
Qdrant Trace de Vérification des Données

Introduction
Les bases de données vecteurs telles que Qdrant manquent souvent de traces de vérification des données robustes. Pourtant, ces bases de données traitent des informations sensibles pour les applications d’apprentissage automatique, de traitement du langage naturel (NLP) et de recherche basée sur l’IA. Les organisations dépendent de Qdrant pour l’optimisation de la recherche, la recherche sémantique, et les moteurs de recommandation. Cela rend la mise en œuvre d’une trace de vérification des données Qdrant essentielle pour protéger vos données.
Une trace de vérification des données complète de Qdrant suit qui accède à vos données, quels changements ils effectuent, et quand ces actions ont lieu. Sans mécanismes de vérification adaptés, les organisations risquent de violer les régulations de la confidentialité comme le RGPD et HIPAA. Ces lois exigent une protection stricte des informations sensibles, rendant les traces de vérification des données cruciales pour la conformité.
Importance de la Trace de Vérification des Données Qdrant
Qdrant stocke les embeddings vecteurs comme des représentations mathématiques plutôt que des identifiants personnels directs. Cependant, ces embeddings nécessitent toujours un suivi attentif via des traces de vérification des données. Le Groupe de travail de l’Article 29, Opinion 05/2014 prévient que les données transformées nécessitent une protection lorsque celles-ci peuvent aider à identifier des individus par inférence ou par combinaison de données.
La norme ISO/IEC 27701:2019 sur la confidentialité renforce cette exigence. Elle guide les organisations à protéger les transformations mathématiques des données personnelles comme les informations originales. Cela rend la maintenance d’une trace de vérification des données Qdrant vitale pour la sécurité et la conformité.
La violation de données de 2017 chez Equifax démontre pourquoi les organisations ont besoin de traces de vérification des données robustes. Une surveillance inadéquate des accès aux données a mené à une violation affectant 147 millions de personnes et un règlement de 425 millions de dollars. L’Article 30 du RGPD exige désormais des organisations de consigner toutes les activités de traitement des données. Cela inclut la surveillance des données transformées comme les embeddings vecteurs à travers des traces de vérification des données Qdrant complètes.
Capacités de Journalisation Natives de Qdrant
Qdrant est une puissante base de données vecteur, mais elle manque de capacités de journalisation de vérification natives et complètes. À ce jour, Qdrant n’a pas de fonctionnalités spécifiques à l’audit intégrées. Les journaux système disponibles sont basiques et principalement conçus pour le débogage, fournissant des détails minimes sur les actions des utilisateurs, l’accès aux données, ou les modifications de données. S’appuyer sur ces journaux système en tant que trace de vérification ne satisferait pas les exigences réglementaires ou ne fournirait pas le niveau de détail nécessaire pour la sécurité des données et la conformité.
En raison de cela, les organisations souhaitant s’assurer de leur conformité avec les régulations devront probablement mettre en œuvre des solutions personnalisées ou des outils tiers pour garantir que toutes les activités pertinentes, telles que les modifications de données, les tentatives d’accès, et les exécutions de requêtes, soient correctement enregistrées.
Exemple d’Implémentation du Suivi des Recherches
Une approche de base pour implémenter des traces de vérification dans Qdrant pourrait impliquer d’envelopper le client Qdrant pour capturer les journaux d’audit pour les opérations de la base de données. Voici un exemple de la façon dont on pourrait implémenter un emballage pour suivre l’opération de recherche :
from qdrant_client import QdrantClient
from datetime import datetime
import json
from pathlib import Path
class AuditedQdrantClient:
def __init__(self, host='localhost', port=6333, log_file='logs/qdrant_audit.jsonl'):
self.client = QdrantClient(host=host, port=port)
self.log_file = log_file
# Créer un répertoire de journaux si nécessaire
Path(self.log_file).parent.mkdir(parents=True, exist_ok=True)
def log_operation(self, operation_details: dict):
# Ajouter un horodatage
operation_details["timestamp"] = datetime.now().isoformat()
# Enregistrer sur la console
print(f"Audit log: {json.dumps(operation_details, indent=2)}")
# Enregistrer dans un fichier
with open(self.log_file, 'a') as f:
json.dump(operation_details, f)
f.write('\n')
def search(self, collection_name: str, query_vector: list, **kwargs):
start_time = datetime.now()
try:
results = self.client.search(
collection_name=collection_name,
query_vector=query_vector,
**kwargs
)
self.log_operation({
"operation": "search",
"collection": collection_name,
"parameters": {
"vector_size": len(query_vector),
"limit": kwargs.get('limit', None),
"other_params": kwargs
},
"results_count": len(results),
"status": "success",
"duration_ms": (datetime.now() - start_time).total_seconds() * 1000
})
return results
except Exception as e:
self.log_operation({
"operation": "search",
"collection": collection_name,
"status": "error",
"error": str(e),
"duration_ms": (datetime.now() - start_time).total_seconds() * 1000
})
raise`
Ce wrapper de base enregistrera toutes les opérations de recherche qui y ont été exécutées, y compris les paramètres de la requête, le nombre de résultats, le temps d’exécution et le statut (réussite ou erreur).
