Comment déployer DataSunrise dans Microsoft Azure en utilisant Azure Resource Manager
De nos jours, la technologie de l’informatique en nuage est le moyen le plus efficace et le plus pratique pour exécuter l’environnement de production. De nombreuses entreprises souhaitent stocker leurs données et déployer des applications dans le nuage afin de pouvoir créer, exécuter et gérer leurs services à travers plusieurs nuages en utilisant une grande variété d’outils pour le stockage, l’analyse et la gestion des données. Microsoft Azure fournit aux utilisateurs 4 différentes formes d’informatique en nuage : infrastructure en tant que service (IaaS), plateforme en tant que service (PaaS), logiciel en tant que service (SaaS), et sans serveur, qui sont les solutions clés pour un déploiement de production efficace.
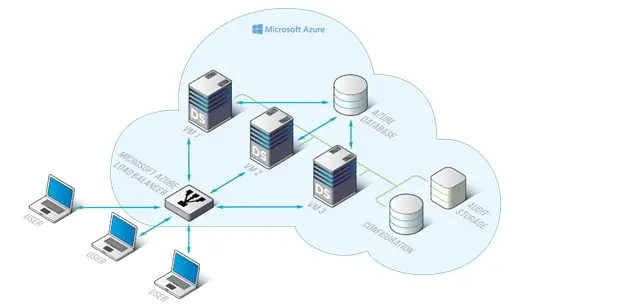
DataSunrise peut être déployé dans différentes configurations comme Instance Autonome, configuration de basculement et configuration de Haute Disponibilité. Ici, nous décrivons une configuration de Haute Disponibilité de DataSunrise.
Le déploiement manuel d’une configuration de Haute Disponibilité (HA) nécessite la mise en œuvre précise de paramètres avec toutes les dépendances correctement appliquées. DataSunrise fournit un script dédié que vous pouvez utiliser pour déployer DataSunrise en configuration de Haute Disponibilité automatiquement au sein du service Microsoft Azure basé sur le modèle Azure Resource Manager (ARM).
L’infrastructure DataSunrise comprend :
- Réseau Virtuel Personnalisé où les sous-réseaux sont stockés.
- Nœuds d’auto-scaling de DataSunrise (instances).
- Stockage de configuration et d’audit basé sur les bases de données Azure.
- Le Load Balancer d’Azure est utilisé pour distribuer le trafic entre les nœuds actifs.
- ScaleSet inclut la configuration du cluster de basculement.
- Key Vault est utilisé pour stocker les informations d’identification pour les ressources ARM.
Tous ces composants sont situés à l’intérieur d’un Réseau Virtuel Personnalisé avec les sous-réseaux spécifiés.
Préparation au déploiement d’un modèle ARM
Les fichiers source du modèle se trouvent dans le répertoire GitHub de DataSunrise. Certaines entités doivent exister dans votre environnement Azure avant que vous ne commenciez le processus de déploiement. Voici la liste des éléments requis :
- Groupe de ressources Azure où toutes les ressources configurées seront déployées.
- Groupe de ressources Azure où est située la base de données que vous protégerez. Ce groupe de ressources doit également inclure un réseau virtuel (VNET) et des sous-réseaux.
- Réseau virtuel Azure qui sera utilisé comme réseau environnemental par les ressources du modèle.
- Sous-réseaux à l’intérieur du VNET que vous désignerez pour votre cluster DataSunrise fonctionnant dans le VNET spécifié.
Les sous-réseaux à utiliser doivent avoir les points de terminaison de service suivants attachés : Point de terminaison du serveur Microsoft.Sql : requis dans le cas où des bases de données MS SQL sont utilisées.
Important :
L’abonnement à votre compte Azure doit être assigné au rôle de Propriétaire pour pouvoir utiliser les ressources Managed Identity afin de se connecter à Azure CLI et de déployer les ressources Azure nécessaires pour une implémentation DataSunrise réussie. Vous pouvez le vérifier dans
Abonnements -> <votre-abonnement> -> Contrôle d’accès -> Assignations de rôles.
