
Améliorer la Sécurité d’Amazon Redshift avec le Masquage Dynamique des Données
Introduction
Les organisations font face à une pression croissante pour protéger les données personnelles tout en maintenant la conformité réglementaire. C’est là qu’intervient le masquage dynamique des données pour Amazon Redshift – une solution puissante qui aide les entreprises à sécuriser leurs données sans compromettre leur fonctionnalité.
Plongeons dans le monde du masquage dynamique des données et explorons comment il peut révolutionner votre stratégie de sécurité des données.
Selon le Dashboard de la National Vulnerability Database (NVD) Dashboard, en août 2024, 24,457 nouveaux enregistrements de Vulnérabilités et Expositions Communs (CVE) ont été signalés cette année – et nous sommes seulement à mi-chemin.
Cette statistique stupéfiante souligne la nécessité cruciale de mesures robustes de protection des données. Le masquage dynamique des données offre une approche de pointe pour protéger les informations sensibles dans les bases de données Amazon Redshift.
Comprendre les Capacités de Masquage des Données d’AWS Redshift
Amazon Redshift fournit plusieurs fonctions intégrées qui peuvent être utilisées pour un masquage des données de base. Bien que ces fonctions ne soient pas aussi complètes que les solutions de masquage dédiées, elles offrent un point de départ pour protéger les données sensibles.
Données de test
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email) values (6, 'Bartlet', 'Wank', 'bwank5@who.int'); insert into MOCK_DATA (id, first_name, last_name, email) values (7, 'Leupold', 'Gullen', 'lgullen6@moonfruit.com'); insert into MOCK_DATA (id, first_name, last_name, email) values (8, 'Chanda', 'Matiebe', 'cmatiebe7@gov.uk'); …
Utiliser REGEXP_REPLACE
L’une des façons les plus simples de masquer les données dans Redshift est d’utiliser la fonction REGEXP_REPLACE. Cette fonction vous permet de remplacer des parties d’une chaîne en fonction d’un motif d’expression régulière.
Voici un exemple de la façon dont vous pouvez utiliser des restrictions et REGEXP_REPLACE pour masquer une adresse email :
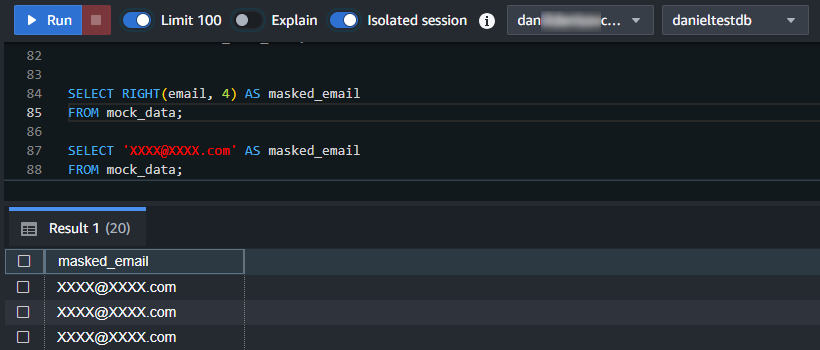
SELECT RIGHT(email, 4) AS masked_email FROM mock_data;
SELECT REGEXP_REPLACE(email, '.', '*') AS masked_email FROM mock_data;
Cette requête remplace tous les caractères d’une adresse e-mail par des caractères ‘*’, laissant visible seulement les quatre derniers caractères.
Ou encore plus simple :
SELECT 'XXXX@XXXX.com' AS masked_email FROM mock_data;
Masquage lors de la création de Vues
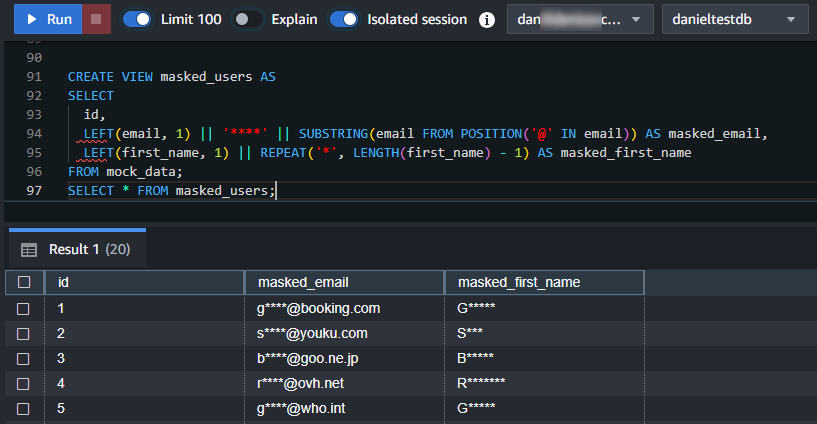
CREATE VIEW masked_users AS
SELECT
id,
LEFT(email, 1) || '****' || SUBSTRING(email FROM POSITION('@' IN email)) AS masked_email,
LEFT(first_name, 1) || REPEAT('*', LENGTH(first_name) - 1) AS masked_first_name
FROM mock_data;SELECT * FROM masked_users;
Tirer Parti des Fonctions Python Intégrées
Redshift prend également en charge les fonctions définies par l’utilisateur (UDF) écrites en Python. Celles-ci peuvent être des outils puissants pour implémenter une logique de masquage plus complexe.
