
Type d’Information : Bases de la Sécurité Inspirée par les Données
Introduction
DataSunrise propose une sécurité inspirée par les données, offrant des capacités uniques et puissantes pour une découverte rapide des données à chaque demande de données pour une source de données donnée. Bien que cette approche crée une certaine surcharge en temps d’exécution, elle offre une protection de base de données extrêmement flexible.
Les types d’information ont été introduits pour la première fois dans DataSunrise avec la fonctionnalité de découverte de données sensibles, qui scanne les bases de données et les systèmes de stockage comme S3 à la recherche de données sensibles.
Les types d’information offrent une fonctionnalité au-delà de la découverte de données de base. Ils permettent la détection de type de données en temps réel et peuvent déclencher automatiquement des règles de protection ou d’audit à travers la sécurité inspirée par les données à chaque requête de base de données. De plus, ils facilitent l’étiquetage des traces d’audit, facilitant ainsi le suivi des événements d’accès aux données spécifiques dans les traces transactionnelles et les fichiers journaux.
Découverte des Types d’Information
Les propriétés des données doivent être stockées dans une entité pour analyse. Parfois, ces données ont une structure stricte avec des noms de colonnes, de tables et des types. D’autres fois, elles peuvent apparaître sous forme de fichiers JSON, CSV, de texte brut, ou même d’images de documents scannés. DataSunrise permet de rechercher toutes ces objets pour des données sensibles.
Cela conduit à des descriptions flexibles des types d’information. Par exemple, les données d’email peuvent avoir plusieurs propriétés :
- Le nom de la colonne contient “email”
- Le nom de la table contient “email”
- Les données correspondent à l’expression régulière “.*@.*“
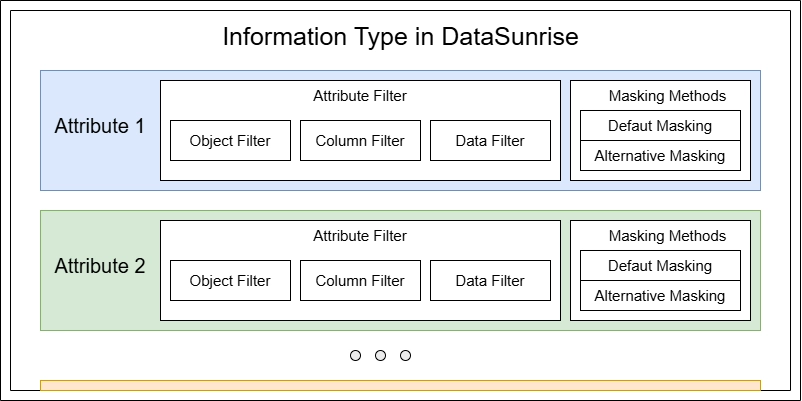
Pour être classifiées comme information d’email, les données doivent répondre à plusieurs exigences. Cela introduit une autre entité importante de DataSunrise appelée Attribut d’Information. Un Type d’Information est essentiellement une collection d’attributs que les données doivent correspondre pour être considérées comme un type spécifique.
Lors de la recherche de données sensibles dans un fichier texte simple sans colonnes ni tables, l’ensemble d’attributs peut être différent. Par exemple, le type d’information d’email en texte brut pourrait seulement nécessiter une correspondance regex, sans attributs supplémentaires nécessaires.
Types d’Information Disponibles dans DataSunrise
DataSunrise inclut de nombreux types d’information intégrés, chacun associé à des normes de sécurité populaires (GDPR, HIPAA, SOX et autres). Bien que cette association ne soit pas obligatoire pour les types personnalisés, elle aide à suivre l’activité et à collecter des données d’utilisation pour les audits de conformité.
Les utilisateurs peuvent créer des types d’information personnalisés, allant de simples à complexes. Le type d’email intégré, par exemple, inclut des attributs qui correspondent aux noms de colonnes et à la correspondance de motifs complexes pour le contenu des emails.
