
Données indésirables

Dans le monde axé sur les données d’aujourd’hui, la qualité de l’information joue un rôle crucial dans les processus de prise de décision. Cependant, les organisations sont souvent confrontées au défi des données indésirables car toutes les données ne sont pas suffisantes. Cet article examine ce type de traitement des données, comment il impacte les ensembles de données. Nous proposons également des solutions pour maintenir l’exactitude des données.
Qu’est-ce que les données indésirables ?
Les données indésirables se réfèrent à des informations inexactes, incomplètes, non pertinentes ou corrompues dans un ensemble de données. Elles peuvent également contenir des erreurs humaines. Ces données peuvent prendre diverses formes, telles que :
- Entrées en double
- Informations obsolètes
- Erreurs de formatage
- Enregistrements incomplets
- Points de données non pertinents
Ces données peuvent rendre l’analyse des données moins efficace et entraîner des informations incorrectes si elles ne sont pas corrigées.
L’impact des données indésirables sur l’analyse des données
Les données indésirables peuvent avoir des conséquences considérables sur le processus d’analyse des données. Voici quelques moyens clés par lesquels elles affectent l’intégrité et l’utilité de vos données :
1. Résultats biaisés
Lorsque des données trompeuses sont présentes dans un ensemble de données, elles peuvent entraîner des calculs statistiques inexacts et des tendances mal représentées. Ce biais des résultats peut pousser les organisations à prendre de mauvaises décisions basées sur des informations erronées.
2. Réduction de l’efficacité
Le traitement et l’analyse des données consomment un temps précieux et des ressources. Les analystes de données peuvent passer des heures à nettoyer et à trier des informations non pertinentes, réduisant ainsi la productivité globale.
3. Coûts accrus
La présence de données en double nécessite souvent un espace de stockage supplémentaire et une puissance de traitement supplémentaire. Cela peut entraîner une augmentation des coûts d’infrastructure pour les organisations traitant de grands volumes de données.
4. Perte de crédibilité
Les informations issues de données erronées peuvent miner la confiance dans les processus de prise de décision d’une organisation. Cette perte de crédibilité peut avoir des effets durables sur les opérations internes et les relations externes.
Approches de classification des données utilisant des outils open-source
Pour gérer efficacement les données indésirables, les organisations peuvent mettre en œuvre différentes approches de classification des données. Voici quelques outils open-source qui peuvent aider dans ce processus :
1. Apache NiFi
Apache NiFi est un outil puissant d’intégration et de traitement des données qui peut aider à classifier et à acheminer les données en fonction de règles prédéfinies. Il offre une interface conviviale pour créer des flux de données et appliquer des filtres permettant d’identifier et de séparer les données indésirables.
Exemple :
Flux de classification des données Apache NiFi
- Créer un nouveau groupe de processus
- Ajouter un processeur GetFile pour ingérer des données
- Connectez-le à un processeur RouteOnAttribute
- Définir des règles pour classer les données (par exemple, ${filename:contains(‘junk’)})
- Orienter les données classées vers les destinations appropriées
Résultat : Cette configuration classera automatiquement les fichiers entrants en fonction de leurs attributs et les acheminera en conséquence. Elle permet d’isoler les données potentiellement indésirables pour un traitement ou une suppression ultérieurs.
2. OpenRefine
OpenRefine (anciennement Google Refine) est un outil polyvalent pour le nettoyage et la transformation de données désordonnées. Il offre des fonctionnalités pour détecter et supprimer les entrées en double, standardiser les formats et regrouper des points de données similaires.
Exemple :
Détection de doublons avec OpenRefine
- Charger votre ensemble de données dans OpenRefine
- Sélectionner la colonne contenant des doublons potentiels
- Choisir “Facet” > “Customized facets” > “Duplicates facet”
- Examiner et fusionner ou supprimer les entrées en double
Résultat : Ce processus identifiera les enregistrements en double dans votre ensemble de données, vous permettant de nettoyer les informations redondantes.
