
Simplifier le Flux de Données
Pour les entreprises guidées par les données, un traitement efficace des données est crucial pour obtenir des informations et prendre des décisions éclairées. Cependant, lorsqu’on trouve des informations sensibles, il est essentiel de trouver un équilibre entre rapidité et efficacité et protection des données et sécurité. Cet article présente des moyens de simplifier les flux de données en utilisant des méthodes ETL et ELT tout en protégeant la vie privée des données.
Comprendre les Approches de Simplification du Traitement des Données
Avant de plonger dans ETL et ELT, examinons les approches courantes de simplification du traitement des données :
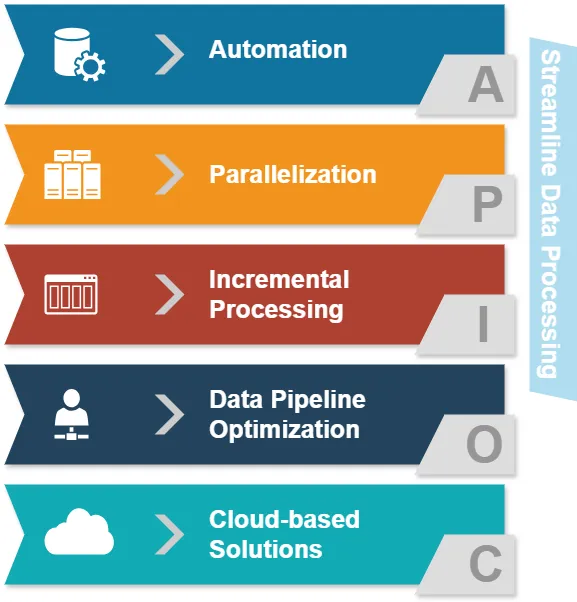
- Automatisation : Réduire les interventions manuelles dans les tâches de traitement des données.
- Parallélisation : Traiter plusieurs flux de données simultanément.
- Traitement incrémental : Mettre à jour uniquement les données modifiées plutôt que l’ensemble des jeux de données.
- Optimisation du pipeline de données : Assurer un flux de données fluide entre les différentes étapes.
- Solutions basées sur le cloud : Profiter d’infrastructures évolutives pour le traitement des données.
Ces approches visent à améliorer l’efficacité du traitement des données. Maintenant, explorons comment ETL et ELT s’intègrent dans ce paysage.
ETL vs. ELT : Comparaison en Bref
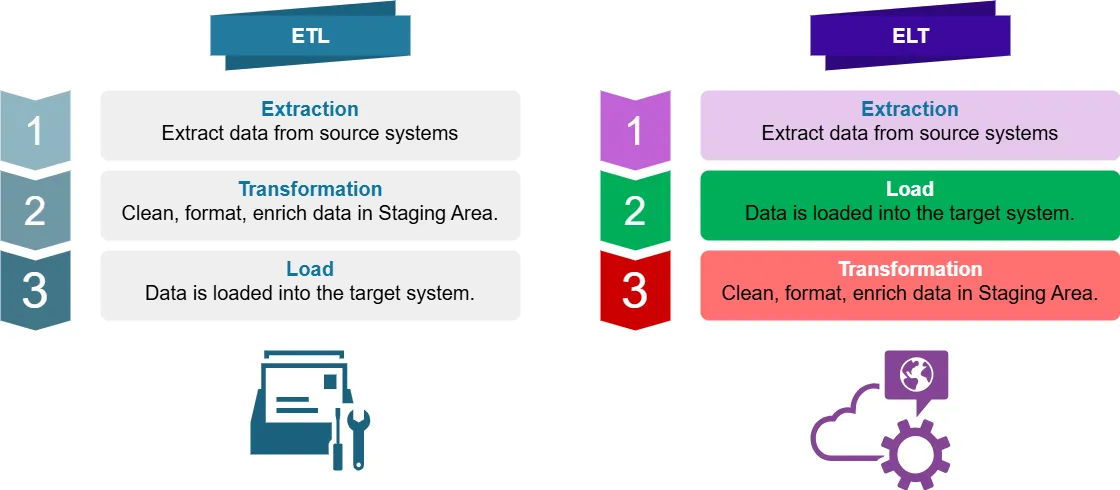
Qu’est-ce que l’ETL ?