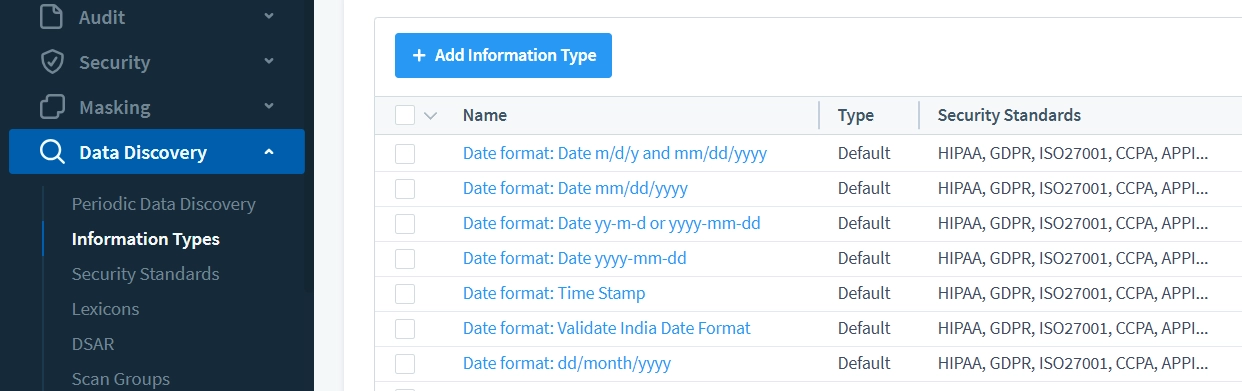
DataSunrise offre plusieurs types d’information date pour s’adapter à diverses conventions de formatage de date. Il est important de noter que différents types d’information peuvent être utilisés pour identifier le même type de données lorsqu’il est stocké dans différents formats.
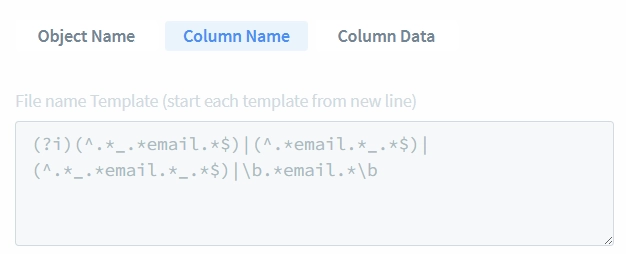
Pour une correspondance plus simple du type d’information, nous recommandons de créer des types personnalisés avec des attributs plus flexibles. Dans notre pratique, la plupart des utilisateurs créent un type de données email personnalisé qui ne nécessite que le contenu des données pour correspondre à un motif d’expression régulière de base tel que “@.*”.
Les types personnalisés vous permettent d’ajouter de nouveaux types d’information pour la détection et de contrôler la rigueur avec laquelle ces types d’information correspondent à vos motifs de données. Vous pouvez créer des types d’information qui nécessitent plusieurs attributs, chacun contenant des noms de colonnes et des motifs de données, ou encore créer des types d’information plus simples avec un seul attribut qui ne vérifie que le motif des données.
Comment Créer un Type d’Information Personnalisé
Étape 1 – Ajouter un Nouveau Type d’Information
- Accédez à Découverte de Données – Types d’Information
- Appuyez sur le bouton “+ Ajouter Type d’Information” et entrez un nom approprié pour votre type d’information personnalisé.
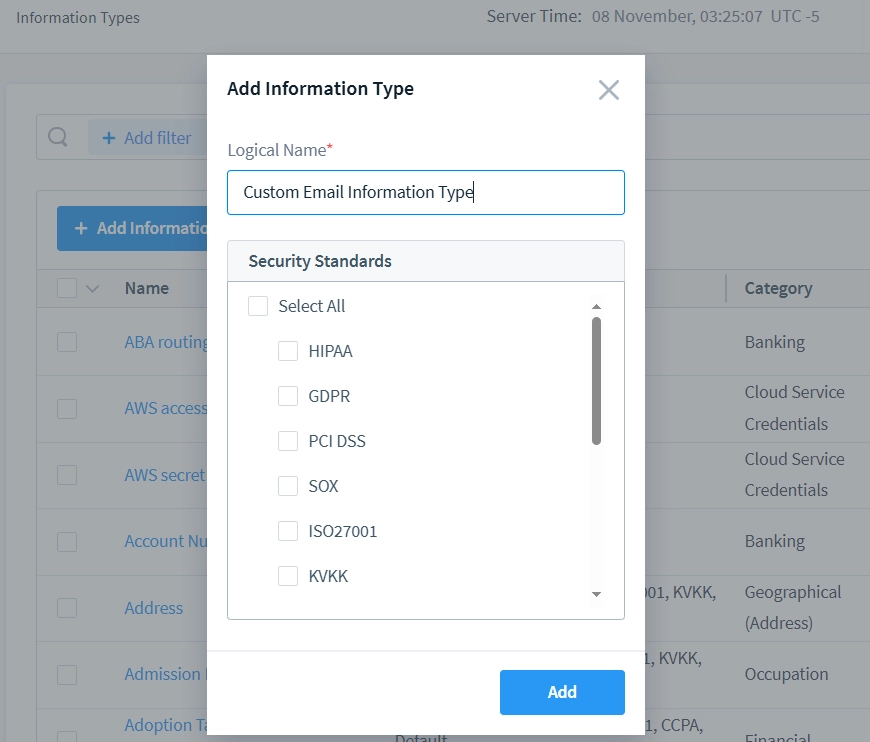
- Après avoir défini le nom du Type d’Information, il apparaîtra dans la liste sur la page “Types d’Information”. Cliquez sur le nouveau Type d’Information pour modifier ses paramètres internes et Attributs. Prenons ‘Type d’Information Email Personnalisé’ comme exemple.