Voici un exemple simple de UDF en Python qui masque une adresse e-mail et des prénoms :
-- Mask Email --
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
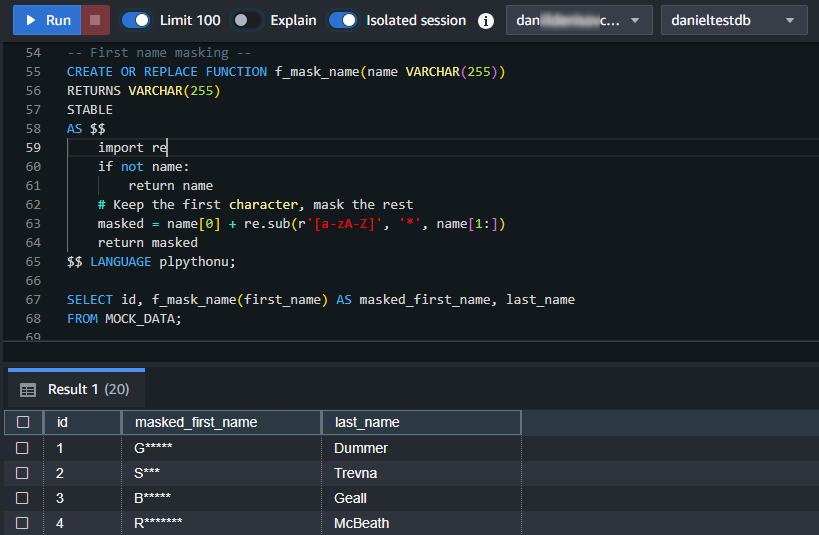
$$ LANGUAGE plpythonu;-- Masquage du Prénom -- CREATE OR REPLACE FUNCTION f_mask_name(name VARCHAR(255)) RETURNS VARCHAR(255) STABLE AS $$ import re if not name: return name # Garder le premier caractère, masquer le reste masked = name[0] + re.sub(r'[a-zA-Z]', '*', name[1:]) return masked $$ LANGUAGE plpythonu;
SELECT id, f_mask_name(first_name) AS masked_first_name, last_name FROM MOCK_DATA;
Créer une Instance DataSunrise pour le Masquage Dynamique des Données
Bien que les capacités intégrées de Redshift offrent un masquage de base, elles manquent de la flexibilité et de la facilité d’utilisation fournies par des solutions spécialisées comme DataSunrise. Explorons comment configurer le masquage dynamique des données en utilisant DataSunrise.
Configurer le Masquage Dynamique des Données
Pour configurer le masquage dynamique des données :
- Dans le tableau de bord, accédez à la section “Masquage”.
- Sélectionnez “Règles de Masquage Dynamique” dans le menu.
- Cliquez sur “Ajouter une Nouvelle Règle” pour créer une règle de masquage.
- Choisissez votre instance de base de données Amazon Redshift dans la liste des bases de données connectées.
- Sélectionnez la table et la colonne que vous souhaitez masquer.
