
Générateur de Données IA

À mesure que les informations basées sur les données deviennent cruciales pour les entreprises de toutes tailles, la demande pour des jeux de données diversifiés et de haute qualité a explosé. Cependant, obtenir des données du monde réel peut être difficile, chronophage et souvent soulever des préoccupations en matière de confidentialité. C’est là que le générateur de données IA entre en jeu, offrant une solution puissante grâce à la génération de données synthétiques. Plongeons dans ce monde fascinant et voyons comment l’IA transforme le paysage de la création de données.
Étant donné que DataSunrise met en œuvre ses propres capacités de génération de données synthétiques riches en fonctionnalités et faciles à utiliser, nous allons approfondir ce sujet, en explorant en particulier les outils open-source disponibles aujourd’hui.
Comprendre les Données Synthétiques
Les données synthétiques sont des informations créées artificiellement qui imitent les caractéristiques et propriétés statistiques des données du monde réel. Elles sont générées en utilisant divers algorithmes et techniques d’IA, sans copier directement des points de données réels. Cette approche offre de nombreux avantages, en particulier dans les situations où les données réelles sont rares, sensibles ou difficiles à obtenir.
Le Besoin de Données Synthétiques
Surmonter la Pénurie de Données
L’une des principales raisons d’utiliser des données synthétiques est de surmonter la pénurie de données réelles. Dans de nombreux domaines, surtout ceux des technologies émergentes, il peut être difficile de rassembler suffisamment de données pour entraîner des modèles d’apprentissage automatique. Les générateurs de données IA peuvent produire de grandes quantités de données diversifiées, aidant ainsi à combler cette lacune.
Protéger la Confidentialité et la Sécurité
Avec les préoccupations croissantes concernant la confidentialité et la sécurité des données, les données synthétiques offrent une alternative sûre. Elles permettent aux organisations de travailler avec des données qui ressemblent de près à des informations réelles sans risquer de divulguer des données personnelles ou commerciales sensibles. Cela est particulièrement crucial dans des industries comme la santé et la finance, où la protection des données est primordiale.
Améliorer l’Entraînement des Modèles
Les données synthétiques peuvent être utilisées pour augmenter les ensembles de données existants, améliorant ainsi la performance et la robustesse des modèles d’apprentissage automatique. En générant des exemples supplémentaires et diversifiés, les modèles IA peuvent apprendre à gérer un plus large éventail de scénarios, menant à une meilleure généralisation.
Types de Données Synthétiques
Les générateurs de données IA peuvent produire divers types de données synthétiques :
1. Données Numériques
Cela inclut des valeurs continues comme des mesures, des chiffres financiers ou des lectures de capteurs. Les générateurs IA peuvent créer des données numériques aux propriétés statistiques spécifiques, telles que :
- Distribution de densité de probabilité
- Moyenne
- Variance
- Corrélation entre les variables
2. Données Catégorielles
Les données catégorielles représentent des catégories ou étiquettes discrètes. Les générateurs IA peuvent créer des données catégorielles synthétiques tout en maintenant la distribution et les relations trouvées dans les ensembles de données du monde réel.
3. Données Textuelles
Des phrases simples aux documents complexes, l’IA peut générer des données textuelles synthétiques. Cela est particulièrement utile pour les tâches de traitement du langage naturel et la génération de contenu.
4. Données d’Images
Les images générées par IA deviennent de plus en plus sophistiquées. Elles peuvent aller de formes géométriques simples à des images photoréalistes, utiles pour les applications de vision par ordinateur.
Mécanismes pour la Génération de Données Synthétiques
Plusieurs approches et techniques sont utilisées dans la génération de données IA :
Modélisation Statistique
Cette approche implique la création de modèles mathématiques capturant les propriétés statistiques des données réelles. Les données synthétiques sont ensuite générées pour correspondre à ces propriétés.
Génération Basée sur l’Apprentissage Automatique
Des techniques avancées d’apprentissage automatique, notamment les modèles génératifs, sont utilisées pour créer des données synthétiques hautement réalistes. Quelques méthodes populaires incluent :
- Réseaux Antagonistes Génératifs (GANs) : Ceux-ci impliquent deux réseaux neuronaux se concurrençant, avec l’un générant des données synthétiques et l’autre essayant de les distinguer des données réelles.
