
Amélioration de la Gestion et des Performances des Données avec la Segmentation des Données
Introduction
La prolifération des technologies numériques, des appareils de l’Internet des objets (IoT) et des interactions en ligne a créé d’énormes quantités de données qui peuvent être collectées et analysées. Dans le monde axé sur les données d’aujourd’hui, la gestion efficace des grands ensembles de données est primordiale pour les entreprises et les chercheurs. Une technique puissante qui a gagné en importance ces dernières années est la segmentation des données. Cet article plonge en profondeur dans le monde de la segmentation des données, explorant ses fondamentaux, ses avantages et ses applications pratiques. Nous examinerons également certains outils open-source et fournirons des exemples pour vous aider à démarrer avec cette technique essentielle de gestion des données.
Qu’est-ce que la Segmentation des Données ?
La segmentation des données est le processus de création d’une portion plus petite et plus gérable d’un ensemble de données plus large tout en conservant ses caractéristiques et relations clés. Cette technique permet aux utilisateurs de travailler avec un échantillon représentatif de données, rendant l’analyse et les tests plus faciles sans compromettre l’intégrité de l’ensemble de données original.
Pourquoi Vous Devriez Vous Intéresser à la Segmentation des Données ?
La segmentation des données devient de plus en plus cruciale à l’ère des big data. Voici pourquoi vous devriez prêter attention à cette technique :
- Gestion des Ensembles de Données Massifs : Les ensembles de données modernes peuvent être énormes. Par exemple, une plateforme de médias sociaux peut générer des pétaoctets de données quotidiennement. Travailler avec de telles quantités de données peut être impraticable ou impossible sans segmentation.
- Optimisation des Ressources : Le traitement de jeux de données complets nécessite souvent des ressources computationnelles importantes. La segmentation permet de travailler avec une fraction des données, économisant du temps et réduisant les besoins matériels.
- Réduction des Coûts : Les coûts de l’informatique en nuage et du stockage sont directement liés au volume des données. En travaillant avec des sous-ensembles, vous pouvez réduire considérablement ces dépenses.
- Cycles de Développement Plus Rapides (tests logiciels) : Dans le développement logiciel, l’utilisation des ensembles de données de production complets pour les tests peut ralentir le processus de développement. Les sous-ensembles permettent des itérations plus rapides et l’identification plus rapide des bogues.
- Conformité à la Confidentialité des Données : Avec des réglementations comme GDPR et CCPA, l’utilisation des ensembles de données complets contenant des informations sensibles pour les tests ou l’analyse peut être risquée. La segmentation aide à créer des ensembles de données anonymisés et conformes.
- Amélioration de la Qualité des Données : Les ensembles de données plus petits sont plus faciles à nettoyer et à valider, ce qui peut conduire à des données de meilleure qualité pour vos analyses ou modèles.
Quelle Peut être la Taille des Ensembles de Données ? Un Exemple du Monde Réel
Pour comprendre l’ampleur des ensembles de données modernes, considérons quelques exemples :
- Entrepôt de Données de Walmart : En 2019, l’entrepôt de données de Walmart était estimé à contenir plus de 2,5 pétaoctets de données. C’est l’équivalent de 167 fois tous les livres de la bibliothèque du Congrès des États-Unis.
- Données Utilisateurs de Facebook : Facebook traite plus de 500 téraoctets de données chaque jour. Cela comprend les publications des utilisateurs, les photos, les vidéos et les données d’interaction.
- Grand Collisionneur de Hadrons du CERN : Le LHC génère d’énormes quantités de données équivalentes à plus de 20 000 ans d’enregistrement vidéo HD 24h/24 et 7j/7.
- Données Génomiques : Le génome humain consiste en environ 3 milliards de paires de bases. Le séquençage et le stockage de ces données pour des millions d’individus créent des ensembles de données de l’ordre du pétaoctet.
- Sciences du Climat : Le Centre de simulation climatique de la NASA (NCCS) gère plus de 32 pétaoctets de données provenant de diverses missions scientifiques sur la Terre.
Pour mettre cela en perspective, 1 pétaoctet équivaut à 20 millions de classeurs à quatre tiroirs remplis de texte. Imaginez maintenant essayer d’analyser ou de traiter cette quantité de données dans son intégralité – c’est là que la segmentation des données devient inestimable.
Par exemple, si vous étiez un data scientist chez Walmart essayant d’analyser le comportement des clients, travailler avec les 2,5 pétaoctets complets serait impraticable. Au lieu de cela, vous pourriez créer un sous-ensemble de données pour une période spécifique, une région ou une catégorie de produits, peut-être en réduisant votre ensemble de données de travail à un plus gérable 50 gigaoctets.
Pourquoi la Segmentation des Données est-elle Utile ?
La segmentation des données offre de nombreux avantages aux professionnels des données et aux organisations :
- Amélioration des Performances : Travailler avec des ensembles de données plus petits réduit le temps de traitement et les exigences en ressources.
