
Comment Mettre en Œuvre le Masquage de Données Statique dans Amazon DynamoDB
Introduction
En 2022, les solutions basées sur le cloud représentaient 53% du marché global des logiciels de prévention des pertes de données (DLP), avec une croissance du marché global montrant une expansion non linéaire. Amazon DynamoDB, un service de base de données NoSQL populaire, stocke de grandes quantités de données, y compris des informations potentiellement sensibles. Le masquage de données statique offre une solution puissante pour protéger ces données. Explorons comment le masquage de données statique peut être mis en œuvre pour Amazon DynamoDB, en nous concentrant sur des techniques et des outils pratiques.
Les principaux fournisseurs de DLP priorisent le développement de solutions compatibles cloud et natives pour répondre à la demande croissante. Chez DataSunrise, nous sommes attentifs à ces tendances de l’industrie et offrons des solutions de pointe conçues pour protéger efficacement les infrastructures de données basées sur le cloud.
Comprendre le Masquage de Données Statique
Le masquage de données statique est une technique de sécurité qui remplace les données sensibles par des informations réalistes mais fictives. Contrairement au masquage dynamique, qui se produit en temps réel, le masquage statique modifie de façon permanente les données au repos. Cette approche est idéale pour créer des environnements de test et de développement sûrs et non productifs.
Avantages du Masquage de Données Statique
- Sécurité des données améliorée
- Conformité aux réglementations sur la protection des données
- Réduction du risque de violations de données
- Environnement sûr pour le développement et les tests
Capacités de Masquage Natives dans Amazon DynamoDB
Amazon DynamoDB offre des capacités de masquage natives, que nous avons couvertes dans nos articles précédents sur le masquage et le masquage dynamique pour DynamoDB. Ces fonctionnalités permettent le post-traitement des résultats de requêtes après la récupération des données en utilisant l’API Python ou l’interface de ligne de commande (CLI).
Implémentation du Masquage de Données Statique avec Python et Boto3
Explorons un exemple pratique de masquage de données statique utilisant Python et la bibliothèque Boto3. Nous allons nous connecter à la base de données, créer une copie des données (table MaskedDanielArticleTable), et masquer des informations sensibles comme les adresses email et IP.
import boto3
from boto3.dynamodb.conditions import Key
import time
# Connexion à DynamoDB
dynamodb = boto3.resource('dynamodb')
source_table = dynamodb.Table('danielArticleTable')
# Créer la table masquée
try:
masked_table = dynamodb.create_table(
TableName='MaskedDanielArticleTable',
KeySchema=[
{'AttributeName': 'id', 'KeyType': 'HASH'},
],
AttributeDefinitions=[
{'AttributeName': 'id', 'AttributeType': 'S'},
],
ProvisionedThroughput={
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
)
print("Création de la table masquée...")
masked_table.meta.client.get_waiter('table_exists').wait(TableName='MaskedDanielArticleTable')
print("Table masquée créée avec succès")
except dynamodb.meta.client.exceptions.ResourceInUseException:
print("La table masquée existe déjà")
masked_table = dynamodb.Table('MaskedDanielArticleTable')
# Fonction de masquage des emails
def mask_email(email):
username, domain = email.split('@')
masked_username = username[:2] + '*' * (len(username) - 2)
return f"{masked_username}@{domain}"
# Fonction de masquage des adresses IP
def mask_ip(ip):
octets = ip.split('.')
