
Masquage de Données Statique pour Amazon Redshift

Introduction
L’ère numérique bat son plein, avec 67 % de la population mondiale utilisant maintenant Internet. Cette adoption généralisée a catalysé un changement significatif, déplaçant d’innombrables processus et services en ligne et transformant notre manière de vivre, de travailler et d’interagir. Les organisations doivent équilibrer l’utilité des données avec la conformité réglementaire et les préoccupations de la vie privée. Une solution efficace est le masquage de données statique pour Amazon Redshift. Cette technique aide à protéger les données confidentielles tout en maintenant leur utilité pour le développement et les tests.
Explorons comment le masquage de données statique peut aider à sécuriser votre environnement Amazon Redshift.
Comprendre le Masquage de Données Statique
Qu’est-ce que le Masquage de Données Statique ?
Le masquage de données statique est un processus qui crée une copie masquée séparée des données sensibles. Cette approche garantit que les données originales restent inaltérées tout en fournissant une version sécurisée pour les environnements non-production.
Pourquoi Utiliser le Masquage de Données Statique ?
- Conformité réglementaire (compliance)
- Réduction du risque de violation de données
- Environnements de développement et de test plus sûrs
- Maintien de l’intégrité des données
Capacités d’Amazon Redshift pour le Masquage de Données Statique
Amazon Redshift propose des fonctions intégrées et des fonctions définies par l’utilisateur (UDF) pour mettre en œuvre le masquage de données. Examinons certaines capacités clés.
Les exemples fournis ci-dessus démontrent des techniques de masquage de données mais ne créent pas de tables séparées avec des données masquées. Ces méthodes sont similaires à celles utilisées dans le masquage de données dynamique natif. Pour créer des tables obfusquées permanentes, consultez la section ‘Mettre en œuvre le Masquage de Données Statique’ ci-dessous.
Fonctions Intégrées
Redshift propose plusieurs fonctions intégrées pour des opérations de masquage de base. Une fonction couramment utilisée est REGEXP_REPLACE.
Exemple :
SELECT REGEXP_REPLACE(email, '(.*)@', '****@') AS masked_email FROM users;
Cette requête masque la partie locale des adresses e-mail, en la remplaçant par des astérisques.
Fonctions Définies par l’Utilisateur (UDF)
Pour des exigences de masquage plus complexes, Redshift permet de créer des UDFs en utilisant Python. Voici un exemple d’UDF qui masque les adresses e-mail :
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;Pour utiliser cette fonction :
SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
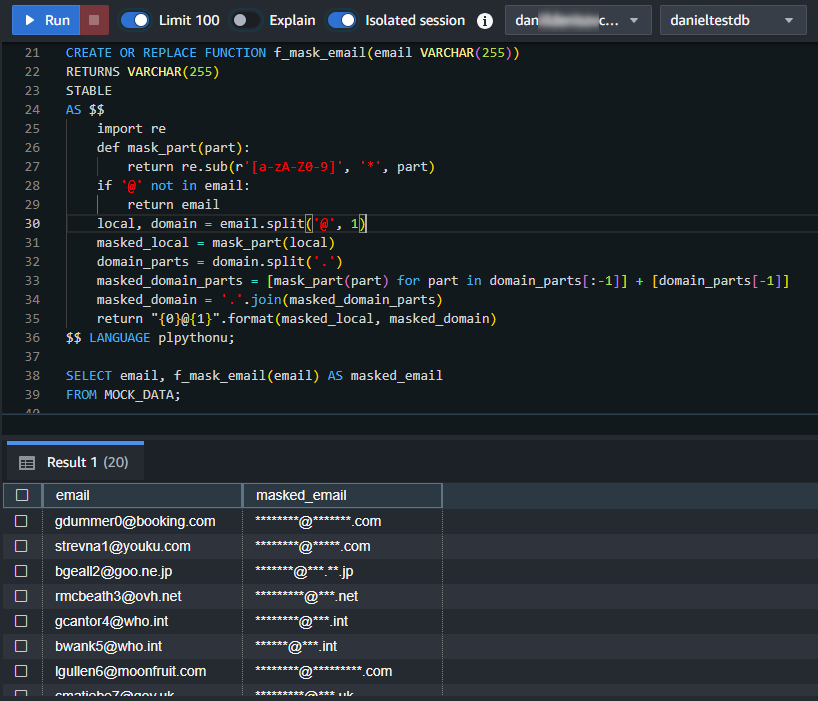
Les fonctions Python améliorent considérablement les capacités de masquage et de traitement des données de Redshift. Elles permettent de mettre en œuvre un chiffrement maintenu par format et des procédures de masquage complexes. Avec Python, vous pouvez créer des algorithmes de masquage personnalisés adaptés à vos besoins spécifiques.