ETL signifie Extract, Transform, Load (Extrait, Transforme, Charge). C’est un processus traditionnel d’intégration de données où les données sont :
- Extraites des systèmes sources de données
- Transformées (nettoyées, formatées, enrichies) dans une zone de staging
- Chargées dans le système cible (par exemple, un entrepôt de données)
Qu’est-ce que l’ELT ?
ELT signifie Extract, Load, Transform (Extrait, Charge, Transforme). C’est une approche moderne où les données sont :
- Extraites des systèmes sources
- Chargées directement dans le système cible
- Transformées au sein du système cible
Différences Clés dans le Traitement Optimisé des Données
Pour l’intelligence d’affaires, la principale différence entre ETL et ELT réside dans l’endroit et le moment où la transformation des données a lieu. Cela impacte le traitement optimal des données de plusieurs manières :
- Puissance de traitement : ETL repose sur des serveurs de transformation distincts, tandis que ELT utilise la puissance du système cible.
- Flexibilité des données : ELT préserve les données brutes, permettant des transformations plus agiles.
- Temps de traitement : ELT peut être plus rapide pour les grands ensembles de données grâce aux capacités de traitement parallèle.
- Confidentialité des données : ETL peut offrir un meilleur contrôle sur les données sensibles pendant la transformation.
Où sont Appliqués l’ETL et l’ELT ?
L’ETL est couramment utilisé dans :
- Les entrepôts de données traditionnels
- Des systèmes avec un stockage ou une puissance de traitement limités
- Des scénarios nécessitant des transformations complexes des données avant chargement
L’ELT est souvent préféré pour :
- Les entrepôts de données basés sur le cloud
- Les environnements de big data
- Le traitement des données en temps réel ou quasi-réel
- Les situations où la préservation des données brutes est essentielle
Simplification des Flux de Données : Exemples en Python et Pandas
Examinons quelques exemples de traitement des données simplifié et non simplifié en utilisant Python et Pandas.
Approche Non Simplifiée
import pandas as pd
# Lire les données à partir d'un fichier CSV
df = pd.read_csv('large_dataset.csv')
# Effectuer plusieurs transformations
df['new_column'] = df['column_a'] + df['column_b']
df = df[df['category'] == 'important']
df['date'] = pd.to_datetime(df['date'])
# Écrire les données transformées dans un nouveau fichier CSV
df.to_csv('transformed_data.csv', index=False)Cette approche lit l’ensemble du jeu de données en mémoire, effectue des transformations, puis écrit le résultat. Pour les grands ensembles de données, cela peut être intensif en mémoire et lent.
Approche Simplifiée
import pandas as pd
# Utiliser des morceaux pour traiter de grands ensembles de données
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
# Effectuer des transformations sur chaque morceau
chunk['new_column'] = chunk['column_a'] + chunk['column_b']
chunk = chunk[chunk['category'] == 'important']
chunk['date'] = pd.to_datetime(chunk['date'])
# Ajouter le morceau transformé au fichier de sortie
chunk.to_csv('transformed_data.csv', mode='a', header=False, index=False)Cette approche simplifiée traite les données par morceaux, réduisant l’utilisation de la mémoire et permettant un traitement parallèle. Elle est plus efficace pour les grands ensembles de données et peut être facilement intégrée dans des flux de travail ETL ou ELT.