- Rentable : La segmentation peut réduire les coûts de stockage et de calcul associés aux big data.
- Tests Améliorés : Elle permet des tests plus rapides et plus efficaces des applications basées sur les données.
- Conformité à la Confidentialité : La segmentation aide à créer des ensembles de données anonymisés pour la conformité réglementaire.
- Analyse Simplifiée : Les ensembles de données plus petits sont plus faciles à explorer et à analyser, surtout au début d’un projet.
Applications Pratiques de la Segmentation
Examinons quelques scénarios concrets où la segmentation des données s’avère inestimable :
1. Développement et Tests de Logiciels
Les développeurs doivent souvent travailler avec des données réalistes pour tester des applications. Cependant, l’utilisation de jeux de données de production complets peut être impraticable et risquée. La segmentation permet de créer de plus petits ensembles de test représentatifs qui maintiennent la complexité des données du monde réel sans exposer d’informations sensibles.
2. Analyse et Exploration des Données
Lorsqu’il s’agit de jeux de données massifs, l’analyse exploratoire initiale des données peut être chronophage. En créant un sous-ensemble, les analystes peuvent rapidement obtenir des informations et tester des hypothèses avant de passer à l’ensemble de données complet.
3. Développement de Modèles de Machine Learning
Au cours des premières étapes du développement de modèles, les data scientists peuvent utiliser des sous-ensembles pour itérer rapidement sur différents algorithmes et hyperparamètres avant de s’entraîner sur l’ensemble de données complet.
4. Optimisation des Bases de Données
Les administrateurs de bases de données peuvent utiliser la segmentation pour créer des versions plus petites des bases de données de production pour les environnements de développement et de test, assurant des performances optimales sans la surcharge de gestion des répliques de grande taille.
Outils et Techniques pour la Segmentation des Données
Maintenant que nous comprenons l’importance de la segmentation des données, examinons quelques outils et techniques populaires pour la mettre en œuvre efficacement.
SQL pour la Segmentation des Données
Le SQL est un langage puissant pour la manipulation des données et est excellent pour segmenter les bases de données relationnelles. Voici un exemple de création d’un sous-ensemble de données en utilisant SQL :
-- Créer un sous-ensemble de données clients pour l'année 2023 CREATE TABLE client_subset_2023 AS SELECT * FROM clients WHERE EXTRACT(YEAR FROM order_date) = 2023 LIMIT 10000;
Cette requête crée une nouvelle table client_subset_2023 contenant jusqu’à 10 000 enregistrements de clients pour l’année 2023. Le résultat est un ensemble de données plus petit et plus gérable pour l’analyse ou les tests.
Python pour la Segmentation des Données
Avec son écosystème riche de bibliothèques de manipulation des données, Python offre des outils puissants pour la segmentation des données.
Avec Nyption des opérations de manipulation de données avancées.
Voici un exemple utilisant pandas :
import pandas as pd
import numpy as np
# Charger l'ensemble de données complet
full_dataset = pd.read_csv('large_dataset.csv')
# Créer un sous-ensemble basé sur une condition et un échantillonnage aléatoire
subset = full_dataset[full_dataset['category'] == 'electronics'].sample(n=1000, random_state=42)
# Enregistrer le sous-ensemble dans un nouveau fichier CSV
subset.to_csv('electronics_subset.csv', index=False)Ce script charge un grand ensemble de données, le filtre pour inclure uniquement les articles électroniques, puis prélève aléatoirement 1 000 lignes pour créer un sous-ensemble. Le résultat est enregistré sous forme de nouveau fichier CSV.
De plus, avec Pandas, vous pouvez filtrer les données avec des instructions telles que :
filtered_df_loc = df.loc[df['age'] > 25, ['name', 'city']]
ou
filtered_df = df[df['age'] > 25]
Filtrage des Données Basé sur des Conditions en R
R est un autre langage puissant pour la manipulation et l’analyse des données, largement utilisé en informatique statistique et en sciences des données. Alors que Python est souvent préféré pour l’apprentissage profond, R a de fortes capacités en apprentissage statistique et en apprentissage automatique traditionnel. Cela peut être avantageux lorsque la segmentation des données implique des approches basées sur des modèles ou lorsque vous devez analyser les propriétés statistiques de vos sous-ensembles.
Vous pouvez exécuter ce code dans Posit Cloud version de RStudio compte gratuit.
