
Les Meilleurs Outils d’Analyse de Données pour Une Meilleure Prise de Décision

Introduction
Dans l’environnement commercial rapide et axé sur les données d’aujourd’hui, les organisations collectent et stockent des quantités massives de données. Les données à grande échelle sont des informations importantes qui aident les entreprises à prendre de meilleures décisions, à améliorer leurs opérations, et à devancer leurs concurrents. Cependant, pour débloquer la pleine valeur de vastes quantités de données, les organisations ont besoin d’outils et de solutions d’analyse de données puissants.
Cet article expliquera les bases des outils d’analyse de données, y compris le Big Data, les outils d’analyse populaires et les solutions open-source. Nous explorerons les avantages de l’utilisation de ces outils et vous aiderons à choisir la meilleure solution pour votre organisation. Vous comprendrez comment ces outils peuvent aider votre organisation à utiliser les données pour réussir.
Qu’est-ce que le Big Data?
Les organisations collectent une quantité substantielle de données, connue sous le nom de Big Data, à partir de sources telles que les réseaux sociaux, les capteurs, et les systèmes transactionnels. Ces données sont souvent trop volumineuses et complexes pour que les outils de traitement de données traditionnels puissent les gérer efficacement. Les trois principales caractéristiques des données à grande échelle sont :
- Volume : La quantité même de données collectées et stockées.
- Vitesse : Le taux de production et de traitement des données.
- Variété : Les différents types de données, y compris les données structurées, semi-structurées, et non structurées.
Les organisations ont besoin d’outils d’analyse de données avancés pour extraire de la valeur de grands volumes de données. Ces outils aident à traiter et analyser de grandes quantités d’informations rapidement et efficacement. Ces outils aident les entreprises à trouver des motifs et des tendances dans leurs données, donnant des informations importantes pour prendre des décisions stratégiques.
L’Importance de l’Analyse de Big Data
L’analyse de Big Data est devenue de plus en plus cruciale pour les organisations dans diverses industries. En tirant parti de la puissance des données, les entreprises peuvent :
- Améliorer la compréhension du client : Analyser le comportement, les préférences et les commentaires des clients afin de développer des stratégies marketing ciblées et des expériences personnalisées.
- Optimiser les opérations : Identifier les inefficacités, rationaliser les processus, et réduire les coûts en analysant les données opérationnelles.
- Renforcer la gestion des risques : Détecter et prévenir la fraude, surveiller la conformité, et atténuer les risques en analysant les données financières et transactionnelles.
- Stimuler l’innovation : Devancer les concurrents en étudiant les tendances du marché et les besoins des clients. Utiliser ces informations pour trouver de nouvelles opportunités et créer de nouveaux produits et services.
À mesure que les données augmentent en taille et en complexité, l’utilisation d’analyses de données avancées devient plus cruciale. Les organisations doivent investir dans les bons outils et solutions pour suivre cette tendance.
Outils d’Analyse de Données
Les outils d’analyse de données sont des applications logicielles qui aident les organisations à traiter, visualiser, et interpréter leurs données. Ces outils peuvent varier des applications de tableur simples aux solutions complexes de niveau entreprise. Parmi les outils d’analyse de données populaires, on trouve :
- Microsoft Excel : Excel est un programme largement utilisé pour créer des tableaux croisés dynamiques et des graphiques pour analyser les données. Efficace pour les petits ensembles de données et les analyses de base, il peut avoir des difficultés avec des ensembles de données plus grands et plus complexes. Par exemple, pour créer un tableau croisé dynamique dans Excel, il suffit de choisir vos données, d’aller à l’onglet “Insertion” et de cliquer sur “Tableau croisé dynamique”.
- Tableau : Tableau est facile à utiliser pour créer des tableaux de bord et des rapports interactifs sans nécessiter de connaissances en programmation. Il se connecte à différentes sources de données, ce qui permet aux utilisateurs d’explorer et d’analyser leurs données facilement.
