
Masquage Statique des Données dans Greenplum : Améliorer la Sécurité et la Conformité des Données

Greenplum, un puissant entrepôt de données open-source, offre des fonctionnalités robustes pour gérer et analyser de grands ensembles de données. Alors que les organisations traitent des quantités croissantes de données sensibles, le besoin de méthodes de protection des données efficaces est devenu primordial. Le masquage statique des données protège les informations sensibles dans Greenplum tout en permettant aux utilisateurs de les utiliser pour différents besoins. Cet article explore le concept de masquage statique des données dans Greenplum, ses avantages, ses défis, et les meilleures pratiques pour sa mise en œuvre.
Masquage Statique des Données : Définition et Avantages
Le masquage statique des données est un processus qui remplace les données sensibles par des informations réalistes mais fictives. Cette méthode aide les organisations à garder leurs données importantes en sécurité. Elle leur permet aussi d’utiliser les données masquées pour les tests, le développement, ou les analyses.
Dans Greenplum, le masquage statique des données ajoute une sécurité supplémentaire. Il garde les informations sensibles privées, même lorsqu’elles sont partagées avec des utilisateurs non autorisés ou transférées vers des environnements non productifs.
Le principal objectif du masquage statique des données est de créer une version des données qui ressemble et fonctionne comme l’original, sans toutefois contenir aucune information sensible.
Cette méthode permet aux organisations d’utiliser des données masquées pour différentes raisons tout en gardant les données originales en sécurité et privées.
La mise en œuvre du masquage statique des données dans Greenplum offre plusieurs avantages majeurs :
Amélioration de la Sécurité des Données : En remplaçant les informations sensibles par des données fictives, les organisations peuvent significativement réduire le risque de violations de données. Même si des utilisateurs non autorisés accèdent aux données masquées, ils ne peuvent pas en extraire des informations précieuses ou sensibles.
Conformité Réglementaire : De nombreuses industries sont soumises à des réglementations strictes en matière de protection des données comme le RGPD, le HIPAA, ou le PCI DSS. Le masquage statique des données aide les organisations à suivre ces règles en s’assurant que les données sensibles n’apparaissent pas dans les environnements non productifs.
Amélioration des Tests et du Développement : Le masquage statique des données permet aux organisations d’utiliser des données semblables à celles de la production dans les environnements de test et de développement. Cette approche donne des résultats de test plus précis et fiables. Les développeurs et les testeurs peuvent utiliser des données qui ressemblent à des situations réelles, sans risquer de divulguer des informations sensibles.
Réduction des Coûts : L’utilisation de données masquées au lieu de jeux de données synthétiques aide les organisations, surtout lors de la préparation de données à des fins non productives. Cette efficacité peut conduire à des économies significatives à long terme.
Partage de Données : Le masquage statique des données permet aux organisations de partager des données avec des vendeurs tiers, des partenaires ou des équipes de développement offshore sans exposer des informations sensibles. Cette capacité facilite la collaboration tout en maintenant la sécurité des données.
Défis et Techniques
Bien que le masquage statique des données offre de nombreux avantages, il présente également certains défis que les organisations doivent relever :
Maintien de la Cohérence des Données : L’un des plus grands défis est de s’assurer que les données masquées restent cohérentes entre les tables liées. Pour maintenir l’intégrité référentielle de la base de données, nous devons préserver les relations entre les différents éléments de données.
Préservation de l’Utilité des Données : Les données masquées doivent conserver les mêmes motifs et caractéristiques que les données originales pour être utiles à l’analyse et au test. Trouver le juste équilibre entre la protection des données et leur utilité peut être difficile.
Impact sur les Performances : Le processus de masquage peut prendre beaucoup de temps et de ressources, selon les techniques utilisées et la quantité de données. Les organisations doivent tenir compte de l’impact sur les performances de leur environnement Greenplum.
Identification des Données Sensibles : Identifier de manière exhaustive tous les éléments de données sensibles dans une structure de base de données complexe peut être une tâche ardue. Oublier même un seul champ sensible peut compromettre l’ensemble des efforts de masquage.