La page d’édition du Type d’Information contient trois sous-sections principales :
- La section Attributs vous permet de définir les paramètres de correspondance réels pour le Type d’Information. Vous pouvez créer un ou plusieurs attributs, et chaque attribut peut contenir des exigences pour l’objet de la base de données, le nom de colonne, et le motif de données. Le Type d’Information correspond si un seul attribut correspond. Pour les attributs inclus, toutes les conditions (objet, motif de nom de colonne, et motif de données) doivent être remplies si spécifiées.
- La section Normes de Sécurité vous permet de lier le Type d’Information à des Normes de Sécurité. Ceci est utilisé par la fonction de Conformité pendant les tâches de découverte, car la fonction de Conformité fonctionne sur la base des normes de sécurité.
- La section Gérer les Étiquettes vous aide à trouver facilement les entrées de journal de règles dans les journaux ou les rapports. Vous pouvez créer des étiquettes personnalisées à cet effet.
Étape 2 – Ajouter un Attribut au Type d’Information
- Créons un attribut simple pour le “Type d’Information Email Personnalisé”. Appuyez sur le bouton “+ Ajouter Attribut” pour commencer. Nous le configurons pour qu’il corresponde aux données qui suivent un motif d’email simple : “.*@.*“
Note : Ce motif est trop simple et correspondra incorrectement à des entrées non valides comme “@.” ou “!!!@…”. Un motif de validation d’email plus robuste devrait être utilisé dans les environnements de production.
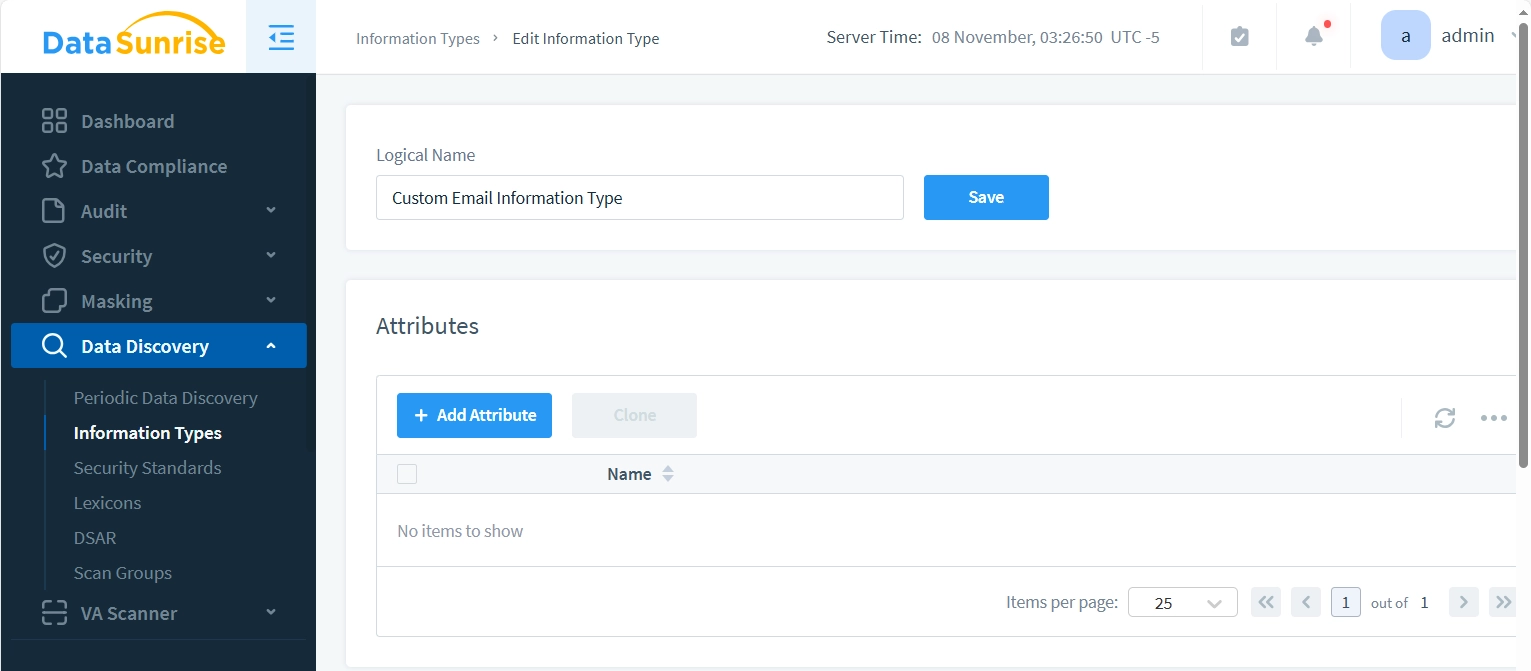
La nouvelle boîte de dialogue d’attribut apparaît avec deux panneaux : “Attribut” à gauche et “Test” à droite. Le panneau Attribut est utilisé pour configurer les paramètres de votre nouvel attribut, tandis que le panneau Test vous permet de vérifier ces paramètres au fur et à mesure que vous les créez.
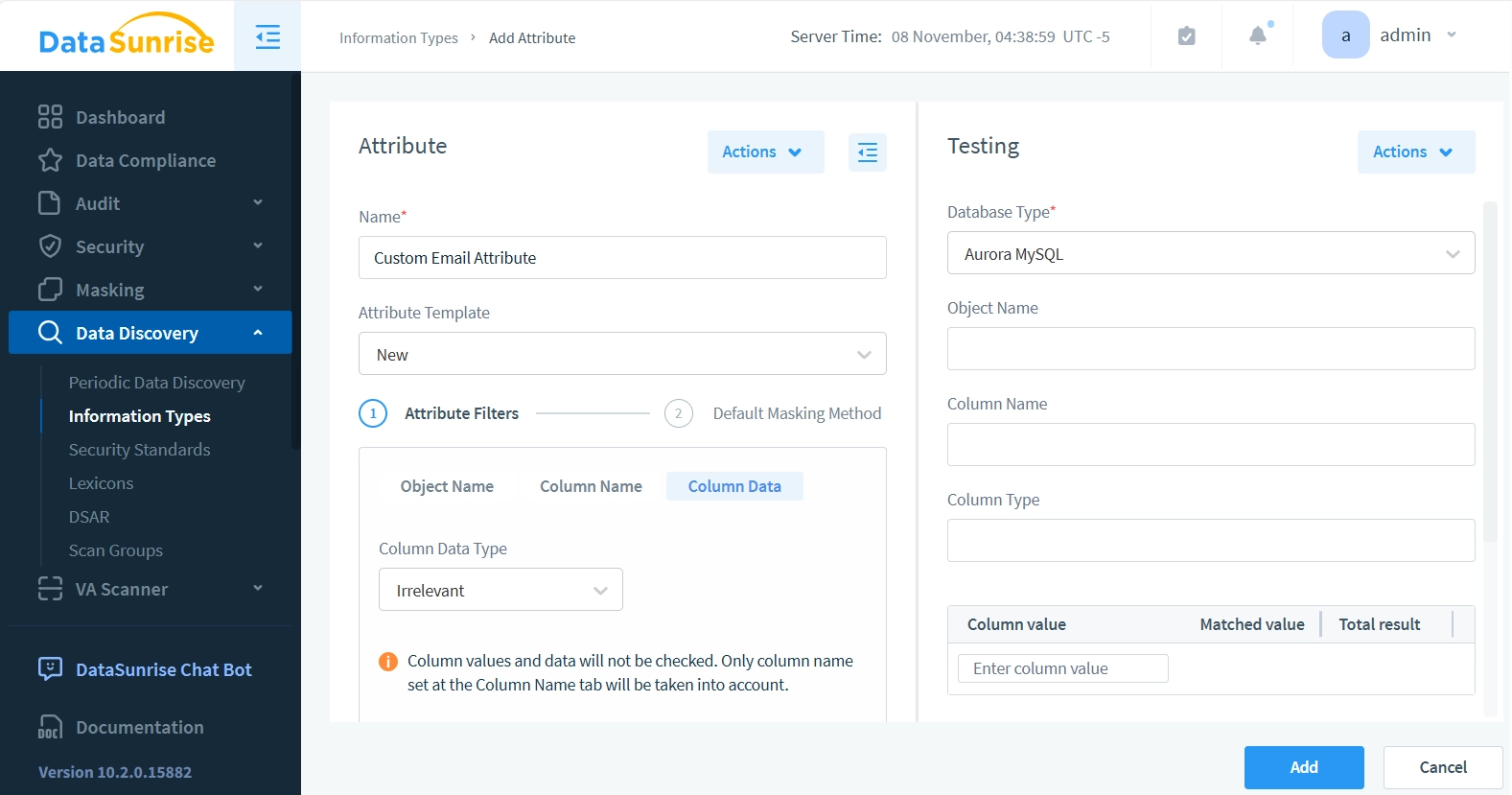
- Dans le panneau “Attribut”, entrez “Attribut Email Personnalisé” dans le champ Nom. Pour le Modèle d’Attribut, nous garderons l’option par défaut “Nouveau”, car nous n’avons pas encore d’autres modèles disponibles.
