
Guide Complet du Masquage de Données pour la Sécurité et la Confidentialité des Dataframes

Introduction
Vous avez peut-être lu nos articles sur le masquage de données d’un point de vue stockage de données, où nous avons discuté des techniques de masquage statique, dynamique et en place. Cependant, la procédure de masquage dans la science des données diffère légèrement. Bien que nous devions toujours garantir la confidentialité et la protection des données des dataframes, nous visons également à en tirer des insights basés sur les données. Le défi réside dans le maintien de l’informativité des données tout en assurant leur confidentialité.
Alors que les organisations dépendent fortement de la science des données pour les insights et la prise de décision, le besoin de techniques robustes de protection des données n’a jamais été aussi grand. Cet article aborde le sujet crucial du masquage des données dans les dataframes en explorant comment cette procédure protège les données sensibles tout en maintenant leur utilité pour l’analyse.
Comprendre le Masquage de Données en Science des Données
Le masquage de données est un processus critique dans le domaine de la protection des données. Bien que nous n’entrions pas trop dans ses aspects généraux, il est essentiel de comprendre son rôle en science des données.
Dans le contexte de la science des données, les techniques de masquage jouent un rôle vital en préservant les caractéristiques statistiques des ensembles de données tout en cachant les informations sensibles. Cet équilibre est crucial pour maintenir l’utilité des données tout en garantissant leur confidentialité et en respectant les exigences réglementaires.
Masquage avec Préservation du Format : Équilibrer l’Utilité et la Confidentialité
Les techniques de masquage avec préservation du format sont particulièrement précieuses dans les applications de science des données. Ces méthodes aident à maintenir les paramètres statistiques de l’ensemble de données tout en protégeant efficacement les informations sensibles. En préservant le format et la distribution des données originales, les chercheurs et les analystes peuvent travailler avec des ensembles de données masqués qui ressemblent étroitement aux données authentiques, garantissant la validité de leurs résultats sans compromettre la confidentialité.
Qu’est-ce qu’un Dataframe ?
Avant d’entrer dans les procédures de masquage, clarifions ce qu’est un dataframe. En science des données, un dataframe est une structure de données étiquetée bidimensionnelle avec des colonnes de types potentiellement différents. Il est similaire à une feuille de calcul ou une table SQL et est un outil fondamental pour la manipulation et l’analyse des données dans de nombreux langages de programmation, en particulier en Python avec des bibliothèques comme Pandas.
Masquage de Données dans les Dataframes
En ce qui concerne la protection des informations sensibles dans les dataframes, il existe deux approches principales :
- Masquage lors de la formation du dataframe
- Application de techniques de masquage après la création du dataframe
Explorons ces méthodes en détail.
Masquage Lors de la Formation du Dataframe
Cette approche consiste à appliquer des techniques de masquage lors du chargement des données dans le dataframe. Elle est particulièrement utile lorsque l’on travaille avec de grands ensembles de données ou lorsque l’on souhaite s’assurer que les données sensibles n’entrent jamais dans l’environnement de travail sous leur forme brute.
Exemple : Masquage Lors de l’Importation d’un Fichier CSV
Voici un exemple simple utilisant Python et pandas pour masquer les données sensibles lors de l’importation d’un fichier CSV :
import pandas as pd
import hashlib
def mask_sensitive_data(value):
return hashlib.md5(str(value).encode()).hexdigest()
# Lire le fichier CSV avec la fonction de masquage appliquée à la colonne 'ssn'
df = pd.read_csv('employee_data.csv', converters={'ssn': mask_sensitive_data})
print(df.head())Dans cet exemple, nous utilisons une fonction de hachage pour masquer la colonne ‘ssn’ (Numéro de Sécurité Sociale) lors de la lecture des données dans le dataframe. Le résultat est un dataframe où la colonne ‘ssn’ contient des valeurs hachées au lieu des données sensibles originales.