Mettre en Œuvre le Masquage de Données Statique dans Redshift
Maintenant que nous comprenons les bases, examinons comment mettre en œuvre le masquage de données statique dans Redshift.
Étape 1 : Identifier les Données Sensibles
Tout d’abord, identifiez quelles colonnes contiennent des informations sensibles nécessitant un masquage. Cela peut inclure :
- Informations Personnellement Identifiables (PII)
- Données financières
- Dossiers de santé
Étape 2 : Créer des Fonctions de Masquage
Développez des fonctions de masquage pour chaque type de données que vous devez protéger. Nous avons déjà vu un exemple pour les adresses e-mail.
Étape 3 : Créer une Table Masquée
Créez une nouvelle table avec des données masquées :
CREATE TABLE masked_mock_data AS SELECT id, f_mask_email(email) AS email, first_name, last_name FROM Mock_data;
Étape 4 : Vérifier les Données Masquées
Vérifiez les résultats pour assurer un masquage approprié :
SELECT * FROM masked_mock_data;
Masquage de Données Statique avec DataSunrise
Pour utiliser DataSunrise pour le masquage statique :
- Configurer la connexion à votre cluster Redshift
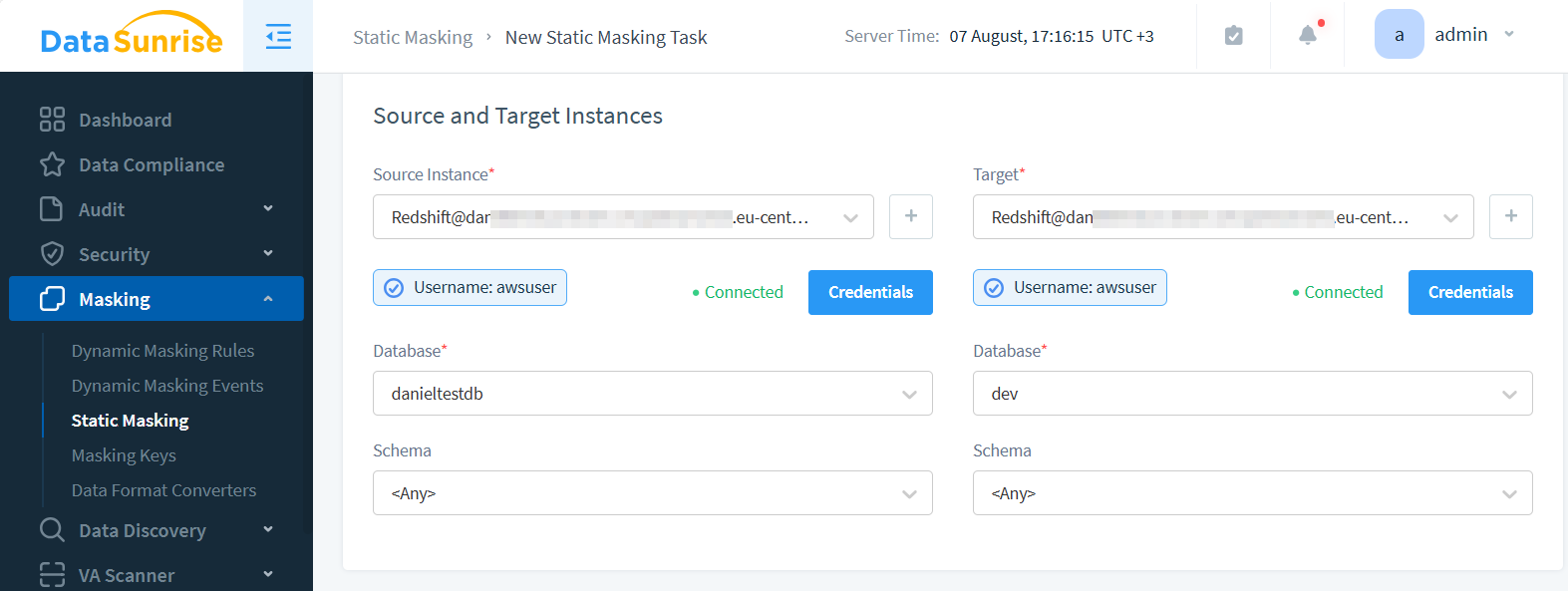
- Créer une tâche de masquage dans l’interface web
- Sélectionner les bases de données source et cible.
