
Explorer les Avantages de la Génération de Données Synthétiques pour les Flux de Travail Modernes

Un sondage récent de Gartner auprès de plus de 2 500 dirigeants exécutifs a révélé que 45% ont augmenté leurs investissements dans l’IA en réponse à la frénésie autour de ChatGPT. Chez DataSunrise, nous suivons cette tendance. Vous avez probablement lu notre précédent article sur les outils basés sur l’IA pour la génération de données synthétiques (aléatoires ou fausses). Cet article concerne davantage le sujet de la génération de données synthétiques avec DataSunrise et quelques autres outils disponibles gratuitement.
Que ce soit pour les tests, la formation ou le développement, obtenir des données du monde réel pose des défis. Les préoccupations de confidentialité, les problèmes de disponibilité des données et les restrictions réglementaires empêchent souvent l’accès aux données réelles. C’est là que la génération de données aléatoires entre en jeu. Elle offre une solution en créant des données artificielles qui imitent les caractéristiques des données réelles sans compromettre la confidentialité ou la sécurité.
Qu’est-ce que les Données Synthétiques?
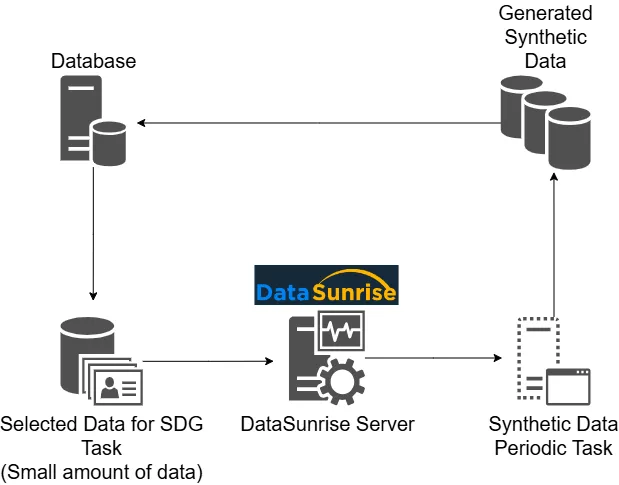
Les données synthétiques sont des données générées artificiellement qui ressemblent aux données du monde réel en termes de propriétés statistiques, de motifs et de structures. Elles ne contiennent aucune information réelle sur les individus ou les entités. Au lieu de cela, vous créez ces données en utilisant des algorithmes et des modèles mathématiques pour maintenir l’authenticité tout en évitant les risques liés à la gestion des données sensibles.
Capacités de DataSunrise dans la Génération de Données Synthétiques
DataSunrise offre une fonctionnalité robuste de génération de données aléatoires qui imite avec précision les données réelles. On utilise cette fonctionnalité à diverses fins commerciales, du développement et des tests à l’amélioration des algorithmes d’apprentissage automatique. Examinons les capacités de DataSunrise dans le domaine de la génération de données synthétiques.
Test de la Confidentialité et de la Sécurité des Données
L’une des principales applications des données est dans les tests de confidentialité et de sécurité des données. Les organisations, en particulier dans des secteurs tels que la finance, la santé et le juridique, peuvent utiliser des données synthétiques pour évaluer leurs systèmes de sécurité sans exposer de véritables informations sensibles. Par exemple, une institution financière peut générer des données de transaction synthétiques pour tester ses systèmes de détection de la fraude.
Formation de Modèles d’Apprentissage Automatique
Les industries utilisent de plus en plus de données factices pour former des modèles d’apprentissage automatique. Cette approche permet de garantir que la confidentialité des données réelles n’est pas compromise. Par exemple, une entreprise de santé peut générer des dossiers de patients synthétiques pour former un modèle prédictif de diagnostic de maladies sans violer la confidentialité des patients.
Développement et Test de Logiciels
Les données synthétiques sont inestimables dans le développement de logiciels. Elles fournissent des ensembles de données réalistes pour créer et évaluer des applications, notamment dans des industries comme les télécommunications. Par exemple, une société de télécommunications peut générer des enregistrements d’appels synthétiques pour tester son logiciel de facturation.
Analyse des Soins de Santé
Dans le domaine de la santé, ces données permettent aux chercheurs et aux scientifiques de mener des études et des expériences sans violer la confidentialité des patients. Par exemple, une équipe de recherche peut générer des données de patients synthétiques pour étudier les effets d’un nouveau médicament.
