
Qu’est-ce qu’un fichier CSV ?
Introduction : Le Modeste Fichier CSV
Saviez-vous que les fichiers CSV existent depuis les débuts de l’informatique ? Dans les années 1970 et début 1980, le langage Fortran 77 d’IBM a introduit le type de données caractères, ce qui a permis de prendre en charge les entrées et sorties séparées par des virgules. Ces fichiers simples mais puissants ont résisté à l’épreuve du temps, restant un choix populaire pour l’échange de données même dans notre monde moderne axé sur la technologie. Plongeons dans le monde des fichiers séparés par des virgules et explorons pourquoi ils continuent d’être un format incontournable pour de nombreux professionnels et utilisateurs occasionnels.
Nous avons précédemment décrit les capacités de DataSunrise pour gérer les données semi-structurées au format JSON. Consultez ces informations pour en savoir plus sur les fonctionnalités de sécurité des données de DataSunrise.
Avec DataSunrise, vous pouvez masquer et découvrir les données sensibles dans les fichiers CSV stockés localement ou dans le stockage S3. Voici un exemple de masquage.
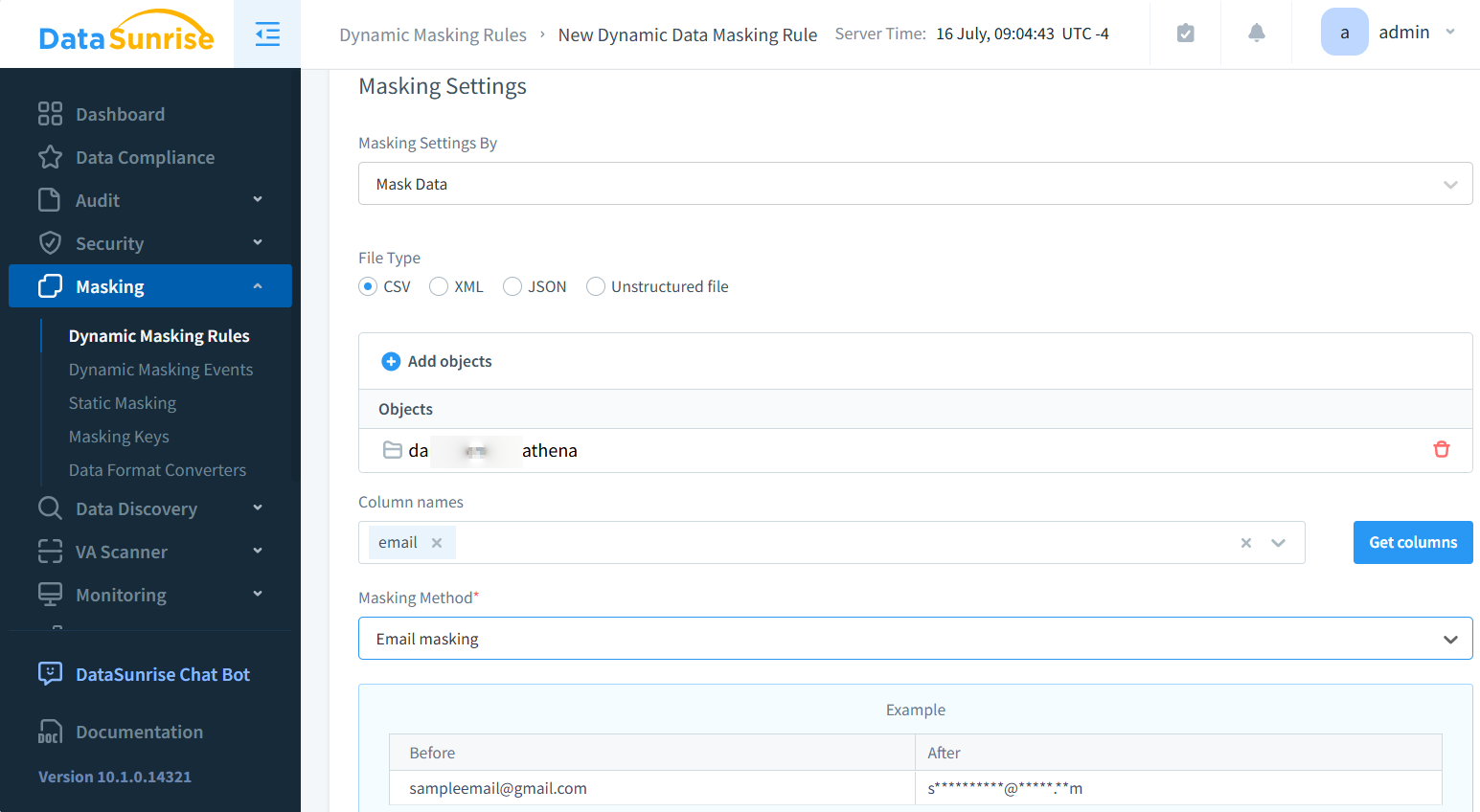
Après une installation simple, vous pouvez accéder (télécharger) aux fichiers CSV masqués via le proxy S3 de DataSunrise grâce à des logiciels spécialisés comme S3Browser. Une configuration appropriée des paramètres du proxy est requise dans le logiciel client. Le résultat est le suivant :

Dans le vaste paysage des formats de fichiers, le CSV se distingue par sa simplicité et sa polyvalence. CSV, qui signifie valeurs séparées par des virgules, est un type de fichier texte brut qui stocke des données tabulaires. Chaque ligne du fichier représente une ligne de données, avec des virgules séparant les valeurs individuelles. Cette structure simple permet de créer, lire et manipuler facilement ces fichiers sur diverses plateformes et applications.
Pourquoi utiliser les fichiers CSV ?
Les fichiers CSV offrent plusieurs avantages qui contribuent à leur utilisation généralisée :
- Simplicité : Le format est facile à comprendre et à utiliser, même pour les utilisateurs non techniques. Vous pouvez l’ouvrir dans Notepad ou Notepad++ (n’importe quel éditeur de texte).