masked_octets = octets[:2] + ['***', '***']
return '.'.join(masked_octets)
# Scanner la table source
response = source_table.scan()
items = response['Items']
# Masquer et copier les données
for item in items:
masked_item = item.copy()
if 'email' in masked_item:
masked_item['email'] = mask_email(masked_item['email'])
if 'ip_address' in masked_item:
masked_item['ip_address'] = mask_ip(masked_item['ip_address'])
# Insérer l'élément masqué dans la nouvelle table
masked_table.put_item(Item=masked_item)
print("Masquage de données statique terminé.")La sortie (exécuté dans Jupyter Notebook) est la suivante :
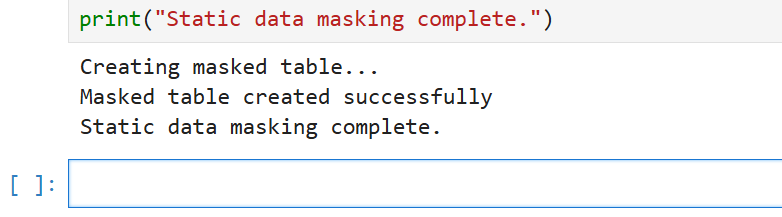
Ce script démontre une approche basique du masquage de données statique. Il crée une nouvelle table avec des données masquées, garantissant que les informations sensibles d’origine restent protégées.
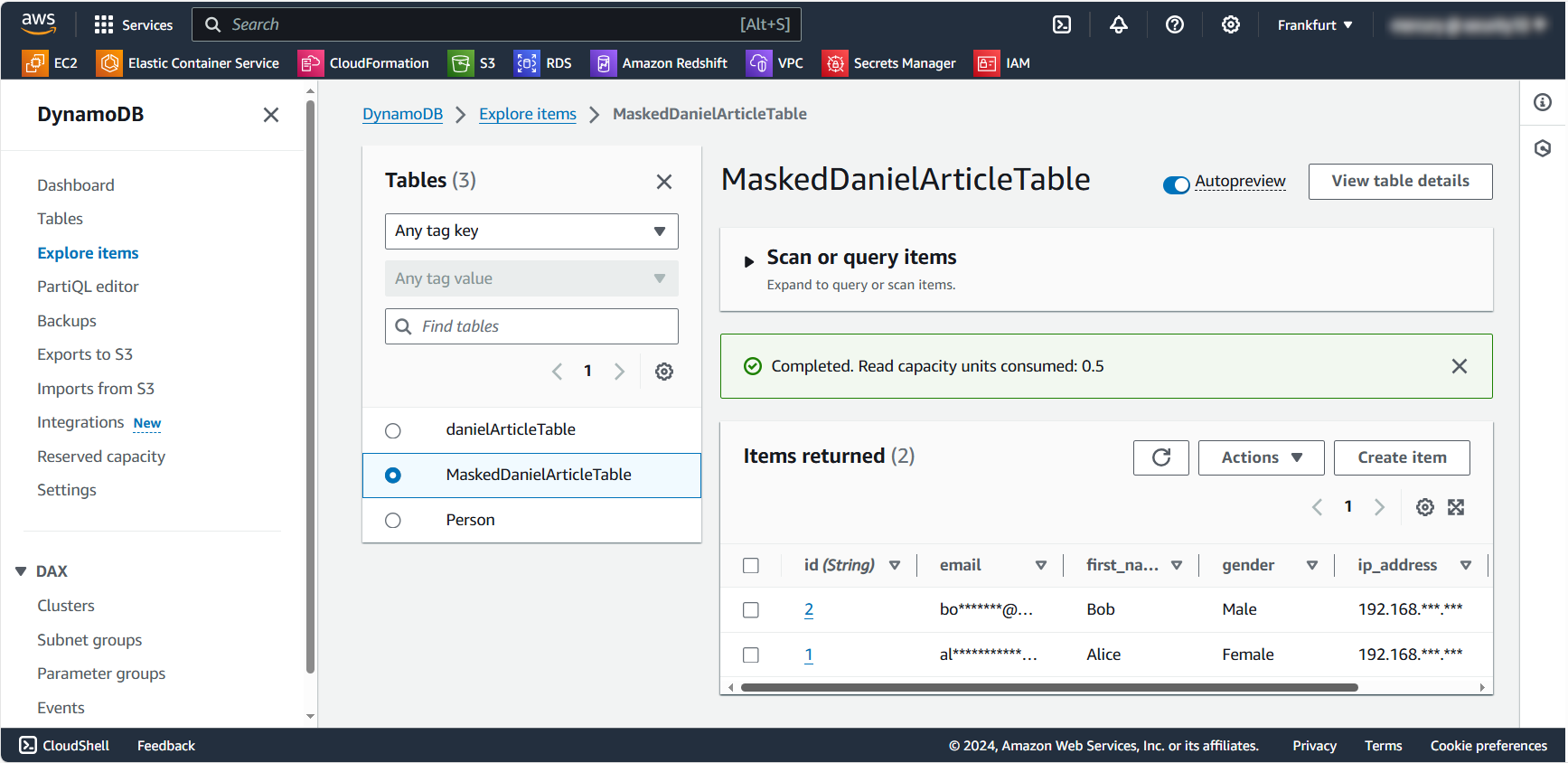
Avant de continuer, il est important de traiter certains points clés concernant le code fourni. La nature du schéma flexible de DynamoDB présente des défis uniques pour le masquage de données statique automatisé. Examinons ces complexités :
- Différents éléments dans la même table peuvent avoir des attributs différents.