Greenplum propose diverses méthodes pour implémenter le masquage statique des données, y compris des fonctions intégrées, des outils tiers, et des scripts personnalisés. Quelques techniques courantes utilisées dans le masquage statique des données dans Greenplum incluent :
Substitution : Cette technique consiste à remplacer les données sensibles par des valeurs réalistes mais fausses.
Mélange (Shuffling) : Cette méthode consiste à randomiser les valeurs au sein d’une colonne tout en maintenant les propriétés statistiques globales des données, tout en obscurcissant les enregistrements individuels.
Chiffrement : Vous pouvez transformer les données sensibles en utilisant des algorithmes de chiffrement. Bien que cette méthode offre une forte protection, elle peut limiter l’utilisabilité des données pour certaines fins.
Meilleures Pratiques et Mise en Œuvre
Pour maximiser l’efficacité du masquage statique des données dans Greenplum, considérez les meilleures pratiques suivantes :
Identifier les Données Sensibles : Analysez en profondeur votre base de données Greenplum pour identifier tous les éléments de données sensibles. Cette étape garantit que le processus de masquage ne néglige aucune information confidentielle.
Choisir des Techniques de Masquage Appropriées : Sélectionnez les techniques de masquage qui conviennent le mieux à vos types de données et à vos exigences de sécurité. Différents éléments de données peuvent nécessiter différentes approches de masquage pour maintenir l’intégrité des données et leur utilisabilité.
Maintenir les Relations de Données : Lorsque vous masquez des données sur plusieurs tables, assurez-vous de préserver les relations entre les tables. Cette étape est cruciale pour maintenir la cohérence des données et éviter les problèmes dans les applications qui dépendent de ces relations.
Documenter les Règles de Masquage : Maintenez une documentation claire de toutes les règles et procédures de masquage. Cette documentation devrait inclure les champs masqués, les techniques utilisées, et toute exception ou cas particulier.
Créer une Table Séparée avec des Données Masquées
Voici un exemple de création d’une table séparée remplie avec des données masquées dans Greenplum :
-- Table originale
CREATE TABLE customer_data (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
credit_card VARCHAR(16),
date_of_birth DATE
);
-- Insérer des données d'exemple
INSERT INTO customer_data (name, email, credit_card, date_of_birth)
VALUES ('John Doe', 'john@example.com', '1234567890123456', '1980-05-15');
-- Créer une table masquée
CREATE TABLE masked_customer_data AS
SELECT
id,
'Customer_' || id AS masked_name,
'user_' || id || '@masked.com' AS masked_email,
SUBSTRING(credit_card, 1, 4) || 'XXXXXXXXXXXX' AS masked_credit_card,
date_of_birth + (RANDOM() * 365 * INTERVAL '1 day') AS masked_date_of_birth
FROM customer_data;
-- Afficher les données masquées
SELECT * FROM masked_customer_data;
Cet exemple crée une nouvelle table appelée `masked_customer_data` avec des versions masquées des champs sensibles. Nous changeons le `nom` en “Customer_” suivi de l’ID.
Le système cache l’`email` dans un format masqué. Le `numéro de carte de crédit` n’affiche que les quatre premiers chiffres, remplacés ensuite par des caractères ‘X’.
Un nombre aléatoire de jours déplace la `date de naissance`. Cela peut aller jusqu’à un an, ce qui maintient la distribution générale des âges tout en cachant les dates de naissance exactes.
Mise en Œuvre via DataSunrise
Greenplum aide les utilisateurs à masquer les données statiques, cependant, cela peut être compliqué et lent pour de grandes bases de données. Dans ce cas, nous suggérons d’utiliser des solutions tierces. Pour démarrer cela sur DataSunrise, vous devez créer une instance d’une base de données Greenplum.