3. Talend Open Studio
Talend Open Studio (retiré) est une plateforme open-source d’intégration de données qui inclut des outils puissants de qualité et de profilage des données. Elle peut aider à identifier les motifs et les anomalies dans vos données.
Exemple :
Analyse de la qualité des données avec Talend
- Créer un nouveau travail dans Talend Open Studio
- Glisser et déposer un composant tFileInputDelimited pour lire vos données
- Le connecter à un composant tDataProfiler
- Configurer le profileur pour analyser des colonnes spécifiques
- Exécuter le travail et consulter le rapport de qualité des données
Résultat : Ce travail générera un rapport complet sur la qualité de vos données, mettant en évidence les problèmes potentiels de données indésirables tels que les valeurs manquantes, les valeurs aberrantes et les incohérences de format.
Éviter la suppression ou l’utilisation abusive des données sensibles
Lors du traitement des mauvaises données, il est crucial de s’assurer que les informations sensibles ne sont pas supprimées ou utilisées de manière abusive par inadvertance. Voici quelques meilleures pratiques à suivre :
1. Mettre en œuvre le masquage des données
Utilisez des techniques de masquage des données pour masquer les informations sensibles tout en préservant la structure globale des données. Cela permet une analyse sans exposer de détails confidentiels.
2. Établir des contrôles d’accès
Mettre en œuvre des contrôles d’accès stricts pour s’assurer que seules les personnes autorisées peuvent consulter et manipuler les données sensibles pendant la phase de traitement des données indésirables.
3. Maintenir des pistes d’audit
Conservez des journaux détaillés de toutes les activités de traitement des données, y compris qui a accédé aux données, quelles modifications ont été apportées et quand. Cela aide à suivre tout usage abusif potentiel ou suppression accidentelle d’informations importantes.
4. Utiliser des balises de classification des données
Appliquez des balises de classification à vos données, en marquant clairement les informations sensibles. Cela aide à identifier quelles données nécessitent un traitement particulier pendant le processus de suppression des données indésirables.
Exigences réglementaires pour le traitement des données indésirables
Plusieurs règlements et normes régissent la gestion des données, y compris le traitement des données indésirables. Certaines exigences clés sont illustrées dans le diagramme ci-dessous :
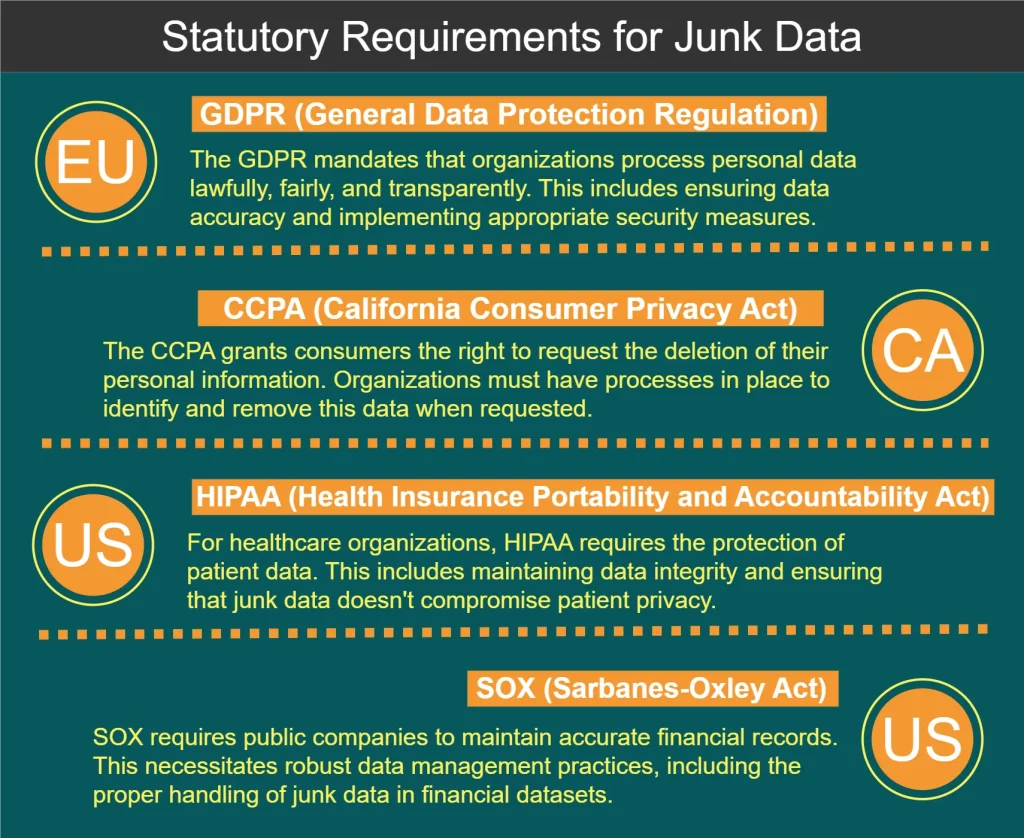
Meilleures pratiques pour le traitement des données indésirables
Pour gérer efficacement les données et maintenir l’intégrité des données, prenez en compte les meilleures pratiques suivantes :
- Mettre en œuvre la validation des données au point d’entrée pour empêcher les données indésirables de pénétrer dans vos systèmes.