Ensuite, nous nous concentrerons sur deux points clés : les Filtres d’Attributs et la Méthode de Masquage par Défaut.
- Pour les Filtres d’Attributs, laissez les champs Nom d’Objet et Nom de Colonne inchangés. Cliquez seulement sur l’option Données de Colonne. Cela signifie que notre attribut ignorera les motifs de Nom d’Objet et de Nom de Colonne de la base de données, se concentrant uniquement sur la vérification si la chaîne de données contient un motif de type email (avec un caractère @).
- Définissez le Type de Données de Colonne sur ‘Chaînes Seulement’ et la Méthode de Recherche sur ‘Texte Non Structuré’.
- Entrez “.*@.*” dans le champ “Modèle pour le Contenu de la Colonne (commencez chaque modèle sur une nouvelle ligne)”. Avant de sauvegarder l’attribut ou de l’utiliser dans des règles ou des tâches, nous pouvons tester s’il correspond correctement aux motifs d’email.
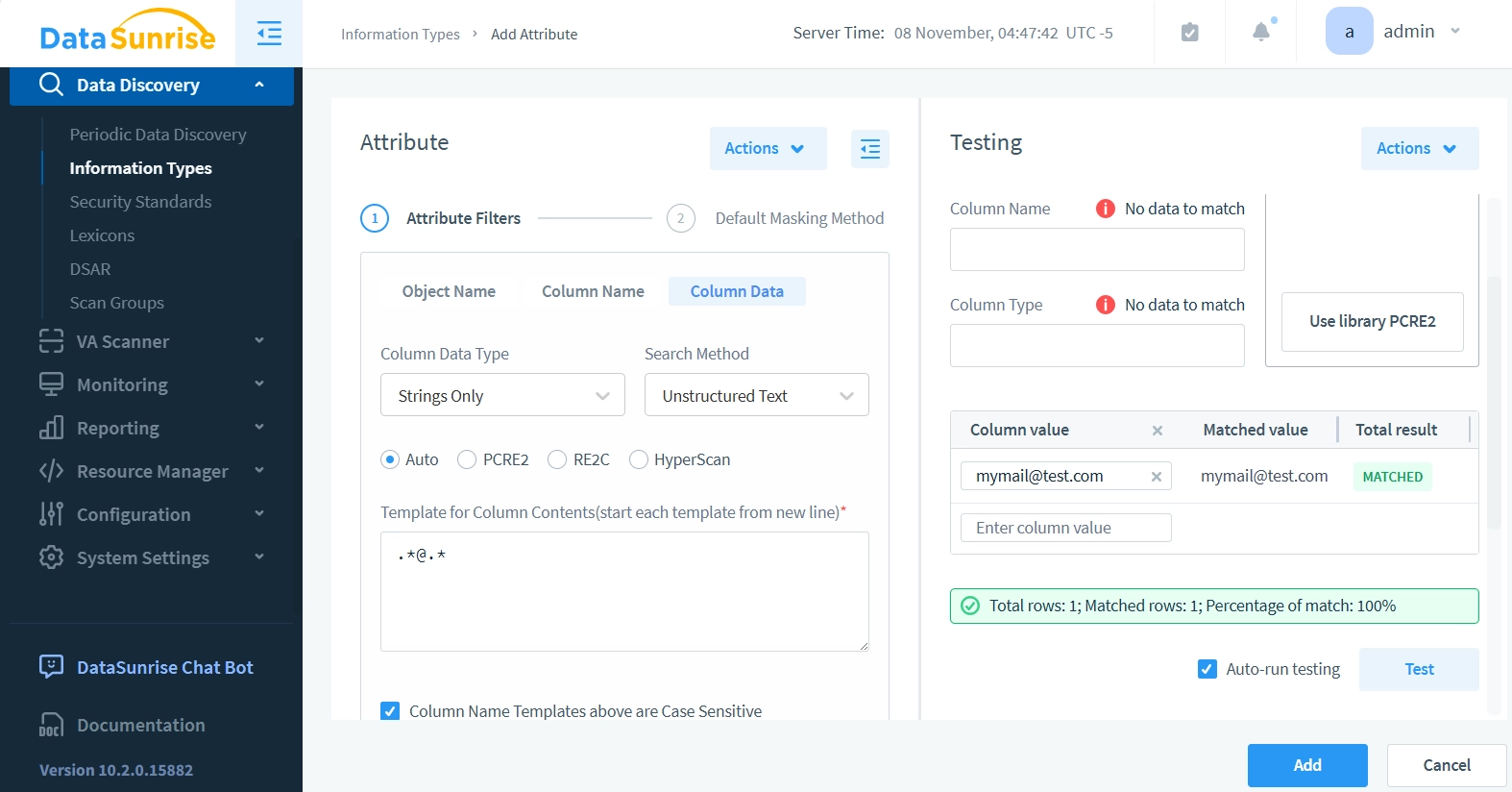