- Python : Python est un langage de programmation commun pour l’analyse de données. Il dispose de bibliothèques comme NumPy, Pandas, et Matplotlib qui aident à la manipulation des données, l’analyse statistique et les projets d’apprentissage automatique. Exemple :
- R : Un langage de programmation statistique largement utilisé dans le domaine académique et industriel pour l’analyse de données et l’apprentissage automatique. R offre une vaste gamme de packages pour la manipulation des données, la visualisation et la modélisation statistique. Exemple :
- Apache Spark : Un système de calcul distribué open-source qui peut traiter de grands ensembles de données à travers des clusters d’ordinateurs. Spark fournit des API en Java, Scala, Python et R, ce qui le rend accessible à une large gamme d’utilisateurs. Exemple : Pour utiliser Spark pour le traitement des données, vous devrez configurer un cluster Spark et écrire du code en utilisant l’une des API prises en charge. Voici un exemple simple utilisant PySpark :
import pandas as pd
data = pd.read_csv('sales_data.csv')
total_sales = data['revenue'].sum()
print(f"Total sales: ${total_sales:.2f}")Ce code Python utilise la bibliothèque Pandas pour lire un fichier CSV contenant des données de vente, calculer les ventes totales, et afficher le résultat.
library(ggplot2)
data <- read.csv("sales_data.csv")
ggplot(data, aes(x = product, y = revenue)) +
geom_bar(stat = "identity", fill = "steelblue") +
labs(title = "Sales by Product", x = "Product", y = "Revenue")Ce code R utilise le package ggplot2 pour créer un graphique en barres visualisant le revenu des ventes par produit.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("SalesAnalysis").getOrCreate()
data = spark.read.csv("sales_data.csv", header=True, inferSchema=True)
total_sales = data.agg({"revenue": "sum"}).collect()[0][0]
print(f"Total sales: ${total_sales:.2f}")Ce code PySpark lit un fichier CSV, calcule les ventes totales, et affiche le résultat.
Ces outils peuvent effectuer des tâches de base comme l’exploration des données et la création de graphiques. Ils peuvent également traiter des tâches plus avancées comme l’analyse statistique et l’utilisation de l’apprentissage automatique. En utilisant ces outils, les organisations peuvent mieux comprendre leurs données et prendre des décisions plus intelligentes.
Solutions d’Analyse de Données Open-Source
Des outils d’analyse de données open-source gratuits offrant des capacités puissantes sont disponibles, en plus des options commerciales. Parmi les solutions d’analyse de données open-source populaires, on trouve :
- Apache Hadoop : Un système qui stocke et traite de grandes quantités de données à travers plusieurs groupes de matériel de base. Hadoop se compose de deux composants principaux : HDFS (Hadoop Distributed File System) pour le stockage et MapReduce pour le traitement. Exemple : Pour analyser des données avec Hadoop, vous pouvez écrire des jobs MapReduce en Java ou utiliser des outils comme Hive ou Pig. Voici un exemple simple d’un job MapReduce qui compte les occurrences de chaque mot dans un fichier texte :
- Kibana : Kibana est un outil gratuit compatible avec Elasticsearch. Il permet aux utilisateurs de visualiser leurs données à travers des tableaux de bord interactifs. Les utilisateurs peuvent créer des graphiques, des cartes et des tableaux, et filtrer les données en temps réel.
- PostgreSQL : Un système de gestion de bases de données relationnelles open-source puissant qui prend en charge des capacités avancées d’analyse de données, telles que les fonctions de fenêtre et les requêtes récursives. PostgreSQL est réputé pour sa fiabilité, ses performances et son extensibilité. Exemple :
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Ce code Java définit un job MapReduce qui compte les occurrences de chaque mot dans un fichier texte. Le mapper tokenise le texte d’entrée et émet des paires (mot, 1), tandis que le reducer somme les comptes pour chaque mot.
Pour créer un tableau de bord dans Kibana, allez d’abord dans l’onglet “Tableau de bord”. Ensuite, cliquez sur “Créer un nouveau tableau de bord”. Enfin, ajoutez des visualisations en cliquant sur “Ajouter”. Vous pouvez personnaliser et enregistrer le tableau de bord pour une utilisation future.
SELECT product_id, SUM(quantity) AS total_quantity, SUM(price * quantity) AS total_revenue FROM sales GROUP BY product_id ORDER BY total_revenue DESC LIMIT 10;
Cette requête SQL calcule la quantité totale et le revenu pour chaque produit. Elle trie ensuite les résultats par revenu et affiche les 10 meilleurs produits.