- Compatibilité : Les fichiers peuvent être ouverts et modifiés par une large gamme de logiciels, allant des applications de tableur aux éditeurs de texte.
- Échange de données : Ils servent de format universel pour le transfert de données entre différents systèmes et applications.
- Efficacité de taille : Les fichiers sont généralement plus petits que leurs homologues binaires, ce qui les rend idéaux pour le stockage et la transmission de grands ensembles de données.
Voici un tableau comparatif des formats de données utilisés dans le Big Data et l’apprentissage machine, mettant en évidence le rôle des fichiers séparés par des virgules dans le traitement des données.
| Format | Big Data | Apprentissage machine | Avantages | Inconvénients |
|---|---|---|---|---|
| CSV | Commun pour l’échange de données, moins commun pour le stockage | Souvent utilisé pour les jeux de données petits à moyens | Simple, lisible par l’homme, largement pris en charge | Non efficace pour les grands ensembles de données, pas d’application de schéma |
| Parquet | Très commun pour le stockage et le traitement | Bon pour les grands ensembles de données et les magasins de fonctionnalités | Stockage en colonnes, compression efficace | Non lisible par l’homme, nécessite des outils spéciaux pour visualiser |
| Avro | Commun pour la sérialisation des données | Moins commun, mais utilisé dans certaines pipelines | Évolution du schéma, format binaire compact | Plus complexe que le CSV, pas aussi efficace que Parquet pour l’analyse |
| JSON | Commun pour les API et les magasins de documents | Utilisé pour stocker des métadonnées et de petits ensembles de données | Flexible, lisible par l’homme, largement pris en charge | Stockage moins efficace que les formats binaires |
| TFRecord | Pas couramment utilisé | Spécifique à TensorFlow, commun dans les pipelines ML | Efficace pour les grands ensembles de données, bon avec TensorFlow | Pas largement pris en charge en dehors de l’écosystème TensorFlow |
Exemple de CSV
Regardons un exemple simple de CSV pour illustrer sa structure :
Nom, Âge, Ville John Doe, 30, New York Jane Smith, 25, Londres Bob Johnson, 35, Paris
Cet exemple montre comment les données sont organisées dans un fichier CSV, chaque ligne représentant un enregistrement et les virgules séparant les valeurs.