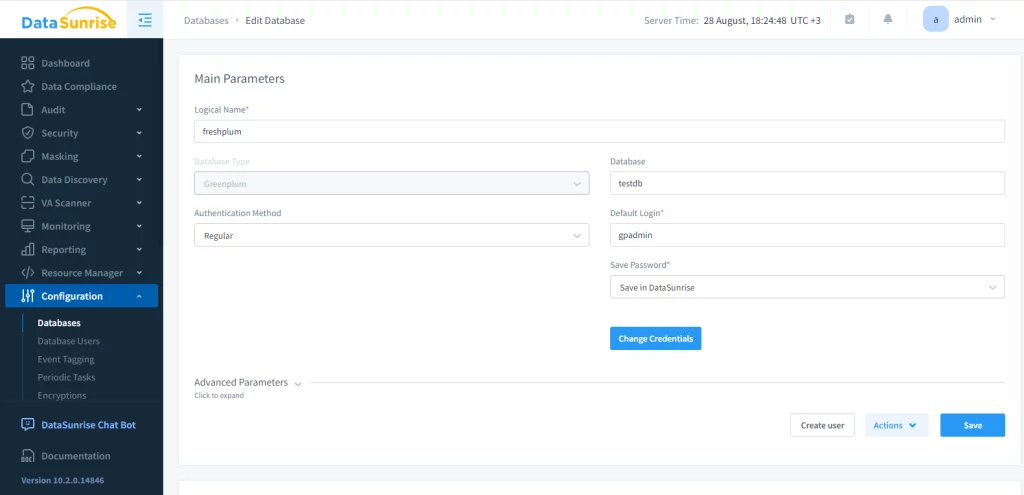
L’instance permet d’interagir avec la base de données source via l’audit, les règles de masquage et de sécurité et les tâches. Ensuite, nous devons configurer une tâche de masquage statique. Cette étape comprend trois actions : choisir le serveur de départ, sélectionner les bases de données source et cible (toutes deux doivent être Greenplum), et définir les règles de masquage. Pour des raisons d’intégrité, nous encourageons la troncature du schéma cible.
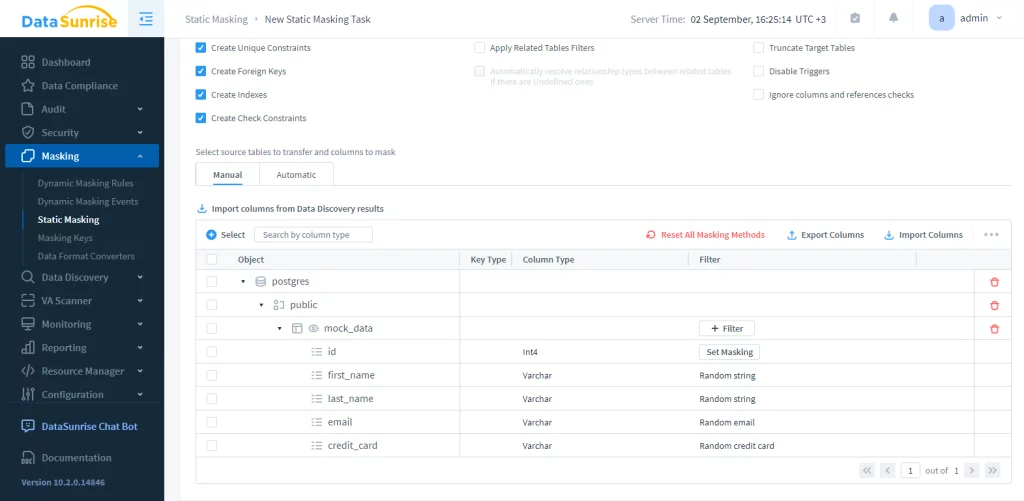
Dans cet exemple, la table masquée est mock_data dans la base de données postgres. Il suffit de démarrer la tâche. Le résultat est le suivant :

Conclusion
Le masquage statique des données dans Greenplum est une technique puissante pour améliorer la sécurité et la conformité des données. Les organisations peuvent protéger les informations sensibles en utilisant des méthodes efficaces tout en gardant les données utilisables pour les tests, le développement et l’analyse.
Les préoccupations concernant la confidentialité des données augmentent et les réglementations se resserrent. Le masquage statique des données est crucial pour les entreprises qui utilisent Greenplum pour sécuriser leurs données. Les organisations peuvent utiliser les informations de cet article pour créer des stratégies de masquage statique de données efficaces. Cela aidera à protéger les informations sensibles tout en leur permettant d’utiliser leurs données précieuses de manière efficace.
Suivant