- Encodeurs-Decodeurs Variationnels (VAEs) : Ces modèles apprennent à encoder des données dans une représentation compressée puis à les décoder, générant ainsi de nouveaux échantillons de données.
- Modèles Transformer : Particulièrement efficaces pour la génération de texte, ces modèles ont révolutionné les tâches de traitement du langage naturel.
Génération Basée sur des Règles
Cette méthode implique la création de données synthétiques basées sur des règles et contraintes prédéfinies. Elle est souvent utilisée lorsque les données doivent suivre des motifs spécifiques ou une logique d’entreprise.
Outils Basés sur l’IA dans la Génération de Données de Test
L’IA joue un rôle crucial dans la génération de données de test pour le développement logiciel et l’assurance qualité. Ces outils peuvent créer des ensembles de données réalistes et diversifiés couvrant divers scénarios de test, aidant à déceler des problèmes potentiels et des cas limites.
Par exemple, un générateur de données de test basé sur l’IA pour une application de commerce électronique pourrait créer :
- Des profils d’utilisateurs avec diverses démographies
- Des catalogues de produits avec différents attributs
- Des historiques de commandes avec des motifs variés
Ces données de test synthétiques peuvent aider les développeurs et les équipes QA à assurer la robustesse et la fiabilité de leurs applications sans utiliser de données réelles de clients.
IA Générative dans la Création de Données
L’IA générative représente le nec plus ultra de la création de données synthétiques. Ces modèles peuvent produire des ensembles de données extrêmement réalistes et diversifiés à travers divers domaines. Quelques applications clés incluent :
- Synthèse d’images pour l’entraînement à la vision par ordinateur
- Génération de texte pour le traitement du langage naturel
- Synthèse vocale et parlée pour les applications audio
- Génération de données de séries temporelles pour la modélisation prédictive
Par exemple, un modèle d’IA générative entraîné sur des images médicales pourrait créer des radiographies ou des scanners IRM synthétiques, aidant les chercheurs à développer de nouveaux algorithmes de diagnostic sans compromettre la confidentialité des patients.
Outils et Bibliothèques pour la Génération de Données Synthétiques
Plusieurs outils et bibliothèques sont disponibles pour générer des données synthétiques. Une option populaire est la bibliothèque Python Faker. Contrairement aux outils plus complexes, elle ne repose pas sur l’apprentissage automatique ni sur des techniques liées à l’IA. Au lieu de cela, Faker utilise des approches classiques et robustes pour la génération de données.
Bibliothèque Python Faker
Faker est un package Python qui génère des données factices pour divers usages. Elle est particulièrement utile pour créer des données de test réalistes.
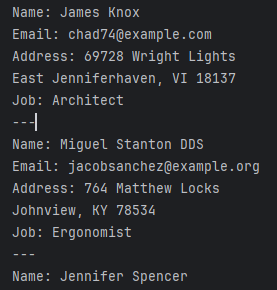
Voici un simple exemple d’utilisation de Faker pour générer des données d’utilisateur synthétiques :
from faker import Faker
fake = Faker()
# Générer 5 profils d'utilisateur factices
for _ in range(5):
print(f"Nom : {fake.name()}")
print(f"Email : {fake.email()}")
print(f"Adresse : {fake.address()}")
print(f"Emploi : {fake.job()}")
print("---")Ce script pourrait produire une sortie comme :
Bibliothèque CTGAN
CTGAN est une bibliothèque Python spécialement conçue pour générer des données tabulaires synthétiques en utilisant des Réseaux Antagonistes Génératifs (GANs). Elle fait partie du projet Synthetic Data Vault (SDV) et est bien adaptée pour créer des versions synthétiques de jeux de données structurés. CTGAN fonctionne beaucoup plus comme un générateur de données IA comparé à Faker.