Travailler avec des fichiers CSV en Python
Python fournit des outils intégrés pour gérer les fichiers CSV, en faisant un choix populaire pour les tâches de traitement des données. Explorons comment travailler avec des fichiers CSV à l’aide de Python de base et de la puissante bibliothèque pandas.
Utilisation de Python de base
Le module csv de Python offre des méthodes simples pour lire et écrire des fichiers CSV. Voici un exemple de base :
import csv
# Lecture d'un fichier
with open('data.csv', 'r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
# Écriture dans un fichier
with open('output.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['Nom', 'Âge', 'Ville'])
csv_writer.writerow(['Alice', '28', 'Berlin'])Ce code montre comment lire et écrire des fichiers CSV en utilisant le module csv intégré de Python.
Utilisation de Pandas
Pour une manipulation de données plus avancée, la bibliothèque pandas est un excellent choix. Elle offre des outils puissants pour travailler avec des données semi-structurées, y compris les fichiers CSV :
import pandas as pd
# Lecture d'un fichier
df = pd.read_csv('data.csv')
# Affichage des premières lignes
print(df.head())
# Écriture dans un fichier
df.to_csv('output.csv', index=False)Pandas facilite l’exécution d’opérations complexes sur les données CSV, telles que le filtrage, le tri et l’agrégation. Vous pouvez facilement sauvegarder les données à nouveau au format CSV par la suite.
Les Avantages et Inconvénients des Fichiers Séparés par des Virgules
Bien que les fichiers CSV soient largement utilisés, il est important de comprendre leurs forces et leurs limitations :
Avantages
- Lisibilité humaine : Les fichiers séparés par des virgules peuvent être facilement visualisés et modifiés dans des éditeurs de texte.
- Légèreté : Ils ont une taille de fichier réduite par rapport à de nombreux autres formats.
- Largement pris en charge : La plupart des outils de traitement de données et des langages de programmation peuvent travailler avec des fichiers CSV.
Inconvénients
- Types de données limités : Les fichiers texte ne prennent pas en charge nativement les types de données ou structures complexes.
- Pas de standardisation : Il n’existe pas de norme officielle pour les fichiers CSV, ce qui peut entraîner des problèmes de compatibilité. Il n’y a pas de colonnes requises ou de délimiteurs obligatoires.
- Intégrité des données : Les fichiers séparés par des virgules n’ont pas de mécanismes de vérification des erreurs ou de validation des données intégrés. Les formats Big Data (comme Parquet) incluent des sommes de contrôle intégrées pour les blocs de données.
Formats Binaires : Quand et Pourquoi ils sont Meilleurs
Alors que les fichiers CSV excellent dans de nombreux scénarios, les formats binaires peuvent être avantageux dans certaines situations :
- Performance : Les formats binaires sont souvent plus rapides à lire et à écrire, surtout pour de grands ensembles de données.
- Types de données : Ils peuvent mieux préserver les types et structures de données complexes.
- Compression : Les formats binaires offrent généralement de meilleurs taux de compression, économisant de l’espace de stockage.
- Sécurité : Certains formats binaires offrent des options de cryptage et de contrôle d’accès.
Des exemples de formats binaires incluent HDF5, Parquet et Avro. Ces formats sont particulièrement utiles dans les environnements de Big Data où les performances et l’intégrité des données sont cruciales.
