Comment délester les données de la base de données d’audit vers AWS S3 et les lire en utilisant le service AWS Athena
Archivage des audits est une fonctionnalité optionnelle de la tâche de nettoyage de la base de données d’audit dans DataSunrise Database Security. Cette fonctionnalité permet à un administrateur d’installation DataSunrise de retirer les données d’audit plus anciennes pour les stocker dans le service AWS S3 afin de fournir une méthode de stockage plus rentable. Avec l’utilisation du service AWS Athena, l’équipe de sécurité et les auditeurs externes peuvent examiner les données historiques nécessaires pour les audits et les enquêtes sur les incidents. En outre, l’utilisation de l’archivage d’audit permet aux clients de DataSunrise de conserver de plus grands ensembles de données d’événements audités sans tout stocker dans la base de données de stockage d’audit unique, et de bénéficier de délais de rapport réduits. De plus, l’utilisation d’AWS S3 pour les données froides est une solution plus économique, ce qui peut aider à optimiser le budget du projet en gardant la taille de la base de données d’audit sous contrôle.
Pour l’archivage des audits, l’équipe DataSunrise fournit un script dédié pour les déploiements Linux qui peut être ajusté pour placer les données supprimées dans un emplacement S3 personnalisable. Il est inclus dans le package d’installation par défaut de DataSunrise, donc vous n’avez pas besoin de le télécharger ailleurs.
Cet article va vous guider tout au long du processus de configuration de la tâche de nettoyage d’audit, du délestage des données supprimées vers l’emplacement de seau S3 de votre choix et de la configuration de l’environnement dans AWS Athena pour les investigations.
Configurer une tâche de nettoyage des données d’audit avec l’option d’archivage des audits
- Ouvrez l’interface utilisateur web de DataSunrise et naviguez vers Configuration → Tâches périodiques. Cliquez sur le bouton Nouvelle tâche et fournissez les informations générales telles que le nom, le type de tâche (par exemple, nettoyer les données d’audit), et sélectionnez le serveur sur lequel exécuter la tâche si vous utilisez un cluster de nœuds DataSunrise.
- Définir les Options d’archive dans la section Nettoyer les données d’audit:
- Cochez l’option Archiver les données supprimées avant de nettoyer.
- Spécifiez le chemin du dossier d’archive où les données d’audit doivent être temporairement stockées avant de les déplacer vers S3.
- Spécifiez le chemin vers le script qui télécharge les données vers AWS S3 en utilisant le champ “Exécuter la commande après archivage”. Chemin par défaut – /opt/datasunrise/scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
(obligatoire) - Fournissez des paramètres supplémentaires pour ajuster le comportement du script (voir ci-dessous pour les arguments de script optionnels)
- Ajustez la Fréquence de la tâche dans la section “Fréquence de lancement”, vous pouvez définir la fréquence d’exécution de la tâche (par exemple, quotidiennement, hebdomadairement, mensuellement) en fonction des besoins de l’organisation en matière de rétention des données d’audit et d’archivage.
- Enregistrer la tâche après avoir configuré tous les paramètres nécessaires.
- Démarrer la tâche manuellement ou automatiquement. Si l’utilisateur a configuré la tâche pour démarrer manuellement, il peut la démarrer en sélectionnant la tâche et en cliquant sur Démarrer maintenant. Si elle est configurée pour démarrer selon un calendrier, elle s’exécutera automatiquement aux heures spécifiées.
- Après avoir effectué la tâche, un dossier d’archive sera créé sur le système de fichiers du serveur DataSunrise où la tâche a été exécutée (sur les distributions Linux, le chemin par défaut sera /opt/datasunrise/).
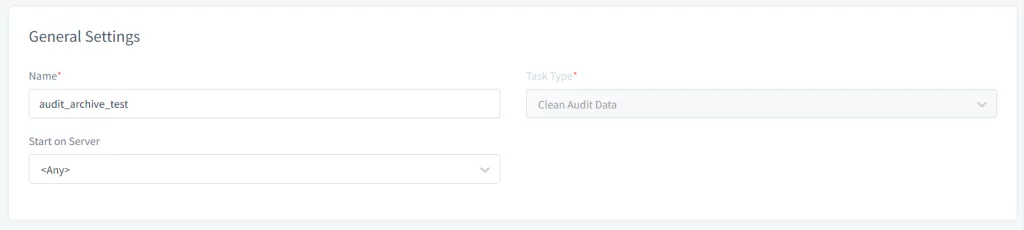
Image 1. Paramètres généraux
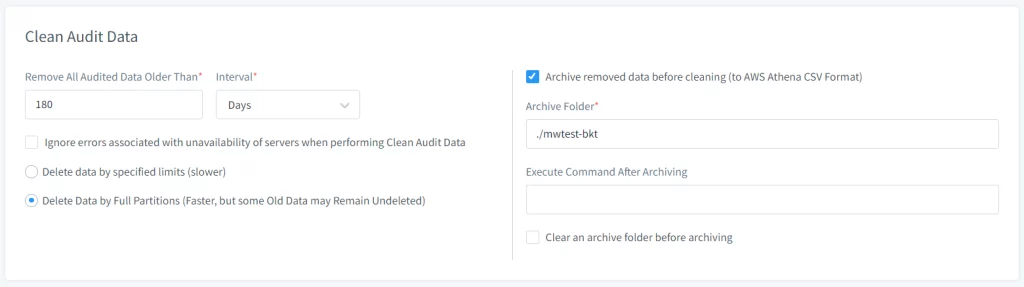
Image 2. Tâche périodique de nettoyage d’audit
Remarque: si vous exécutez DataSunrise sur AWS ECS Fargate, utilisez le ecs_upload_ds_audit_to_aws_s3.sh à la place situé dans le même répertoire.