Exemple de Script de Test
Pour tester cette implémentation, vous pouvez utiliser le script suivant, qui ajoutera quelques points, effectuera une recherche basique et appellera le script d’audit pour enregistrer l’opération de recherche dans un fichier JSON :
`from qdrant_audit import AuditedQdrantClient
# Créer un client avec la journalisation activée
client = AuditedQdrantClient(log_file='logs/qdrant_audit.jsonl')
try:
# Obtenir des informations sur la collection
collection_info = client.client.get_collection("test_collection")
print("Informations sur la collection:", collection_info)
# Ajouter quelques points de test
client.client.upsert(
collection_name="test_collection",
points=[
{"id": 1, "vector": [0.1, 0.2, 0.3], "payload": {"description": "point de test 1"}},
{"id": 2, "vector": [0.2, 0.3, 0.4], "payload": {"description": "point de test 2"}}
]
)
print("Points de test ajoutés")
# Faire une recherche
results = client.search(
collection_name="test_collection",
query_vector=[0.1, 0.2, 0.3],
limit=10
)
print("Résultats de recherche:", results)
except Exception as e:
print(f"Erreur: {e}")`
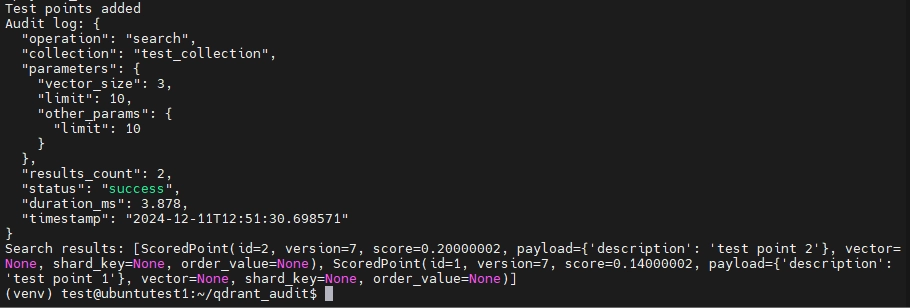
Voici un aperçu de l’exécution réussie du script :
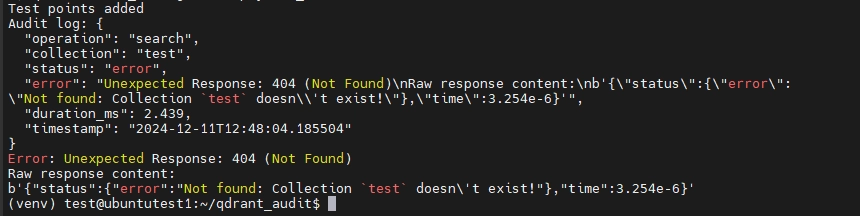
Nous pouvons également essayer de modifier la requête de test dans le script pour effectuer une opération sur une collection inexistante afin de voir si cela enregistrerait également les requêtes infructueuses.