- De nouveaux attributs peuvent être ajoutés aux éléments à tout moment sans avoir à modifier la structure de la table.
Pour relever ces défis :
- Implémentez des règles de masquage flexibles capables de s’adapter aux structures de données variées.
- Utilisez des techniques de correspondance de motifs ou d’apprentissage automatique pour identifier les données potentiellement sensibles.
- Maintenez un catalogue complet des modèles de données sensibles et de leurs emplacements.
- Employez des techniques d’échantillonnage pour gérer efficacement les grands ensembles de données.
Masquage de Données Statique avec DataSunrise
La version actuelle de DataSunrise (10.0) offre un masquage dynamique complet pour DynamoDB, mais ne prend pas en charge le masquage statique pour cette base de données. Pour une vue d’ensemble complète des bases de données et fonctionnalités prises en charge, veuillez consulter le chapitre 1.2, ‘Bases de Données et Fonctionnalités Prises en Charge’, dans notre documentation. Par conséquent, les instances DynamoDB ne sont pas disponibles pour la sélection dans les listes de bases de données source et cible lors de la configuration d’une tâche de masquage statique.
Meilleures Pratiques pour le Masquage de Données Statique dans DynamoDB
Pour maximiser l’efficacité de vos efforts de masquage de données statique :
- Identifiez tous les attributs sensibles des données
- Utilisez des techniques de masquage réalistes pour maintenir l’utilisabilité des données
- Mettez à jour régulièrement les règles de masquage pour prendre en compte de nouveaux types de données
- Mettez en place des contrôles d’accès pour les données masquées
- Auditez les processus de masquage pour en assurer l’efficacité
Défis et Considérations
Bien que le masquage de données statique offre des avantages significatifs, il est important de considérer les défis potentiels :
- Impact sur les performances pendant le processus de masquage
- Maintien de l’intégrité référentielle dans les ensembles de données masquées
- Assurer que les données masquées restent utiles pour les tests et le développement
- Maintien des règles et des tâches de masquage à jour avec les structures de données changeantes
Conclusion
Le masquage de données statique pour Amazon DynamoDB fournit un outil puissant pour protéger les informations sensibles. En appliquant des techniques de masquage robustes, les organisations peuvent significativement réduire le risque de violations de données et assurer la conformité aux réglementations sur la protection des données.
Que ce soit en utilisant les fonctionnalités natives de DynamoDB, des scripts Python personnalisés ou des outils spécialisés, le masquage de données statique offre une approche flexible et efficace pour protéger vos actifs de données précieux.
DataSunrise offre une suite complète d’outils de sécurité des bases de données, incluant des fonctionnalités avancées d’audit et de conformité. Nos solutions de pointe fournissent des options flexibles et puissantes pour protéger vos données sensibles sur divers plateformes de bases de données. Visitez notre site web pour programmer une démo en ligne et découvrir comment DataSunrise peut améliorer votre stratégie de sécurité des données.
Suivant