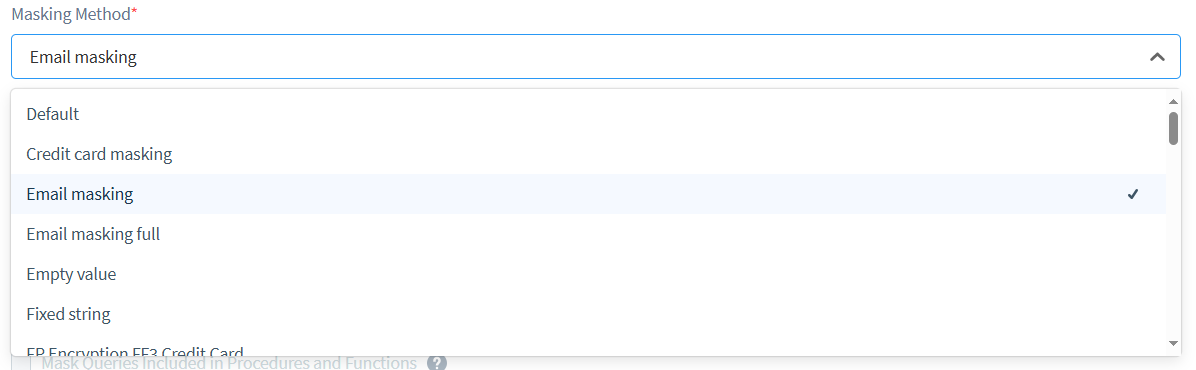
- Choisissez une méthode de masquage (nous en parlerons plus en détail dans la section suivante).
- Enregistrez votre règle et appliquez les modifications.
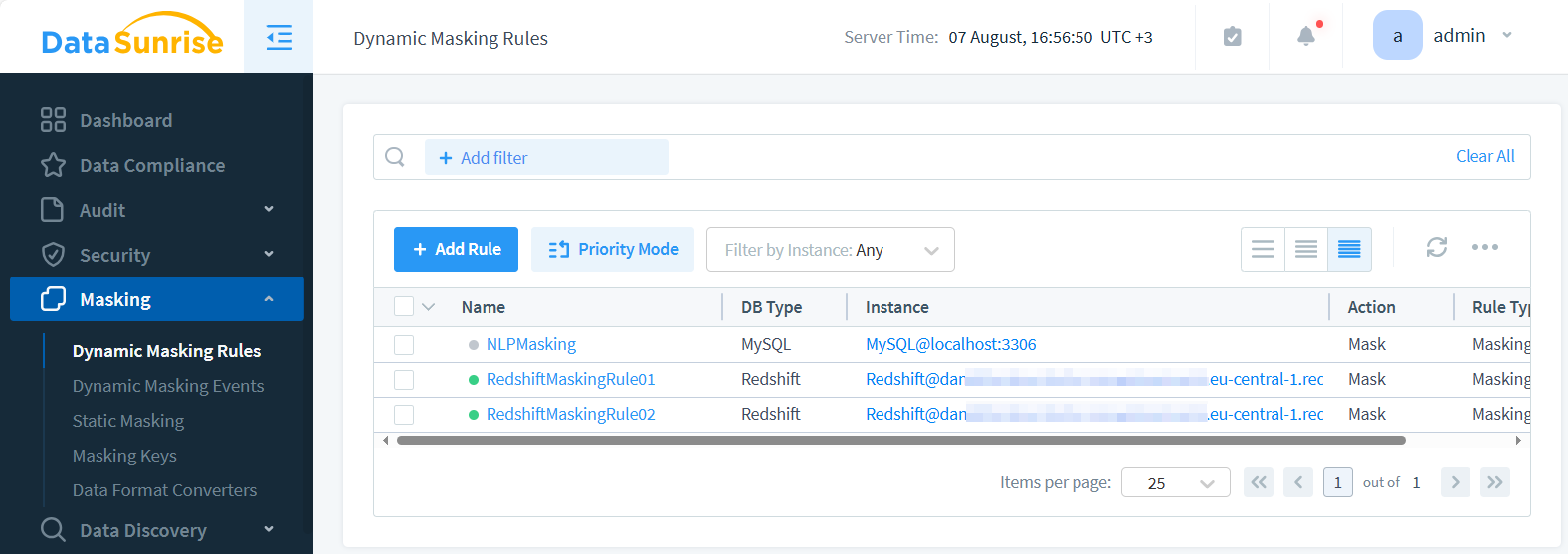
L’image montre deux règles de masquage dynamique. La première règle, étiquetée ‘RedshiftMaskingRule01’, est configurée pour masquer les adresses e-mail. La deuxième règle, ‘RedshiftMaskingRule02’, est configurée pour masquer les prénoms.
Après avoir configuré les règles, vous pouvez exécuter une requête de test pour voir les données masquées dynamiquement en action. L’accès aux données masquées avec DBeaver est illustré ci-dessous.