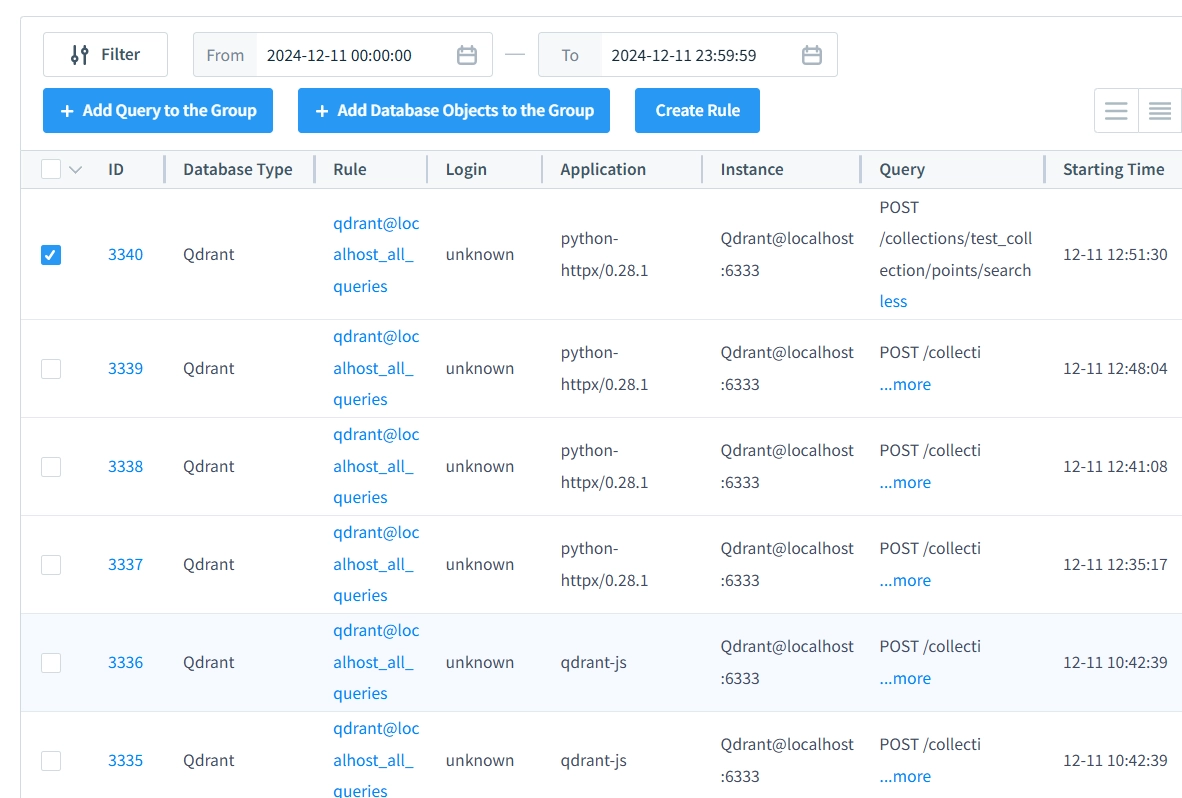
Maintenant, que nous avons à la fois des tentatives de recherche échouées et réussies, nous pouvons essayer d’accéder aux journaux :
cat logs/qdrant_audit.jsonl | jq '.'
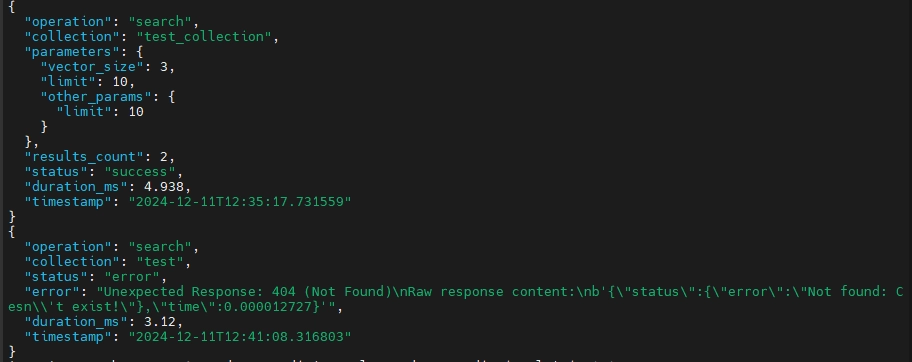
En résumé, ce script enregistre les opérations de recherche, mais il ne capture que les détails spécifiques définis dans son implémentation et limité à son champ d’action opérationnel. Si vous souhaitez inclure des détails supplémentaires, tels que l’adresse IP du client ou des métadonnées plus larges, ou si vous souhaitez auditer d’autres opérations comme upsert, delete, ou create_collection, vous devrez étendre le script avec une logique supplémentaire ou envelopper ces méthodes individuellement.