Le résultat du code doit être comme suit :
index nom âge ssn salaire département 0 Tim Hernandez 37 6d528… 144118.53 Marketing 1 Jeff Jones 29 5787e… 73994.32 IT 2 Nathan Watts 64 86975… 45936.64 Ventes …
Application des Techniques de Masquage Après la Création du Dataframe
Cette méthode consiste à rechercher et masquer les données sensibles dans un dataframe existant. Elle est utile lorsque l’on doit d’abord travailler avec les données originales mais que l’on souhaite les protéger avant de partager ou de stocker les résultats.
Exemple : Masquage des Colonnes Existant d’un Dataframe
Voici un exemple de la façon de masquer des colonnes spécifiques dans un dataframe existant :
import pandas as pd
import numpy as np
# Créer un dataframe d'exemple
df = pd.DataFrame({
'nom': ['Alice', 'Bob', 'Charlie'],
'âge': [25, 30, 35],
'ssn': ['123-45-6789', '987-65-4321', '456-78-9012']
})
# Fonction pour masquer le SSN
def mask_ssn(ssn):
return 'XXX-XX-' + ssn[-4:]
# Appliquer le masquage à la colonne 'ssn'
df['ssn'] = df['ssn'].apply(mask_ssn)
print(df)Ce script crée un dataframe d’exemple puis applique une fonction de masquage personnalisée à la colonne ‘ssn’. Le résultat est un dataframe où seuls les quatre derniers chiffres du SSN sont visibles, tandis que le reste est masqué par des caractères ‘X’.
Le résultat doit être comme suit :
nom âge ssn 0 Alice 25 XXX-XX-6789 1 Bob 30 XXX-XX-4321 2 Charlie 35 XXX-XX-9012
Techniques de Masquage Avancées pour les Dataframes
Alors que nous approfondissons la protection des données des dataframes, il est important d’explorer des techniques de masquage plus sophistiquées applicables à divers types de données et scénarios.
Masquage de Données Numériques
Lorsqu’il s’agit de données numériques, il peut être crucial de préserver les propriétés statistiques tout en les masquant. Voici un exemple de la façon d’ajouter du bruit aux données numériques tout en maintenant leur moyenne et leur écart type :
import pandas as pd
import numpy as np
# Créer un dataframe d'exemple avec des données numériques
df = pd.DataFrame({
'id': range(1, 1001),
'salaire': np.random.normal(50000, 10000, 1000)
})
# Fonction pour ajouter du bruit tout en préservant la moyenne et l'écart type
def add_noise(column, noise_level=0.1):
noise = np.random.normal(0, column.std() * noise_level, len(column))
return column + noise
# Appliquer du bruit à la colonne salaire
df['salaire_masqué'] = add_noise(df['salaire'])
print("Statistiques des salaires originaux:")
print(df['salaire'].describe())
print("\nStatistiques des salaires masqués:")
print(df['salaire_masqué'].describe())Ce script crée un dataframe d’exemple avec des données de salaire, puis applique une fonction d’ajout de bruit pour masquer les salaires. Les données masquées résultantes maintiennent des propriétés statistiques similaires à celles des données originales, les rendant utiles pour l’analyse tout en protégeant les valeurs individuelles.