Voici comment vous pouvez utiliser CTGAN en Python :
Voici un exemple basique d’utilisation de CTGAN (actuellement, le Readme recommande d’installer la bibliothèque SDV qui fournit des APIs conviviales pour accéder à CTGAN.) :
import pandas as pd
from ctgan import CTGAN
import numpy as np
# Créer un jeu de données échantillon
data = pd.DataFrame({
'age': np.random.randint(18, 90, 1000),
'income': np.random.randint(20000, 200000, 1000),
'education': np.random.choice(['High School', 'Bachelor', 'Master', 'PhD'], 1000),
'employed': np.random.choice(['Yes', 'No'], 1000)
})
print("Échantillon de Données Originales :")
print(data.head())
print("\nInfos sur les Données Originales :")
print(data.describe())
# Initialiser et ajuster le modèle CTGAN
ctgan = CTGAN(epochs=10) # Utilisation de moins d'époques pour cet exemple
ctgan.fit(data, discrete_columns=['education', 'employed'])
# Générer des échantillons synthétiques
synthetic_data = ctgan.sample(1000)
print("\nÉchantillon de Données Synthétiques :")
print(synthetic_data.head())
print("\nInfos sur les Données Synthétiques :")
print(synthetic_data.describe())
# Comparer les distributions
print("\nDistributions des Données Originales vs Synthétiques :")
for column in data.columns:
if data[column].dtype == 'object':
print(f"\nDistribution de {column} :")
print("Original :")
print(data[column].value_counts(normalize=True))
print("Synthétique :")
print(synthetic_data[column].value_counts(normalize=True))
else:
print(f"\nMoyenne et écart-type de {column} :")
print(f"Original : moyenne = {data[column].mean():.2f}, écart-type = {data[column].std():.2f}")
print(f"Synthétique : moyenne = {synthetic_data[column].mean():.2f}, écart-type = {synthetic_data[column].std():.2f}")Le code produit une sortie comme celle-ci (notez la différence dans les paramètres statistiques) :
Échantillon de Données Originales : âge revenu éducation employé 0 57 25950 Master No 1 78 45752 High School No … Infos sur les Données Originales : âge revenu compte 1000.00000 1000.000000 moyenne 53.75300 109588.821000 écart 21.27013 50957.809301 min 18.00000 20187.000000 25% 35.00000 66175.250000 50% 54.00000 111031.000000 75% 73.00000 152251.500000 max 89.00000 199836.000000 Échantillon de Données Synthétiques : âge revenu éducation employé 0 94 78302 Bachelor Yes 1 31 174108 Bachelor No … Infos sur les Données Synthétiques : âge revenu compte 1000.000000 1000.000000 moyenne 70.618000 117945.021000 écart 18.906018 55754.598894 min 15.000000 -5471.000000 25% 57.000000 73448.000000 50% 74.000000 112547.500000 75% 86.000000 163881.250000 max 102.000000 241895.000000
Dans cet exemple :
- Nous importons les bibliothèques nécessaires.
- Chargez vos données réelles dans un DataFrame pandas.
- Initialisez le modèle CTGAN.
- Ajustez le modèle à vos données, en spécifiant quelles colonnes sont discrètes.
- Générez des échantillons synthétiques à l’aide du modèle entraîné.
CTGAN est particulièrement utile lorsque vous devez générer des données synthétiques qui maintiennent des relations complexes et des distributions présentes dans votre ensemble de données original. Il est plus avancé que les méthodes d’échantillonnage aléatoire simples comme celles utilisées dans Faker.
Quelques fonctionnalités clés de CTGAN incluent :
- Gestion à la fois des colonnes numériques et catégorielles
- Préservation des corrélations entre les colonnes
- Gestion des distributions multimodales
- Échantillonnage conditionnel basé sur des valeurs de colonnes spécifiques
Autres Outils Remarquables
- SDV (Synthetic Data Vault) : Une bibliothèque Python pour générer des données synthétiques relationnelles multi-tables.
- Gretel.ai : Une plateforme offrant diverses techniques de génération de données synthétiques, y compris la confidentialité différentielle.

Génération de Données d’Images
Bien qu’il soit vrai que Faker, SDV et CTGAN ne prennent pas en charge nativement la génération de données d’images et de voix, il existe effectivement des outils open-source disponibles pour ces besoins. Ces outils représentent la technologie la plus proche de l’IA dans ce domaine et peuvent actuellement servir de générateurs de données IA à part entière. Cependant, ils sont généralement plus spécialisés et nécessitent souvent plus de configuration et d’expertise pour être utilisés efficacement. Voici un aperçu :
Pour la génération d’images :
- StyleGAN : Une architecture GAN avancée, particulièrement bonne pour les images de visage de haute qualité.