Pour déployer DataSunrise en configuration HA, choisissez Déploiement du modèle (déployer en utilisant des modèles personnalisés) à l’intérieur du groupe de ressources sélectionné. Ou vous pouvez utiliser la fonctionnalité Rechercher des services… Ensuite chargez le fichier .json préparé dans l’éditeur et cliquez sur Enregistrer.
Comme mentionné précédemment, le déploiement du modèle ARM se fait avec une intervention minimale de l’utilisateur. Suivez simplement les étapes de l’assistant de déploiement et remplissez les champs requis (notez les messages et que * est pour les informations obligatoires).
Informations de base
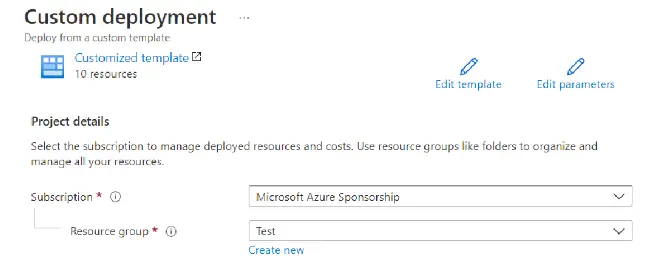
Sélectionnez le type d’abonnement disponible pour votre compte Azure. Le nom du groupe de ressources sera défini automatiquement selon celui choisi dans la section Déploiement du modèle du gestionnaire de ressources.
Configuration de la machine virtuelle
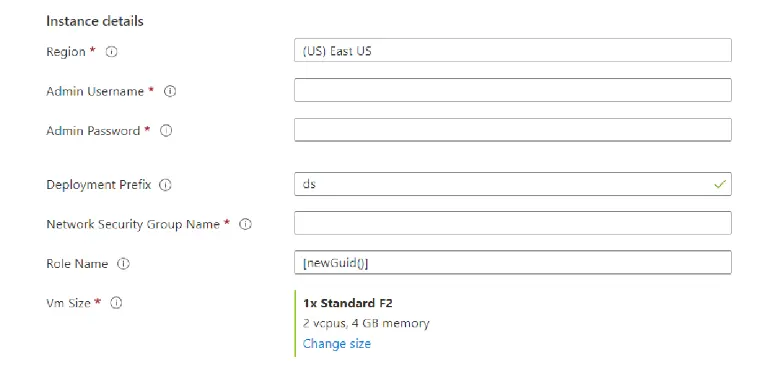
Note : veuillez entrer la valeur de Vm Size la plus pratique en fonction de votre emplacement et de l’ensemble de disponibilité.
Environnement des sous-réseaux

Entrez les informations de l’environnement des sous-réseaux. Notez que dans le Nom du groupe de ressources des sous-réseaux, vous devez spécifier le nom du groupe de ressources où le VNET est stocké.
Configuration de DataSunrise
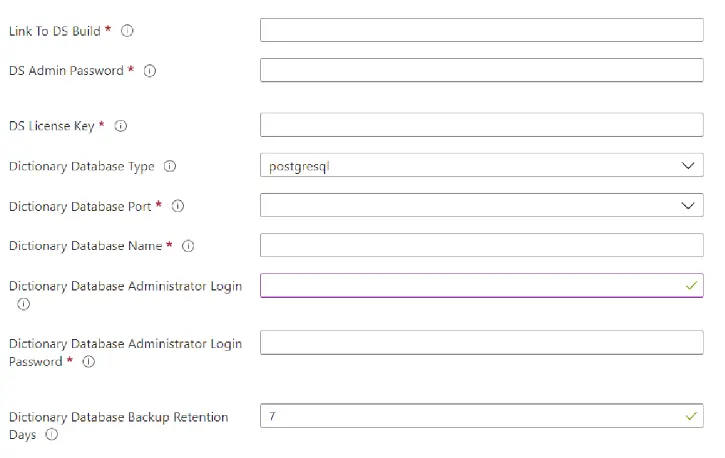
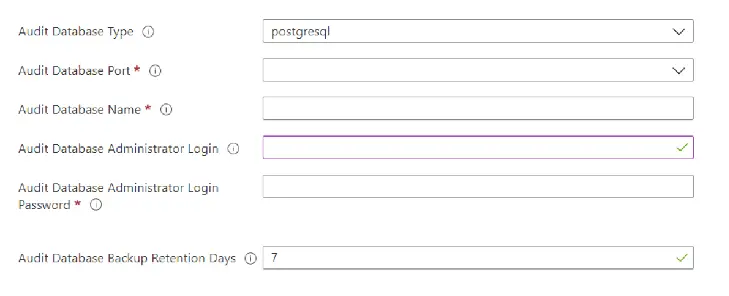
Note : dans ce cas, la base de données Azure PostgreSQL est utilisée comme base de données de stockage de dictionnaire et d’audit.