Fichiers CSV et Échange de Données
Les fichiers CSV jouent un rôle essentiel dans l’échange de données dans divers secteurs et applications :
- Intelligence économique : Les entreprises utilisent fréquemment des fichiers texte pour transférer des données entre différents outils et bases de données de BI.
- Recherche scientifique : Les chercheurs partagent souvent des ensembles de données dans ce format pour une analyse et une collaboration faciles.
- Applications Web : De nombreux services Web permettent aux utilisateurs d’exporter des données au format texte pour une analyse hors ligne ou à des fins de sauvegarde.
- IoT et données de capteurs : Les fichiers texte séparés par des virgules sont couramment utilisés pour enregistrer et transmettre des données provenant de dispositifs et capteurs IoT.
La simplicité et la nature universelle des fichiers texte en font un choix idéal pour ces scénarios d’échange de données.
Champ du Big Data
Les fichiers de valeurs séparées par des virgules ont une relation quelque peu complexe avec le Big Data. Laissez-moi vous décomposer cela :
- Popularité dans certains contextes :
- Le format de fichier séparé par des virgules est encore largement utilisé pour l’échange de données et comme format intermédiaire dans les écosystèmes de Big Data.
- Il est souvent utilisé pour importer des données dans des systèmes de Big Data ou pour exporter des résultats pour une analyse plus poussée.
- Limitations pour le Big Data :
- Les fichiers CSV ne se compressent pas bien, ce qui peut poser problème lorsqu’il s’agit de très grands ensembles de données.
- Ils n’ont pas de définitions de schéma intégrées, ce qui peut entraîner des incohérences de données dans les opérations à grande échelle.
- L’analyse des grands fichiers texte peut être plus lente par rapport à certains formats binaires.
- Alternatives préférées :
- Pour les opérations de Big Data, les formats tels que Parquet, Avro, ou ORC sont souvent préférés.
- Ces formats offrent une meilleure compression, une évolution du schéma et des vitesses de traitement plus rapides.
- Cas d’utilisation où les fichiers CSV sont encore pertinents :
- Ingestion de données : De nombreux systèmes acceptent encore les valeurs séparées par des virgules comme format d’entrée.
- Systèmes hérités : Certains anciens systèmes peuvent encore compter sur ces fichiers pour échanger des données.
- Jeux de données simples : Pour les jeux de données plus petits ou moins complexes au sein d’un écosystème Big Data, CSV peut encore être utilisé.
- Approches hybrides :
- Certaines charges de travail de Big Data peuvent utiliser CSV pour l’ingestion initiale de données ou la sortie finale, tout en utilisant des formats plus optimisés pour les étapes de traitement intermédiaires.
Conclusion : La Valeur Durable des Fichiers CSV
Les fichiers CSV continuent d’être un outil précieux dans la boîte à outils des professionnels des données. Leur simplicité, leur polyvalence et leur large prise en charge en font un choix excellent pour de nombreux scénarios d’échange et de stockage de données. Bien que les formats binaires offrent des avantages dans certaines situations, le modeste fichier texte reste une solution incontournable pour le partage rapide et facile de données sur les plateformes et applications.
Comme nous l’avons exploré, travailler avec des fichiers séparés par des virgules en Python est simple, que vous utilisiez Python de base ou des bibliothèques plus avancées comme pandas. Cet accès joue un rôle clé dans la popularité continue des fichiers CSV dans les tâches d’analyse et de traitement des données.
Pour ceux qui traitent des données sensibles dans les fichiers CSV ou d’autres formats semi-structurés, DataSunrise offre des outils conviviaux et flexibles pour la sécurité des bases de données. Nos solutions incluent la découverte des données basée sur le NLP, qui peut être particulièrement utile lors du travail avec des fichiers séparés par des virgules contenant potentiellement des informations sensibles. Pour en savoir plus sur la manière dont DataSunrise peut améliorer vos mesures de sécurité des données, visitez notre site Web pour une démonstration en ligne et explorez nos solutions complètes de sécurité des bases de données.