# Charger la bibliothèque nécessaire
library(dplyr)
# Supposons que nous ayons un grand ensemble de données appelé 'full_dataset'
# Pour cet exemple, nous créerons un ensemble de données échantillon
set.seed(123) # pour la reproductibilité
full_dataset <- data.frame(
id = 1:1000,
category = sample(c("A", "B", "C"), 1000, replace = TRUE),
value = rnorm(1000)
)
# Créer un sous-ensemble basé sur une condition et un échantillonnage aléatoire
subset_data <- full_dataset %>%
filter(category == "A") %>%
sample_n(100)
# Afficher les premières lignes du sous-ensemble
head(subset_data)
# Enregistrer le sous-ensemble dans un fichier CSV
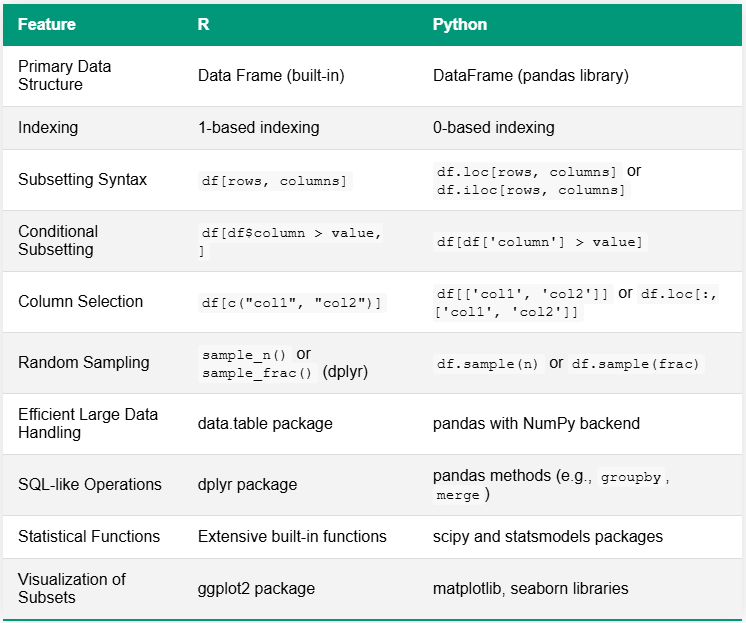
write.csv(subset_data, "category_A_subset.csv", row.names = FALSE)Le tableau ci-dessous compare R et Python pour les tâches de segmentation des données, mettant en évidence les différences clés de syntaxe et de fonctionnalité. Une distinction notable réside dans leurs écosystèmes : R a souvent des fonctions intégrées ou s’appuie sur quelques packages complets, tandis que Python utilise généralement une variété de bibliothèques spécialisées pour des capacités similaires.
Outils Open-Source pour la Segmentation des Données
Plusieurs outils open-source sont disponibles pour des besoins plus avancés :
- Jailer : Un outil de segmentation de base de données qui préserve l’intégrité référentielle.
- Benerator CE : Un cadre open-source pour la génération et la segmentation de données de test.
- Subsetter : Une bibliothèque Python pour la segmentation des bases de données relationnelles tout en maintenant l’intégrité référentielle.
Ces outils offrent des fonctionnalités plus sophistiquées comme le maintien de relations complexes entre les tables et la génération de données synthétiques pour compléter les sous-ensembles.
Meilleures Pratiques pour une Segmentation Efficace des Données
Pour tirer le meilleur parti de la segmentation des données, prenez en compte ces meilleures pratiques :
- Maintenir l’Intégrité des Données : Assurez-vous que votre sous-ensemble préserve les relations et les contraintes de l’ensemble de données original.
- Utiliser des Échantillons Représentatifs : Efforcez-vous de créer des sous-ensembles qui reflètent fidèlement les caractéristiques de l’ensemble de données complet.
- Prendre en Compte la Sensibilité des Données : Lors de la segmentation pour les tests ou le développement, soyez attentif aux informations sensibles et appliquez des techniques d’anonymisation appropriées.
- Documenter Votre Processus : Gardez des enregistrements clairs sur la manière dont les sous-ensembles ont été créés pour garantir la reproductibilité.
- Valider Vos Sous-ensembles : Vérifiez régulièrement que vos sous-ensembles représentent toujours fidèlement l’ensemble de données complet à mesure qu’il évolue.
Défis de la Segmentation des Données
Bien que ce traitement des données offre de nombreux avantages, il n’est pas sans défis :
- Maintenir les Relations entre les Données : Dans les bases de données complexes, préserver l’intégrité référentielle peut être difficile.
- Créer des Échantillons Représentatifs : Il peut être difficile de créer des sous-ensembles qui représentent fidèlement tous les aspects de l’ensemble de données complet.
- Gérer les Données Temporelles : Segmenter les données temporelles tout en préservant les motifs temporels nécessite une considération attentive.
- S’adapter aux Big Data : À mesure que les ensembles de données grandissent, même la création de sous-ensembles peut devenir intensivement computationnelle.
Conclusion
La segmentation des données est une technique puissante qui peut améliorer considérablement vos pratiques de gestion des données. En créant des ensembles de données plus petits et plus gérables, vous pouvez améliorer les performances, réduire les coûts et rationaliser vos processus de développement et de test. Que vous utilisiez SQL, Python ou des outils spécialisés, maîtriser la segmentation des données est une compétence essentielle pour tout professionnel des données.
Lorsque vous commencez votre parcours de segmentation des données, rappelez-vous que la clé du succès réside dans le maintien de l’intégrité des données, la garantie de représentativité et le choix des bons outils pour vos besoins spécifiques.