- Maintenant, utilisons le panneau de Test sur la droite. Laissez tous les champs précédents inchangés et entrez un email exemple comme “[email protected]” dans le champ Valeur de la Colonne. Cliquez sur le bouton Test – les résultats devraient montrer que l’Attribut détecte avec succès les emails dans les données de colonne.
Étape 3 – Paramètres de Masquage de l’Attribut
- Cliquez sur ‘2. Méthode de Masquage par Défaut’ pour continuer avec la configuration de la méthode de masquage. Cela fait passer le panneau Attribut à la configuration de masquage.
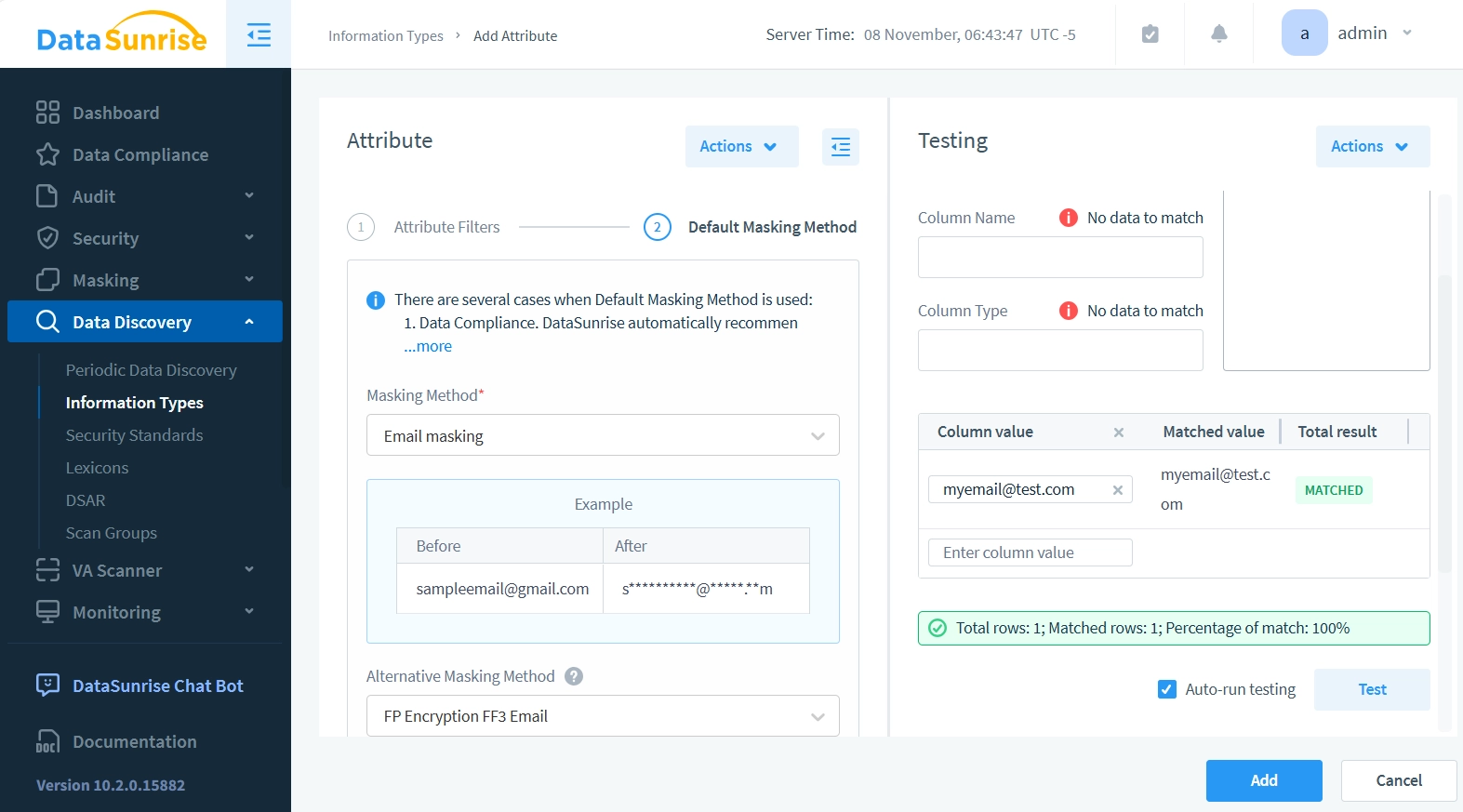
- Définissez la liste déroulante Méthode de Masquage sur Masquage d’Email. La Méthode de Masquage par Défaut est utilisée dans l’outil de Conformité des Données, dans le Masquage Dynamique Inspiré par les Données, et dans le Masquage Statique. DataSunrise applique cette méthode de masquage lorsqu’il n’y a pas de contraintes de clé qui doivent être maintenues pour préserver l’intégrité de la base de données masquée.
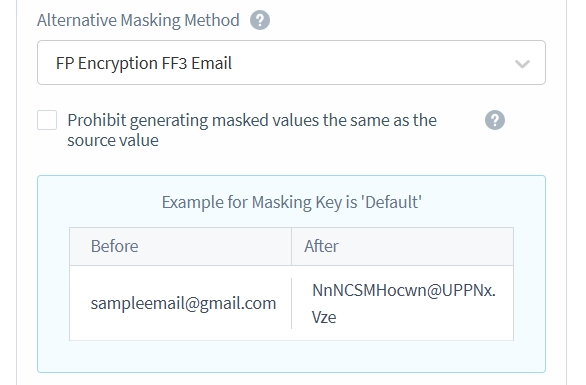