Confidentialité des Données avec ETL et ELT
Lorsqu’il s’agit de données sensibles, la confidentialité est primordiale. Les deux méthodes ETL et ELT peuvent être conçues pour traiter les informations sensibles en toute sécurité :
ETL et Confidentialité des Données
- Masquage des données : Appliquer des techniques de masquage lors de la phase de transformation.
- Chiffrement : Chiffrer les données sensibles avant de les charger dans le système cible.
- Contrôle d’accès : Mettre en place des contrôles d’accès stricts sur le serveur de transformation.
Exemple de masquage des données dans ETL :
import pandas as pd
def mask_sensitive_data(df):
df['email'] = df['email'].apply(lambda x: x.split('@')[0][:3] + '***@' + x.split('@')[1])
df['phone'] = df['phone'].apply(lambda x: '***-***-' + x[-4:])
return df
# Processus ETL
df = pd.read_csv('source_data.csv')
df = mask_sensitive_data(df)
# Transformations supplémentaires...
df.to_csv('masked_data.csv', index=False)ELT et Confidentialité des Données
- Chiffrement au niveau des colonnes : Chiffrer les colonnes sensibles avant de les charger.
- Masquage dynamique des données : Appliquer des règles de masquage dans le système cible.
- Contrôle d’accès basé sur les rôles : Mettre en œuvre des politiques d’accès granulaires dans l’entrepôt de données.
Exemple de chiffrement au niveau des colonnes dans ELT :
import pandas as pd
from cryptography.fernet import Fernet
def encrypt_column(df, column_name, key):
f = Fernet(key)
df[column_name] = df[column_name].apply(lambda x: f.encrypt(x.encode()).decode())
return df
# Générer une clé de chiffrement (en pratique, stocker et gérer cette clé en toute sécurité)
key = Fernet.generate_key()
# Processus ELT
df = pd.read_csv('source_data.csv')
df = encrypt_column(df, 'sensitive_column', key)
# Charger les données dans le système cible
df.to_sql('target_table', engine) # En supposant que 'engine' est votre connexion à la base de données
# Transformer les données au sein du système cibleOptimisation des Flux de Données pour les Données Sensibles
Pour simplifier les flux de données tout en préservant la confidentialité des données, considérez ces meilleures pratiques :
- Classification des données : Identifier et catégoriser les données sensibles tôt dans le processus.
- Minimiser les mouvements de données : Réduire le nombre de fois où les données sensibles sont transférées entre les systèmes.
- Utiliser des protocoles sécurisés : Utiliser le chiffrement pour les données en transit et au repos.
- Mettre en œuvre la gouvernance des données : Établir des politiques claires pour la gestion et l’accès aux données.
- Audits réguliers : Réaliser des examens périodiques de vos flux de travail de traitement des données.
Conclusion
Il est important de simplifier les flux de données. Nous devons également nous assurer que les informations sensibles sont protégées par des mesures de confidentialité robustes. Les approches ETL et ELT présentent des avantages uniques et les organisations peuvent les optimiser pour la performance et la sécurité.
Cet article parle des moyens par lesquels les organisations peuvent créer des flux de données sécurisés. Ces flux protègent les informations sensibles tout en permettant de générer des informations précieuses. Les organisations peuvent utiliser des stratégies et des meilleures pratiques pour atteindre cet objectif.
Rappelez-vous, le choix entre ETL et ELT dépend de votre cas d’utilisation spécifique, du volume de données et des exigences de confidentialité. Il est important de revoir et de mettre à jour régulièrement vos stratégies de traitement des données. Cela garantira qu’elles s’alignent sur les besoins évolutifs de votre entreprise et respectent les lois sur la protection des données.
Pour des outils faciles à utiliser qui améliorent la sécurité et la conformité des bases de données dans vos processus de données, consultez les options de DataSunrise. Visitez notre site Web à DataSunrise pour voir une démonstration et découvrir comment nous pouvons améliorer votre traitement des données. Nous nous engageons à garder vos données sûres et sécurisées.