Comment Générer des Données Synthétiques avec DataSunrise
DataSunrise simplifie le processus de génération de données aléatoires, ce qui facilite l’intégration des données dans divers flux de travail. Voici un guide étape par étape sur la façon de générer des données en utilisant DataSunrise.
Étape 1 : Paramètres Généraux
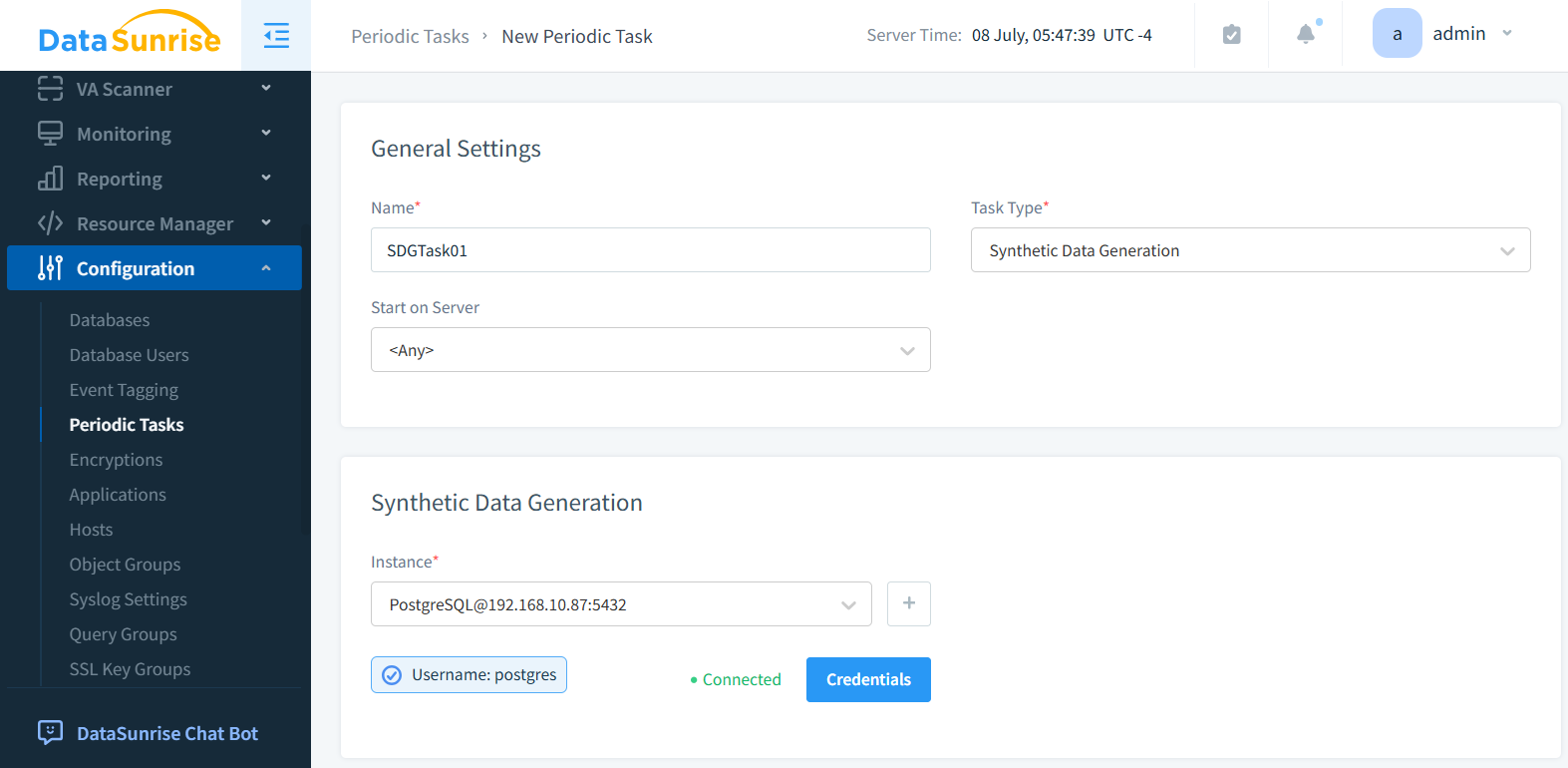
Allez dans Configuration – Tâches Périodiques. Cliquez sur +Nouvelle tâche. Dans la sous-section Paramètres Généraux, définissez le nom de votre Tâche Périodique. Sélectionnez le type de tâche – Génération de Données Synthétiques – et sur quel serveur démarrer (optionnel).