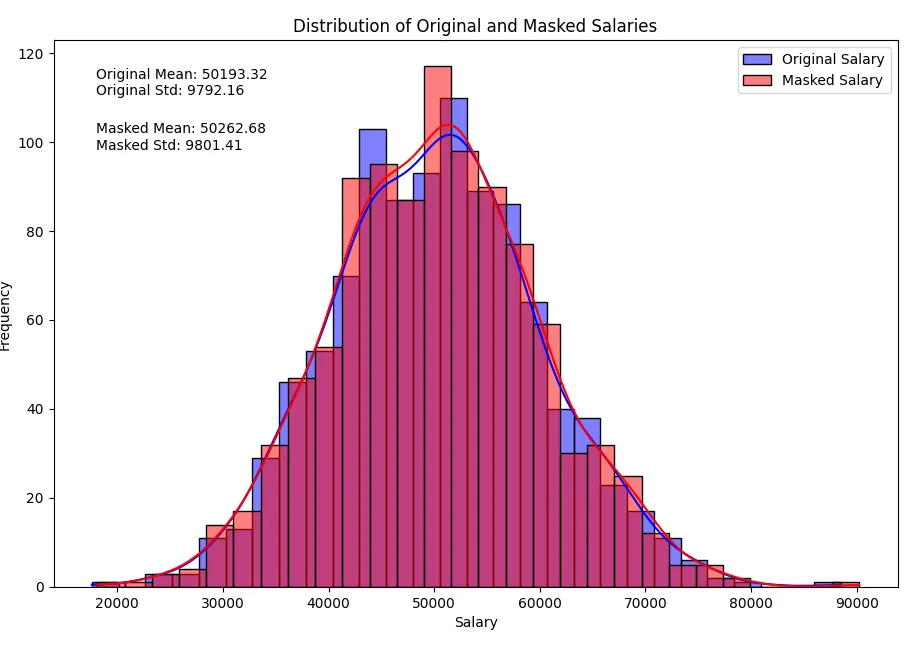
Notez qu’il n’y a pas de changements importants dans les paramètres statistiques, tandis que les données sensibles sont préservées en ajoutant du bruit aux données.
Statistiques des salaires originaux : count 1000.000000 mean 49844.607421 std 9941.941468 min 18715.835478 25% 43327.385866 50% 49846.432943 75% 56462.098573 max 85107.367406 Name: salaire, dtype: float64 Statistiques des salaires masqués : count 1000.000000 mean 49831.697951 std 10035.846618 min 17616.814547 25% 43129.152589 50% 49558.566315 75% 56587.690976 max 83885.686201 Name: salaire_masqué, dtype: float64
Les distributions normales ressemblent maintenant à ceci :
Masquage de Données Catégoriques
Pour les données catégoriques, nous pourrions vouloir préserver la distribution des catégories tout en masquant les valeurs individuelles. Voici une méthode à l’aide du mappage de valeurs :
import pandas as pd
import numpy as np
# Créer un dataframe d'exemple avec des données catégoriques
df = pd.DataFrame({
'id': range(1, 1001),
'département': np.random.choice(['RH', 'IT', 'Ventes', 'Marketing'], 1000)
})
# Créer un dictionnaire de mappage
dept_mapping = {
'RH': 'Dept A',
'IT': 'Dept B',
'Ventes': 'Dept C',
'Marketing': 'Dept D'
}
# Appliquer le mappage pour masquer les noms des départements
df['département_masqué'] = df['département'].map(dept_mapping)
print(df.head())
print("\nDistribution originale des départements :")
print(df['département'].value_counts(normalize=True))
print("\nDistribution des départements masqués :")
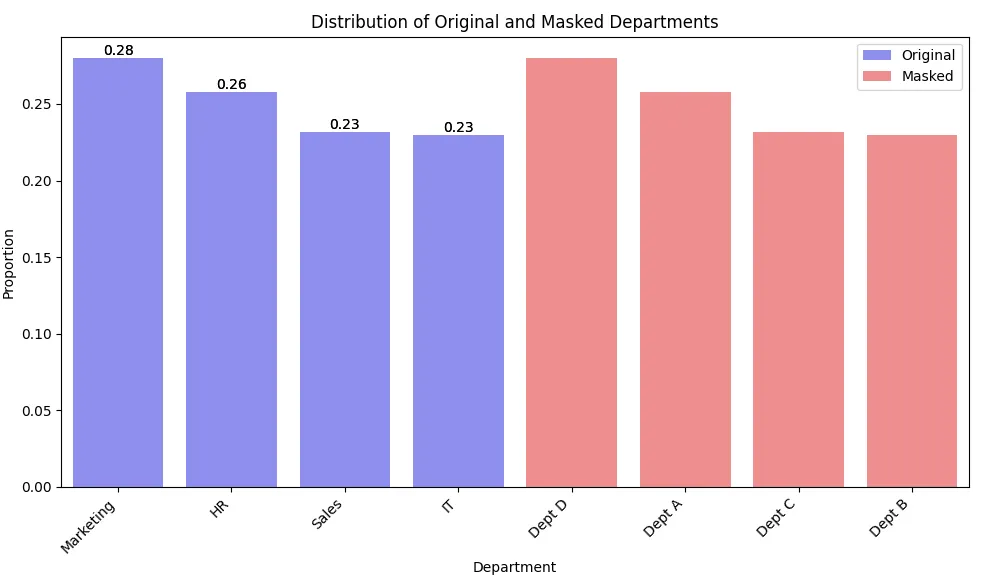
print(df['département_masqué'].value_counts(normalize=True))Cet exemple démontre comment masquer les données catégoriques (noms de départements) tout en maintenant la distribution originale des catégories.