- DALL-E mini (désormais appelé Craiyon) : Une version open-source inspirée du DALL-E d’OpenAI, pour générer des images à partir de descriptions textuelles.
- Stable Diffusion : Une récente avancée dans la génération d’images à partir de texte, avec des implémentations open-source disponibles.
Pour la génération de données vocales :
- Bibliothèques TTS (Texte-à-Parole) comme Mozilla TTS ou Coqui TTS : Elles peuvent générer des données vocales synthétiques à partir de texte.
- WaveNet : Initialement développé par DeepMind, dispose maintenant de implémentations open-source pour générer une parole réaliste.
- Tacotron 2 : Un autre modèle populaire pour générer une parole humaine, avec des versions open-source disponibles.
Ces outils sont effectivement “prêts à l’emploi” dans le sens où ils sont ouvertement disponibles, mais ils nécessitent souvent :
- Plus de configuration technique (par exemple, ressources GPU, dépendances spécifiques)
- Compréhension des concepts de deep learning
- Éventuellement, un ajustement sur des données spécifiques au domaine
Cela contraste avec les outils comme Faker, qui sont plus plug-and-play pour des types de données plus simples. La complexité des données d’images et de voix nécessite des modèles plus sophistiqués, ce qui à son tour exige plus d’expertise pour être mis en œuvre efficacement.
Meilleures Pratiques pour Utiliser les Générateurs de Données IA
- Valider les données synthétiques : Assurez-vous qu’elles maintiennent les propriétés statistiques et les relations des données originales.
- Utiliser l’expertise de domaine : Ingrainez des connaissances de domaine pour générer des données synthétiques réalistes et significatives.
- Combiner avec des données réelles : Quand c’est possible, utilisez des données synthétiques pour augmenter les ensembles de données réels plutôt que de les remplacer complètement.
- Considérer les implications en matière de confidentialité : Même avec des données synthétiques, soyez prudent quant aux potentielles fuites de confidentialité, surtout dans des domaines sensibles.
- Mettre à jour régulièrement les modèles : À mesure que les données du monde réel changent, mettez à jour vos modèles génératifs pour vous assurer que les données synthétiques restent pertinentes.
L’Avenir de la Génération de Données IA
À mesure que la technologie IA continue de progresser, nous pouvons nous attendre à des capacités de génération de données encore plus sophistiquées et polyvalentes. Quelques tendances émergentes incluent :
- Amélioration du réalisme dans les données générées à travers tous les domaines
- Techniques de préservation de la confidentialité renforcées intégrées dans les processus de génération
- Outils plus accessibles pour les utilisateurs non techniques pour créer des ensembles de données synthétiques personnalisés
- Utilisation accrue des données synthétiques dans la conformité réglementaire et les scénarios de test
Conclusion
Les générateurs de données IA révolutionnent la façon dont nous créons et travaillons avec les données. De la résolution de la pénurie de données à l’amélioration de la confidentialité et de la sécurité, les données synthétiques offrent de nombreux avantages à travers diverses industries. À mesure que cette technologie continue d’évoluer, elle jouera un rôle de plus en plus crucial dans la promotion de l’innovation, l’amélioration des modèles d’apprentissage automatique et la création de nouvelles possibilités dans la prise de décision basée sur les données.
En utilisant des outils comme la bibliothèque Python Faker et des générateurs IA plus avancés, les organisations peuvent créer des ensembles de données diversifiés et réalistes adaptés à leurs besoins spécifiques. Cependant, il est essentiel d’aborder la génération de données synthétiques avec précaution, en veillant à ce que les données générées maintiennent l’intégrité et la pertinence requises pour leur utilisation prévue.
En regardant vers l’avenir, le potentiel des générateurs de données IA est sans limites, promettant de débloquer de nouvelles frontières en science des données, apprentissage automatique et au-delà.
Pour ceux intéressés à explorer des outils conviviaux et flexibles pour la sécurité des bases de données, incluant des capacités de données synthétiques, envisagez de vérifier DataSunrise. Notre suite complète de solutions offre une protection robuste et des fonctionnalités innovantes pour les environnements de données modernes. Visitez notre site Web pour une démonstration en ligne et découvrez comment nos outils peuvent améliorer votre stratégie de sécurité des données.
Suivant