- Auditer régulièrement vos ensembles de données pour identifier et traiter les problèmes de qualité des données.
- Développer une politique complète de gouvernance des données incluant des directives pour traiter les données indésirables.
- Investir dans la formation des employés afin de s’assurer que tous les membres de l’équipe comprennent l’importance de la qualité des données.
- Utiliser des outils automatisés pour rationaliser le processus d’identification et de suppression des données indésirables.
- Mettre en œuvre un système de notation de la qualité des données pour suivre les améliorations au fil du temps.
- Établir une boucle de rétroaction avec les utilisateurs de données pour identifier rapidement et traiter les problèmes de qualité des données.
À la fin de cet article, nous mentionnons également comment mettre en œuvre des méthodes simples de détection des données indésirables en Python.
Analyser les données et identifier les données indésirables en utilisant Python
Python est devenu un langage incontournable pour l’analyse des données en raison de sa simplicité, de sa polyvalence et de son écosystème robuste de bibliothèques centrées sur les données. Voici quelques façons d’analyser les données et d’identifier les données indésirables en utilisant Python :
1. Pandas pour la manipulation et l’analyse des données
Pandas est une bibliothèque puissante pour la manipulation et l’analyse des données en Python. Elle fournit des structures de données telles que les DataFrames, qui facilitent le travail avec des données structurées.
Exemple : Identifier les valeurs manquantes et les doublons
import pandas as pd
# Charger les données dans un DataFrame
df = pd.read_csv('votre_donnees.csv')
# Vérifier les valeurs manquantes
valeurs_manquantes = df.isnull().sum()
# Identifier les lignes en double
doublons = df.duplicated().sum()
print("Valeurs manquantes:\n", valeurs_manquantes)
print("Nombre de lignes en double:", doublons)Résultat : Ce script affichera le nombre de valeurs manquantes pour chaque colonne et le nombre total de lignes en double dans votre ensemble de données, vous aidant à identifier les éventuelles données indésirables.
2. Matplotlib et Seaborn pour la visualisation des données
La visualisation de vos données peut aider à identifier les valeurs aberrantes et les modèles inhabituels qui pourraient indiquer des données indésirables.
Exemple : Création d’un diagramme en boîte pour repérer les valeurs aberrantes
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Charger les données
df = pd.read_csv('votre_donnees.csv')
# Créer un diagramme en boîte
plt.figure(figsize=(10, 6))
sns.boxplot(x='categorie', y='valeur', data=df)
plt.title('Distribution des valeurs par catégorie')
plt.show()Résultat : Ceci générera un graphique en boîte qui représente visuellement la distribution des valeurs dans différentes catégories, facilitant le repérage des valeurs aberrantes qui pourraient être des données indésirables.
3. Scikit-learn pour la détection d’anomalies
Scikit-learn offre des algorithmes d’apprentissage automatique qui peuvent être utilisés pour la détection d’anomalies, aidant à identifier des points de données inhabituels qui pourraient être des données indésirables.