Étape 2 : Sélectionner l’Instance de la Base de Données
Dans la sous-section Génération de Données Synthétiques, sélectionnez l’instance de la base de données. L’instance PostgreSQL est sélectionnée sur la figure ci-dessous.
Étape 3 : Tables Générées
Dans la sous-section Tables Générées, sélectionnez les cases à cocher nécessaires (par exemple, Table Cible Vide et Ignorer la Génération de Tables en Cas d’Erreur). Cliquez sur +Sélectionner pour ouvrir une fenêtre où vous pouvez sélectionner les objets de base de données dont vous avez besoin. Choisissez une base de données, un schéma, une table et une colonne pour lesquelles des données synthétiques seront générées. Après avoir fait vos sélections, cliquez sur Enregistrer.
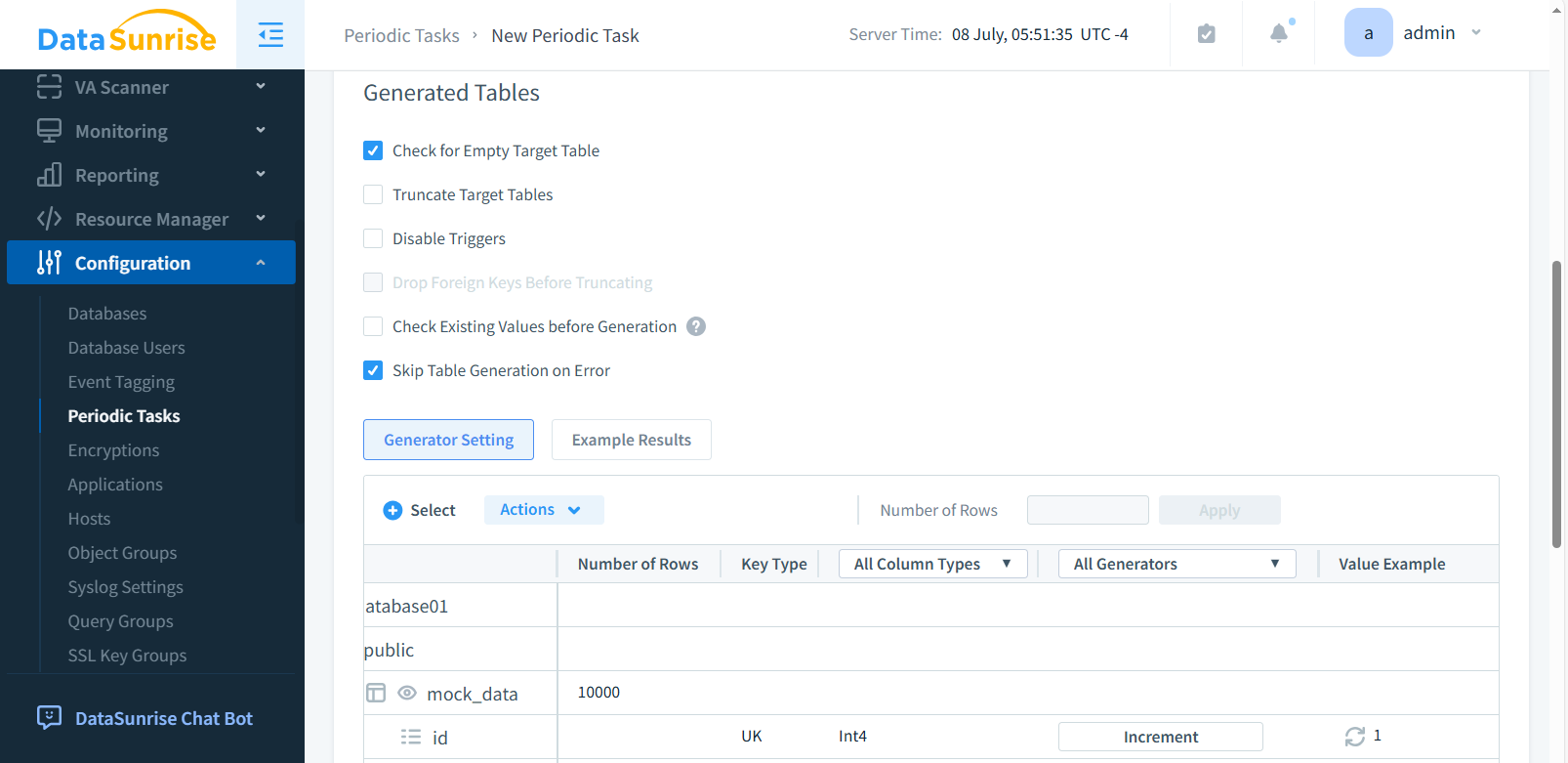
Étape 4 : Sélection des Générateurs de Données (optionnel)
Dans la colonne Tous les Générateurs, vous pouvez sélectionner ou créer le générateur. Dans la section Résultats Exemplaires, vous verrez la liste des données générées. Après avoir tout terminé, cliquez sur Appliquer ou Enregistrer. Cela est optionnel car le système assigne des générateurs par défaut aux colonnes sélectionnées.