Répondre aux Limitations d’Audit
Alors que cette implémentation personnalisée peut démontrer comment on pourrait mettre en œuvre des traces de vérification basiques dans Qdrant pour les opérations de recherche, elle présente néanmoins des limitations significatives :
- Couverture Limitée : Seule l’opération de recherche est suivie. D’autres actions telles que
upsert,delete, etcreate_collectionnécessitent des emballages supplémentaires. - Client-Specifique : Pour garantir l’audit, toutes les interactions avec Qdrant doivent passer par cet emballage. Si un autre développeur utilise directement le
QdrantClientpar défaut, ces opérations ne seront pas enregistrées. - Maintenance Manuelle : Construire un système d’audit complet nécessiterait un effort important pour suivre toutes les opérations et maintenir le code de l’emballage.
Pour surmonter ces limitations, les organisations pourraient envisager :
1. Solutions Personnalisées
- Développer des collecteurs de journaux adaptés pour Qdrant.
- Créer des bases de données d’audit centralisées pour la conformité.
- Construire des outils de reporting personnalisés pour la conformité et la détection d’anomalies.
2. Intégration Tierce
- Exploiter des plateformes de gestion des journaux pour le stockage centralisé et le traitement.
- S’intégrer à des systèmes SIEM pour la surveillance en temps réel et les alertes.
- Utiliser des outils de suivi de la conformité pour garantir le respect des exigences réglementaires.
3. Modifications Architecturales
- Implémenter des couches proxy pour capturer des journaux détaillés de toutes les demandes des utilisateurs.
- Introduire des services d’authentification et d’autorisation pour suivre les contrôles d’accès.
- Construire des services de journalisation d’audit dédiés pour capturer et analyser les changements en temps réel.
Pourquoi DataSunrise est la Solution Parfaite pour Qdrant
Tandis que des solutions personnalisées et des intégrations tierces peuvent aider à relever les limitations d’audit dans Qdrant, une option plus intégrée et efficace est l’intégration de DataSunrise avec Qdrant. DataSunrise offre une solution d’audit de données complète qui peut suivre toutes les interactions avec la base de données, assurant la conformité avec les réglementations et renforçant la sécurité des données.
DataSunrise offre une vaste gamme de capacités d’audit, y compris :
- Suivi Complet des Modifications de Données : Surveille toutes les modifications de données, y compris les insertions, mises à jour, et suppressions.
- Attribution Utilisateur Complète : Suivre les IDs de sessions, rôles des utilisateurs, et détails des applications.
- Journalisation en Temps Réel des Requêtes : Capture le cycle de vie complet des requêtes, depuis l’exécution jusqu’aux résultats.
- Surveillance des Accès : Consigne toutes les tentatives d’accès, qu’elles soient réussies ou non, ainsi que les actions associées.
- Conformité Réglementaire : Assure la conformité avec le RGPD, HIPAA, et d’autres normes de protection des données.
Avec DataSunrise, les organisations peuvent automatiser la surveillance des opérations de la base de données Qdrant, réduire la complexité de la journalisation manuelle, et améliorer considérablement leur capacité à se conformer aux normes réglementaires.
Conclusion
Alors que Qdrant est une base de données vecteur puissante, ses capacités natives de journalisation de vérification sont minimales et insuffisantes pour la conformité et la sécurité. En implémentant des wrappers personnalisés ou en utilisant des outils tiers, les organisations peuvent atteindre un niveau de base d’auditabilité. Cependant, pour des traces de vérification complètes, évolutives et faciles à gérer, intégrer une solution comme DataSunrise est la meilleure approche.
DataSunrise offre une solution avancée et prête à l’emploi pour suivre et surveiller toutes les interactions avec les données Qdrant, en faisant un outil inestimable pour les organisations visant à protéger les données sensibles et à assurer la conformité avec les normes réglementaires. Découvrez les avantages par vous-même—planifiez une démonstration en ligne dès aujourd’hui et redéfinissez votre processus de collecte de traces de vérification des données Qdrant avec DataSunrise.