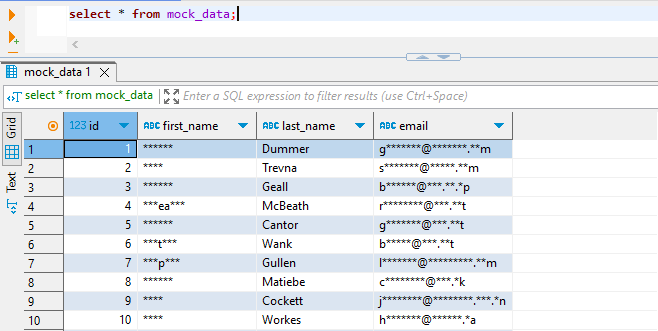
Créer des règles de masquage dynamique avec DataSunrise est remarquablement simple, ne nécessitant que quelques clics. Ce processus simplifié contraste fortement avec les approches natives plus complexes. En outre, cette simplicité d’utilisation s’applique à des dizaines de bases de données et systèmes de stockage pris en charge, offrant une polyvalence et une efficacité sans précédent dans la protection des données.
Exploration des Méthodes de Masquage
DataSunrise propose plusieurs méthodes de masquage pour répondre à différents types de données et exigences de sécurité. Examinons trois approches courantes :
Cryptage avec Préservation du Format (FPE)
FPE est une technique de masquage avancée qui permet de chiffrer les données tout en maintenant leur format d’origine. Cela est particulièrement utile pour les champs comme les numéros de carte de crédit ou de sécurité sociale, où les données masquées doivent conserver la même structure que l’original.
Exemple : Original : 1234-5678-9012-3456 Masqué : 8736-2940-5281-7493
Valeur de Chaîne Fixe
Cette méthode remplace l’ensemble du champ par une chaîne prédéfinie. Elle est simple mais efficace pour les cas où la structure réelle des données n’est pas importante.
Exemple : Original : John Doe Masqué : [REDACTED]
Valeur Null
Parfois, la meilleure façon de protéger les données sensibles est de les masquer entièrement. La méthode de valeur null remplace les données originales par une valeur nulle, les retirant effectivement des résultats de la requête pour les utilisateurs non autorisés.
Exemple : Original : johndoe@example.com Masqué : NULL
DataSunrise offre une diversité de méthodes de masquage, vous fournissant de nombreuses options pour adapter votre stratégie de protection des données :
Avantages du Masquage Dynamique des Données
La mise en œuvre du masquage dynamique des données pour Amazon Redshift offre plusieurs avantages clés :
- Amélioration de la sécurité des données : Protégez les informations sensibles contre les accès non autorisés.
- Conformité réglementaire : Répondez aux exigences des réglementations de protection des données, comme le RGPD et la CCPA.
- Flexibilité : Appliquez des règles de masquage différentes en fonction des rôles des utilisateurs ou des éléments de données spécifiques.
- Intégration transparente : Masquez les données dynamiquement sans modifier la structure sous-jacente de la base de données.
- Amélioration des tests et du développement : Fournissez des données réalistes mais sûres pour les environnements non productifs.
Meilleures Pratiques pour la Mise en Œuvre du Masquage Dynamique des Données
Pour maximiser l’efficacité de votre stratégie de masquage des données :
- Identifiez les données sensibles : effectuez un processus de découverte des données pour localiser toutes les informations sensibles.
- Définissez des politiques claires : Établissez des règles de masquage cohérentes dans toute votre organisation.
- Testez minutieusement : Vérifiez que le masquage ne casse pas la fonctionnalité de l’application.
- Surveillez et auditez : Recherchez régulièrement les règles de masquage et leur efficacité.
- Formez votre équipe : Assurez-vous que toutes les parties prenantes comprennent l’importance du masquage des données et savent comment l’utiliser correctement.
Conclusion
Le masquage dynamique des données pour Amazon Redshift est un outil puissant dans l’arsenal moderne de la sécurité des données. En mettant en œuvre des stratégies de masquage robustes, les organisations peuvent protéger les données sensibles, maintenir la conformité réglementaire et atténuer les risques liés aux violations de données.
À mesure que la protection des données devient de plus en plus critique, des solutions comme DataSunrise offrent des outils conviviaux et de pointe pour une sécurité complète de la base de données. En plus du masquage dynamique des données, DataSunrise propose des fonctionnalités telles que l’audit et la découverte des données, améliorant encore votre capacité à protéger des informations précieuses.
Prêt à porter la sécurité des données d’Amazon Redshift au niveau supérieur ? Visitez le site Web de DataSunrise pour une démo en ligne et découvrez comment nos outils avancés peuvent transformer votre approche de la protection des données.
Suivant