- Définissez la liste déroulante Méthode de Masquage Alternative sur FP Encryption FF3 Email. Les méthodes de masquage alternatives sont nécessaires lors du maintien de l’intégrité référentielle des tables. Vous ne pouvez pas simplement masquer les clés étrangères avec des chaînes aléatoires, car cela casserait les références entre les tables. Le masquage doit garantir que les références des autres tables pointent toujours vers les lignes correctes après que le masquage soit appliqué. De la même manière, les clés primaires doivent rester uniques et maintenir leurs relations référentielles avec les autres tables même après le masquage.
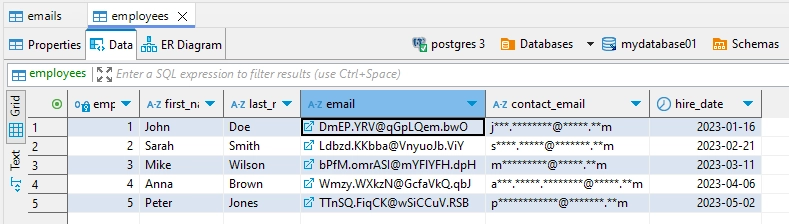
Dans l’exemple de Masquage Statique ci-dessous, les colonnes ’email’ et ‘contact_email’ sont masquées en utilisant différentes méthodes en raison des contraintes de clé. Par exemple, l’adresse e-mail de John Doe, qui a une contrainte de clé étrangère, est masquée comme ‘[email protected]’. Pendant ce temps, son contact_email, sans contraintes, est masqué en utilisant la méthode par défaut, apparaissant comme ‘j***.***@.**m’.