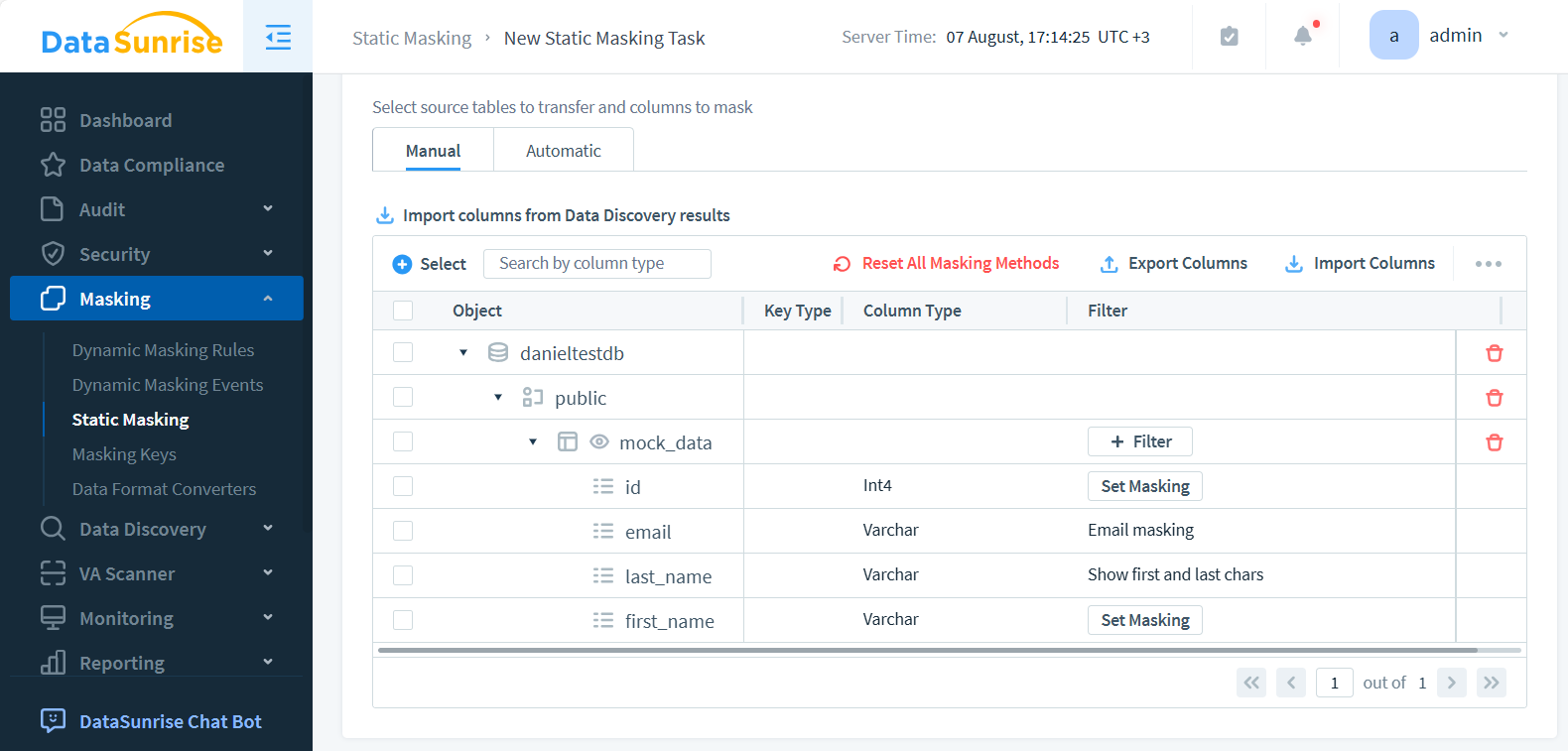
- Sélectionner les objets de la base de données cible à masquer
- Enregistrer et démarrer la tâche
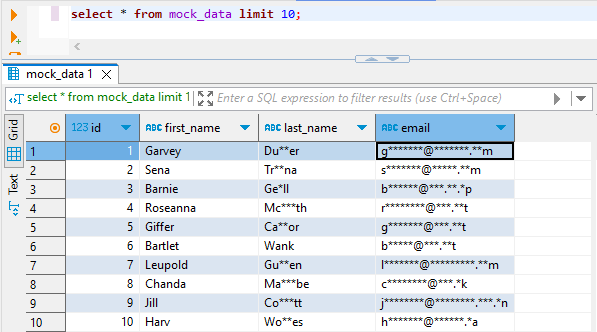
Le résultat dans la table cible peut ressembler à ceci (interrogé dans DBeaver) :
Méthodes de Masquage de DataSunrise
DataSunrise propose une suite complète de techniques de masquage de données. Explorons quelques-unes des méthodes les plus puissantes et couramment utilisées :
- Le Chiffrement Maintenu par Format conserve le format original des données tout en les chiffrant, garantissant que les données restent utilisables après chiffrement. Cela signifie que les valeurs chiffrées ressembleront toujours aux données originales, ce qui facilite leur manipulation et leur analyse. Cela est particulièrement utile dans les situations où le format des données est important pour les processus ou l’affichage.
- La Valeur de Chaîne Fixe est une technique utilisée pour remplacer les données sensibles par une chaîne prédéfinie. Cela peut être utile pour masquer des informations sensibles telles que les numéros de carte de crédit ou les numéros de sécurité sociale. En remplaçant les données réelles par une chaîne fixe, cela protège les informations sensibles contre l’accès ou la visualisation non autorisés.
- La Valeur Nulle est une autre méthode de protection des données sensibles en les remplaçant par une valeur NULL. Cela élimine les informations sensibles de l’ensemble de données, de sorte que personne ne peut accéder aux données originales ou les récupérer. Cette méthode peut ne pas conserver le format des données comme le fait le Chiffrement Maintenu par Format, mais elle protège efficacement les informations sensibles.
DataSunrise offre une large gamme de méthodes de masquage, vous offrant des options flexibles pour protéger vos données sans sacrifier leur utilité. Avec plus de 20 techniques distinctes disponibles, vous pouvez affiner votre stratégie de protection des données pour répondre à des besoins spécifiques.
