour les marketeurs, les chercheurs et les scientifiques des données. Elle vous aide à obtenir des aperçus des clients, à explorer les réseaux de gènes et à résoudre des problèmes complexes. Commencez à explorer le monde du clustering de données et découvrez des motifs cachés dès aujourd’hui.