Important : Bien que cette configuration soit compatible avec les bases de données traditionnelles, certains systèmes de stockage comme Amazon S3 et les fichiers texte non structurés ne suivent pas l’organisation typique de la base de données avec des colonnes et des objets. Pour ces types de stockage, faites attention lorsque vous utilisez des filtres de nom d’objet et de colonne, car ils peuvent empêcher une correspondance correcte des données.
- Cliquez sur le bouton ‘Ajouter’ pour lier l’Attribut au Type d’Information.
Tester les Types d’Information avec des Méthodes de Masquage Alternatives
L’exemple suivant montre comment DataSunrise implémente à la fois les méthodes de masquage par défaut et alternatives. Examinons cela à travers la création de tables d’exemple :
-- Création de la table emails (Table parente)
CREATE TABLE emails (
email VARCHAR(50) PRIMARY KEY,
email_type VARCHAR(20),
created_date DATE
);
-- Création de la table employés avec contact_email supplémentaire
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(30),
last_name VARCHAR(30),
email VARCHAR(50),
contact_email VARCHAR(50),
hire_date DATE,
FOREIGN KEY (email) REFERENCES emails(email)
);
-- Insertion de données dans la table emails
INSERT INTO emails VALUES
('[email protected]', 'corporate', '2023-01-15'),
('[email protected]', 'corporate', '2023-02-20'),
…
('[email protected]', 'corporate', '2023-05-01');
-- Insertion de données dans la table employees avec emails de contact
INSERT INTO employees VALUES
(1, 'John', 'Doe', '[email protected]', '[email protected]', '2023-01-16'),
(2, 'Sarah', 'Smith', '[email protected]', '[email protected]', '2023-02-21'),
…
(5, 'Peter', 'Jones', '[email protected]', '[email protected]', '2023-05-02');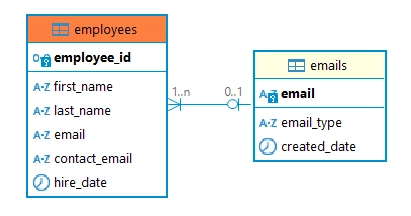
Masquage Statique avec Masquage Par Défaut et Alternatif
Le masquage statique permet aux utilisateurs de masquer automatiquement les données sensibles identifiées lors du processus de découverte. Cette approche automatisée, connue sous le nom de Mode Automatique, détermine quelles tables sources transférer et quelles colonnes masquer. Le système met en œuvre deux stratégies distinctes de masquage : l’une pour les champs de données standard et l’autre pour les éléments de données relationnels (tels que les clés étrangères et les clés primaires). Cette double approche assure la cohérence des données tout en maintenant l’intégrité référentielle à travers les relations de la base de données.
Lors de l’exécution de la tâche de Masquage Statique sur la table ’employees’, différentes méthodes de masquage ont été appliquées aux champs d’email. La colonne ’email’ contrainte, qui sert de clé étrangère, a maintenu son format grâce au Masquage préservé de format. Pendant ce temps, la colonne ‘contact_email’ non contrainte a subi un masquage de caractères simple, où seule la partie centrale des adresses e-mail était masquée.
Conclusion
Cet article a fourni une exploration approfondie des types d’information de DataSunrise. Nous vous avons guidé à travers les étapes principales de la création de types d’information et de la définition de leurs attributs. Les types d’information sont principalement utilisés dans la découverte de données pour identifier les données sensibles basées sur des propriétés spécifiques définies par leurs attributs. De plus, ces types d’information sont activement utilisés lors de l’accès aux données à travers une fonctionnalité appelée Sécurité Inspirée par les Données, qui permet le masquage des données, le blocage et l’étiquetage des journaux d’événements.
Nous avons également examiné des cas d’utilisation pour le masquage par défaut et discuté de la manière dont des méthodes de masquage alternatives peuvent être appliquées lorsque des tâches de masquage statique rencontrent des contraintes de clé dans la base de données masquée.