Si vous souhaitez créer votre propre générateur spécifique (avant de créer la tâche de Génération de Données Synthétiques), allez dans Configuration – Générateurs, et cliquez sur +Créer Générateur. Sélectionnez un type de générateur et spécifiez ses paramètres. Cliquez sur Enregistrer, et vous pourrez appliquer votre générateur dans la tâche de Génération de Données Synthétiques.
‘Nombre de lignes’ en haut de la table devient actif lorsque la colonne est sélectionnée.
Étape 5 : Enregistrement et exécution de la tâche
Ici, vous pouvez voir les Tâches Périodiques avec la Tâche de Génération de Données Synthétiques ainsi que quelques tâches périodiques de comportement utilisateur créées plus tôt.
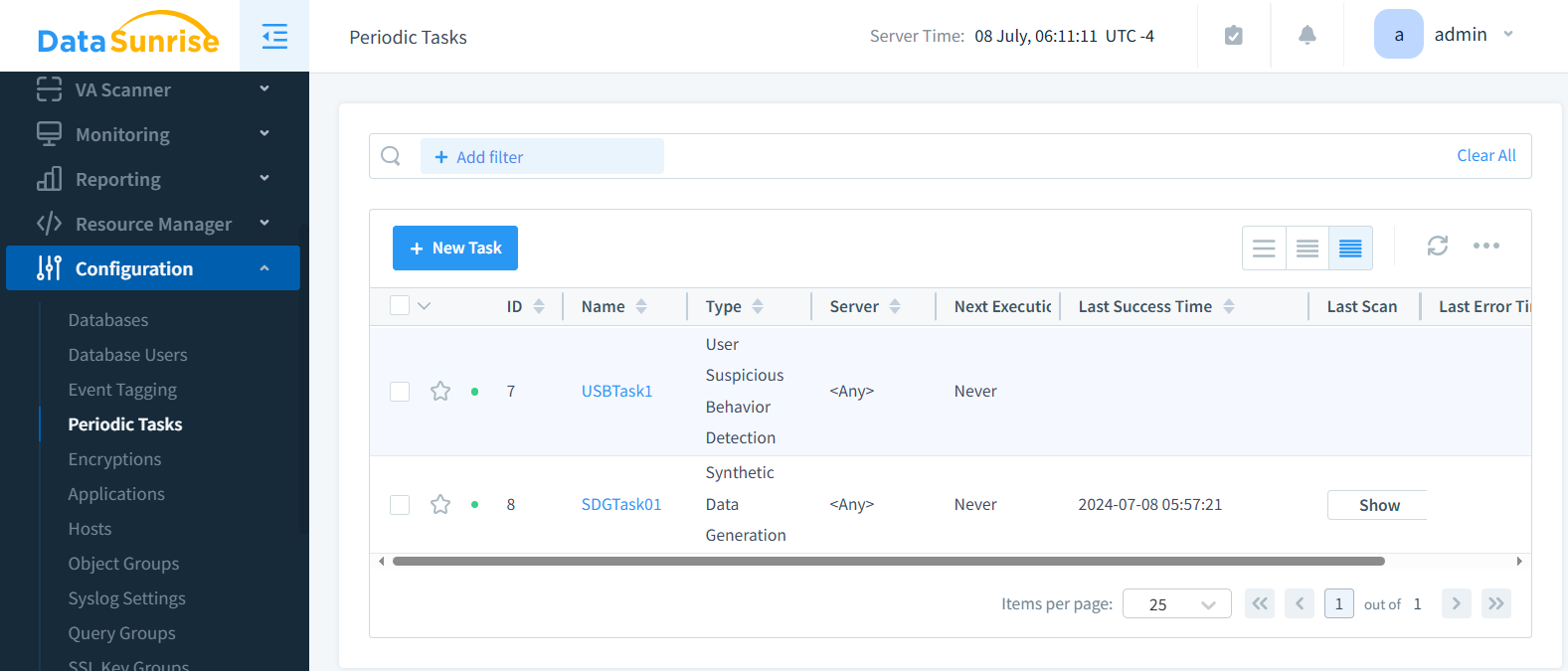
La tâche est prête maintenant. Exécutez la tâche selon vos besoins ou faites-la s’exécuter périodiquement.