Si vous parcourez les données, elles peuvent apparaître comme suit. Notez que les longueurs des barres sont les mêmes pour les données masquées et non masquées, tandis que les étiquettes sont différentes.
Les Enjeux de la Protection des Données des Dataframes
Bien que les procédures de masquage offrent des outils puissants pour protéger les données sensibles dans les dataframes, elles comportent leur lot de défis :
- Maintien de l’Utilité des Données : Trouver le bon équilibre entre la protection des données et leur utilité pour l’analyse peut être difficile.
- Consistance Entre les Ensembles de Données : Garantir que les valeurs masquées soient cohérentes entre plusieurs dataframes ou tables de la base de données étroitement liées est crucial pour maintenir l’intégrité des données.
- Impact sur la Performance : Certaines techniques de masquage peuvent être gourmandes en ressources, notamment pour les grands ensembles de données.
- Réversibilité : Dans certains cas, il peut être nécessaire de démasquer les données, ce qui nécessite une gestion soigneuse des clés ou des algorithmes de masquage.
Bonnes Pratiques de Masquage de Données en Science des Données
Pour relever ces défis et garantir un masquage efficace des données dans les dataframes, prenez en compte les bonnes pratiques suivantes :
- Comprendre ses Données : Avant d’appliquer une technique de masquage, analysez minutieusement vos données pour comprendre leur structure, leurs relations et leur niveau de sensibilité.
- Choisir les Techniques Appropriées : Sélectionnez les méthodes de masquage adaptées à vos types de données spécifiques et à vos besoins d’analyse.
- Préserver l’Intégrité Référentielle : Lorsque vous masquez les ensembles de données liés, assurez-vous que les valeurs masquées maintiennent les relations nécessaires entre les tables ou les dataframes.
- Audit Régulier : Révisez et mettez périodiquement à jour vos procédures de masquage pour garantir qu’elles respectent les normes et règlements de protection des données en constante évolution.
- Documenter Votre Processus : Maintenez une documentation claire de vos procédures de masquage à des fins de conformité et de résolution de problèmes.
Conclusion
Le masquage doit préserver la propriété des données de produire des insights basés sur les données. Le masquage des données dans les dataframes est un aspect critique de la science des données moderne, équilibrant le besoin d’analyses perspicaces avec l’impératif de protection des données. En comprenant les différentes techniques de masquage et en les appliquant judicieusement, les data scientists peuvent travailler avec des informations sensibles tout en maintenant la confidentialité et la conformité.
Comme nous l’avons exploré, il existe deux approches pour masquer les données dans les dataframes, chacune avec ses forces et ses considérations. Que vous masquiez les données lors de l’importation ou que vous appliquiez des techniques aux dataframes existants, l’important est de choisir des méthodes qui préservent l’utilité de vos données tout en protégeant efficacement les informations sensibles.
Rappelez-vous, la protection des données est un processus continu. Au fur et à mesure que les techniques de science des données évoluent et que de nouveaux défis en matière de confidentialité émergent, rester informé et adaptable dans votre approche de la protection des données des dataframes sera crucial.