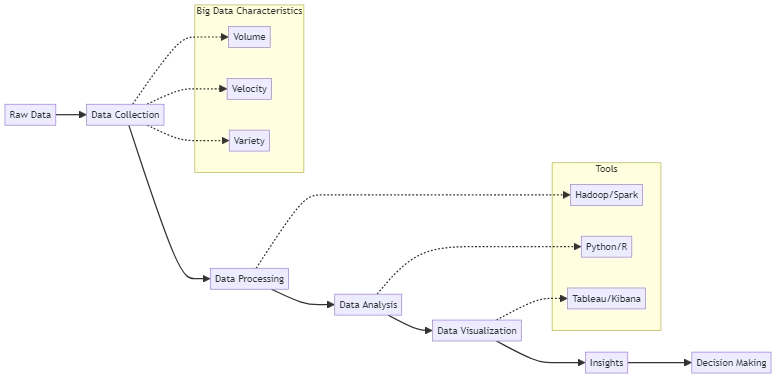
Processus d’Analyse de Données
Ces solutions open-source permettent aux organisations d’opter pour des options d’analyse de données flexibles, évolutives et rentables. En utilisant ces outils, les entreprises peuvent obtenir des informations précieuses sans avoir besoin de licences commerciales coûteuses.
Avantages de l’Utilisation des Outils d’Analyse de Données
Investir dans des outils d’analyse de données offre de nombreux avantages aux organisations, notamment :
- Amélioration de la prise de décision : Ces outils aident les organisations à prendre de meilleures décisions en fournissant des informations basées sur les données.
- Efficacité accrue : Les outils d’analyse de données automatisent et rationalisent les tâches de traitement et d’analyse de données, économisant du temps et des ressources.
- Compréhension accrue des clients : L’analyse des données clients aide les organisations à mieux comprendre leur public cible, permettant des stratégies de marketing et de personnalisation plus efficaces.
- Avantage concurrentiel : L’utilisation d’outils d’analyse de données permet aux organisations d’identifier les tendances, les opportunités et les risques avant leurs concurrents, offrant un avantage stratégique.
- Économies de coûts : En optimisant les opérations, en réduisant le gaspillage, et en identifiant les domaines à améliorer, les outils d’analyse de données peuvent aider les organisations à réduire les coûts et à augmenter la rentabilité.
À mesure que les données augmentent, l’utilisation d’outils d’analyse devient plus importante pour permettre aux organisations de rester compétitives dans un monde axé sur les données.
Choisir le Bon Outil d’Analyse de Données
Choisir le bon outil d’analyse de données pour votre organisation peut être difficile en raison des nombreuses options disponibles. Lors de l’évaluation des différentes options, considérez les facteurs suivants :
- Évolutivité : L’outil peut-il gérer le volume, la vitesse et la variété de vos données ? Assurez-vous que la solution que vous choisissez peut évoluer pour répondre à vos besoins actuels et futurs.
- Facilité d’utilisation : L’outil est-il convivial et accessible aux utilisateurs non techniques ? Considérez la courbe d’apprentissage et si l’outil propose des interfaces et des visualisations intuitives.
- Intégration : L’outil s’intègre-t-il à vos sources de données et systèmes existants ? Assurez-vous que la solution peut se connecter sans problème à votre infrastructure de données et à vos flux de travail.
- Coût : Quel est le coût total de possession, y compris les licences, le matériel et la maintenance ? Considérez à la fois les coûts initiaux et continus lors de l’évaluation des différentes options.
- Communauté et support : Existe-t-il une communauté active et un support fiable pour l’outil ? Une communauté d’utilisateurs forte et un support réactif peuvent être inestimables lors de la mise en œuvre et de l’utilisation d’une solution d’analyse de données.
Pour trouver le meilleur outil d’analyse de données pour votre organisation, évaluez vos besoins et comparez les différentes options. Cela vous aidera à maximiser le potentiel de vos données.
Conclusion
Les outils d’analyse de données sont essentiels pour les organisations cherchant à tirer parti de la puissance du Big Data. En utilisant ces outils, les entreprises peuvent obtenir des insights précieux, prendre des décisions basées sur les données, et améliorer leur performance globale.
Lorsque vous commencez votre parcours d’analyse de données, il est important de bien comprendre vos objectifs. Vous devez également considérer les différentes options disponibles. Au fur et à mesure que vous accumulez des connaissances, soyez prêt à ajuster votre approche en conséquence. En faisant cela, vous serez capable de tirer pleinement parti de vos données et d’aider votre organisation à réussir.