Outils en Ligne et Solutions Open-Source
DataSunrise offre un contrôle hautement flexible et robuste sur la génération de données aléatoires, ainsi que des solutions de sécurité de base de données de premier ordre qui fournissent la plus grande couverture de bases de données et d’entrepôts cloud disponibles sur le marché. Cependant, qu’en est-il des options gratuites? Plusieurs outils en ligne et bibliothèques open-source sont disponibles pour générer des données factices à moindre coût. Explorons quelques options populaires :
SDV (Synthetic Data Vault)
Nous avons brièvement discuté de ce sujet dans notre précédent article sur la génération de données AI. Là, nous avons mentionné que CTGAN est un composant de SDV (Synthetic Data Vault). Pour récapituler, SDV est une bibliothèque Python open-source pour générer des données relationnelles multi-tables. Elle utilise l’apprentissage automatique pour créer des données artificielles qui maintiennent les propriétés statistiques de l’ensemble de données d’origine. Pour installer en utilisant pip, utilisez la commande suivante :
pip install sdv
Exemple d’utilisation :
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
# Télécharger le jeu de données de démonstration
real_data, metadata = download_demo(
modality='single_table',
dataset_name='fake_hotel_guests'
)
# Créer et ajuster le synthétiseur
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
# Générer des données factices
synthetic_data = synthesizer.sample(num_rows=500)
# Afficher les premières lignes des données générées
print(synthetic_data.head())Ce script utilise le synthétiseur GaussianCopula de SDV pour générer des données synthétiques basées sur les propriétés statistiques d’un jeu de données réel.
Le résultat peut ressembler à ceci :
CTGAN (Conditional Tabular GAN)
CTGAN est un modèle basé sur GAN spécialement conçu pour générer des données tabulaires synthétiques. Il est particulièrement utile pour les ensembles de données complexes avec des types de données mixtes.
Veuillez consulter notre précédent article sur les outils liés à l’IA pour la génération de données synthétiques pour un échantillon de code CTGAN.
Mockaroo
Mockaroo est un outil web écrit en Ruby qui vous permet de générer des données aléatoires réalistes dans divers formats (CSV, JSON, SQL, etc.) sans programmation. Il offre une interface conviviale et prend en charge des schémas de données personnalisés. L’accès gratuit est limité à 1000 lignes de données.
Meilleures Pratiques pour la Génération de Données Factices
Pour assurer des données fictives de haute qualité :
- Comprenez vos besoins en données et votre cas d’utilisation
- Choisissez la méthode de génération appropriée en fonction de vos besoins
- Validez les données générées par rapport à votre ensemble de données ou à vos exigences d’origine
- Assurez la confidentialité des données en évitant l’inclusion d’informations sensibles
- Affinez continuellement votre processus de génération en fonction des commentaires et des résultats
Conclusion
La génération de données synthétiques fournit une solution précieuse pour les organisations cherchant à travailler avec des données réalistes tout en protégeant la confidentialité et la sécurité. DataSunrise simplifie ce processus, facilitant l’intégration des données artificielles dans divers flux de travail. Cependant, il est essentiel de valider l’efficacité et la fiabilité des données synthétiques. Les organisations doivent s’assurer que les données générées représentent fidèlement la distribution des données réelles et maintiennent les relations et dépendances nécessaires.
En résumé, la génération de données offre de nombreux avantages, de l’amélioration de la confidentialité et de la sécurité des données à l’amélioration des modèles d’apprentissage automatique et des tests logiciels. Avec la fonctionnalité de Génération de Données Synthétiques de DataSunrise, les organisations peuvent naviguer en toute confiance dans le paysage des données et exploiter la puissance des données générées pour leurs besoins commerciaux.
Pour plus d’informations, visitez notre site web ou demandez une démonstration en ligne.
Suivant