Avantages du Masquage de Données Statique pour Amazon Redshift
La mise en œuvre du masquage de données statique dans Redshift offre plusieurs avantages :
- Sécurité des données améliorée
- Conformité réglementaire simplifiée
- Réduction du risque d’exposition accidentelle des données
- Amélioration des processus de développement et de test
- Maintien de l’utilité des données
En masquant les données sensibles, vous pouvez partager en toute confiance les informations au sein de votre organisation sans compromettre la sécurité.
Défis et Considérations
Bien que le masquage de données statique soit bénéfique, il existe certains défis à considérer :
- Impact sur les performances pendant le processus de masquage
- Maintien de l’intégrité référentielle dans les données masquées
- Assurer un masquage cohérent entre les tables liées
- Équilibrer l’utilité des données avec les exigences de sécurité
Aborder ces défis nécessite une planification et une mise en œuvre soignées.
Conclusion
Le masquage de données statique pour Amazon Redshift est un outil puissant pour protéger les données sensibles. Les organisations peuvent utiliser des fonctions intégrées et personnalisées. Ces fonctions aident à créer des copies sécurisées et masquées de leurs données. Cela est utile pour les tests et les besoins de développement.
Rappelez-vous, la protection des données est un processus continu. Examinez et mettez régulièrement à jour vos stratégies de masquage pour anticiper les menaces évolutives et les exigences de conformité.
Pour ceux qui cherchent une protection plus avancée et en temps réel, des solutions comme DataSunrise offrent des capacités de masquage des données. DataSunrise fournit des outils conviviaux et à la pointe de la technologie pour la sécurité des bases de données, y compris des fonctionnalités d’audit et de découverte de données. Pour en savoir plus sur la façon dont DataSunrise peut améliorer votre stratégie de protection des données, visitez notre site web pour une démonstration en ligne.