Configuration de la base de données cible

Finalisation du déploiement
Après que tous les paramètres sont remplis et que la Validation est passée, cliquez sur le bouton Créer.
Le processus de déploiement a commencé. Pour visualiser le déploiement particulier de chaque ressource, cliquez sur le lien dans le coin supérieur droit de l’écran. Vous pouvez également voir le message Déploiement en cours dans le menu déroulant Notification.
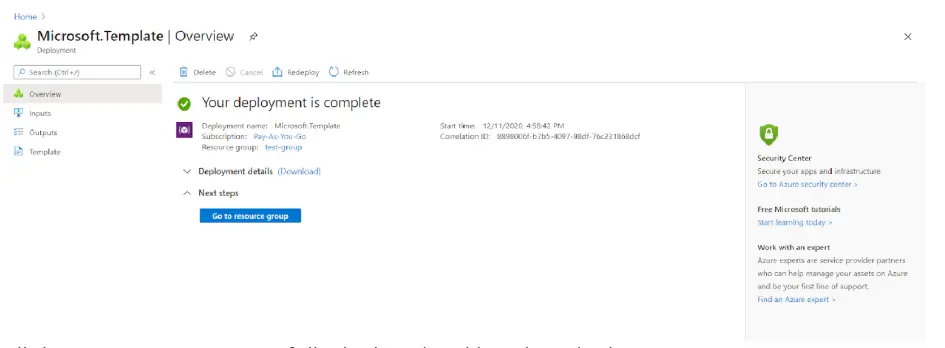
Une fois le déploiement terminé avec succès, un message Votre déploiement est terminé s’affiche. Cliquez sur Accéder au groupe de ressources pour visualiser les ressources créées.
Toutes les ressources sont déployées avec succès et listées dans le groupe de ressources.
Connexion à l’interface utilisateur Web de DataSunrise
Pour vous connecter à la console Web de DataSunrise, utilisez l’adresse IP publique du Load balancer au port 11000. Il se connectera automatiquement à l’un des nœuds configurés. Vous devez également utiliser l’adresse IP pour vous connecter à votre base de données protégée via un proxy et pour vous connecter à votre machine virtuelle en utilisant SSH.
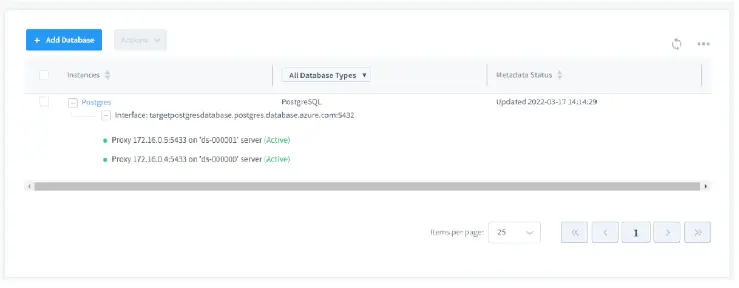
La base de données cible sera automatiquement ajoutée au serveur DataSunrise.
Pour commencer à utiliser DataSunrise comme pare-feu, connectez-vous au port proxy de l’adresse IP publique du Load balancer (spécifié comme paramètre). Par exemple,
psql -h <adresse ip du load balancer> -p 5432 -U <votre utilisateur> -d <votre bd>