Exemple : Utilisation de l’Isolation Forest pour la détection d’anomalies
import pandas as pd
from sklearn.ensemble import IsolationForest
# Charger et préparer les données
df = pd.read_csv('votre_donnees.csv')
X = df[['feature1', 'feature2']] # Sélectionnez les caractéristiques pertinentes
# Créer et ajuster le modèle
iso_forest = IsolationForest(contamination=0.1, random_state=42)
outliers = iso_forest.fit_predict(X)
# Ajouter les résultats au DataFrame
df['is_outlier'] = outliers
# Visualiser les données potentiellement indésirables (outliers)
junk_data = df[df['is_outlier'] == -1]
print(junk_data)Résultat : Ce script utilisera l’algorithme Isolation Forest pour identifier les valeurs aberrantes potentielles dans votre ensemble de données, ce qui pourrait indiquer des données indésirables.
4. Fonctions personnalisées pour les vérifications de la qualité des données
Vous pouvez créer des fonctions Python personnalisées pour effectuer des contrôles spécifiques de la qualité des données adaptés à votre ensemble de données.
Exemple : Vérification des valeurs irréalistes dans un ensemble de données de température
import pandas as pd
def check_temperature_range(df, column, min_temp, max_temp):
"""Vérifiez si les valeurs de température sont dans une plage réaliste."""
outliers = df[(df[column] < min_temp) | (df[column] > max_temp)]
return outliers
# Charger les données
df = pd.read_csv('temperature_data.csv')
# Vérifiez les températures irréalistes (par exemple, en dessous de -100°C ou au-dessus de 60°C)
junk_temps = check_temperature_range(df, 'temperature', -100, 60)
print("Lectures de température potentiellement indésirables :")
print(junk_temps)Résultat : Cette fonction identifiera les lectures de température qui se situent en dehors d’une plage réaliste spécifiée, aidant à repérer les données potentiellement erronées ou indésirables.
5. Profilage des données avec ydata-profiling
La bibliothèque ydata-profiling (anciennement pandas-profiling) offre un moyen simple de générer des rapports complets sur votre ensemble de données, y compris les problèmes potentiels de qualité.
Exemple : Générer un rapport de profil de données
import pandas as pd
from ydata_profiling import ProfileReport
# Charger les données
df = pd.read_csv('votre_donnees.csv')
# Générer le rapport
profile = ProfileReport(df, title="Rapport de profil de données", explorative=True)
# Enregistrer le rapport dans un fichier
profile.to_file("rapport_de_profil_de_donnees.html")Résultat : Ce script générera un rapport HTML avec des statistiques détaillées, des visualisations et des problèmes de qualité potentiels dans votre ensemble de données, offrant une vue d’ensemble complète qui peut aider à identifier les données indésirables.
En incorporant ces techniques basées sur Python dans votre flux de travail d’analyse de données, vous pouvez identifier et traiter plus efficacement les problèmes de données indésirables, améliorant ainsi la qualité et la fiabilité globales de vos ensembles de données.
Conclusion : Le chemin vers une meilleure intégrité des données
Le traitement des données indésirables est un aspect critique du maintien de l’intégrité des données et de la garantie de la fiabilité de vos efforts d’analyse de données. En utilisant des méthodes de classification robustes, des outils gratuits et en suivant les règles, les organisations peuvent grandement améliorer la qualité de leurs données.
Rappelez-vous que le nettoyage des données est un effort continu qui nécessite une vigilance constante et une adaptation aux paysages de données en évolution. En donnant la priorité à la qualité des données et en mettant en œuvre des stratégies efficaces de traitement des données trompeuses, les organisations peuvent libérer le véritable potentiel de leurs données et prendre des décisions plus éclairées.
Pour des outils conviviaux et flexibles conçus pour améliorer la sécurité des données et garantir la conformité, envisagez d’explorer les offres de DataSunrise. Visitez notre site Web à DataSunrise.com pour une démonstration en ligne et découvrez comment nous pouvons vous aider à maintenir l’intégrité des données tout en répondant aux exigences réglementaires.