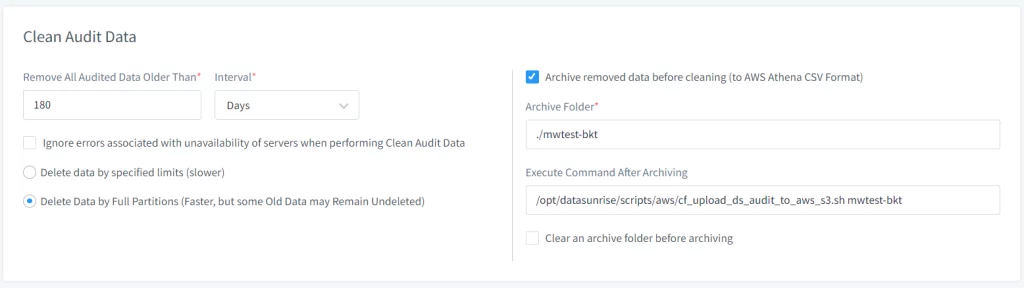
Image 3. Commandes supplémentaires pour la tâche de nettoyage des audits
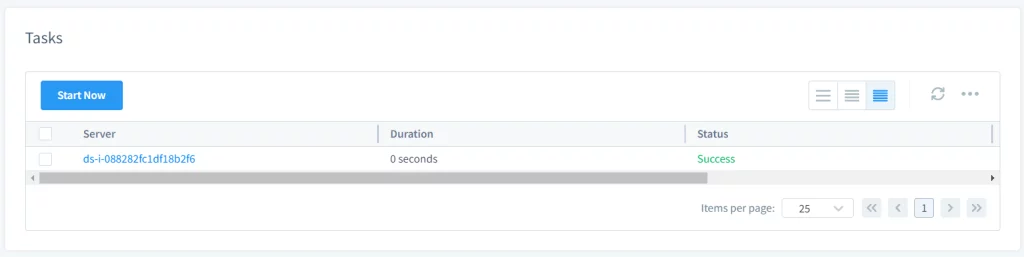
Image 4. Démarrer la tâche
Remarque: Les étapes ci-dessus peuvent également être utilisées pour gérer la retenue des données d’audit dans DataSunrise. Les utilisateurs peuvent utiliser la fonction “Nettoyage périodique des audits” pour supprimer régulièrement les données d’audit obsolètes. Cela permet d’assurer l’efficacité du serveur DataSunrise en évitant la surcharge de stockage avec des données obsolètes.
Le Script Uploader de Données d’Audit Archivées
Pour téléverser le dossier d’archive vers un seau AWS S3, utilisez le script fourni par DataSunrise situé dans le dossier
Pour personnaliser la procédure, vous pouvez utiliser les drapeaux optionnels suivants:
- –archive-folder: remplacez le dossier par défaut sur le serveur DataSunrise pour placer les fichiers de données d’audit archivés. Par défaut, le dossier ds-audit-archive sera créé à l’emplacement /opt/datasunrise/.
- –folder-in-bucket: fournissez votre propre préfixe pour placer les données auditées. Par défaut, le script décharge les données dans le préfixe
- –predefined-credentials: Si vous exécutez DataSunrise en dehors d’AWS, pour pouvoir téléverser des données vers S3, vous aurez besoin soit d’un fichier de coordonnées soit d’une paire de clé d’accès / de clé secrète pour l’utilisateur IAM autorisé à accéder au seau S3 désiré. Ne nécessite aucune entrée.
Remarque: La taille du dossier est surveillée pendant le déchargement de l’audit, et lorsqu’elle dépasse un certain seuil, la commande est exécutée. Si aucun script n’est spécifié, une erreur se produit lorsque le seuil est dépassé. Le seuil est défini à l’aide du paramètre additionnel “AuditArchiveFolderSizeLimit”, avec une valeur par défaut de 1 GB. Un utilisateur peut pré-nettoyer un dossier d’archive en utilisant l’option “Nettoyer un dossier d’archive avant archivage”.
Considérations
- Le nom du seau pour téléverser les données archivées doit être fourni sans le schéma s3://
Structure du dossier d’archive d’audit
La structure du dossier d’archive où DataSunrise stocke les données d’audit suit généralement un format hiérarchique organisé par date. Cette organisation aide à gérer les données de manière efficace et facilite la localisation des enregistrements d’audit spécifiques en fonction de la date. Voici un aperçu général de ce à quoi la structure peut ressembler :
Modèle de structure de dossier généralisé
Répertoire de base : /opt/datasunrise/ds-audit-archive/
└── Année : {AAAA}/
└── Mois : {MM}/
└── Jour : {JJ}/
└── Fichiers d'audit : audit_data_{AAAA}-{MM}-{JJ}.csv.gzRemarque: Les fichiers seront compressés et devront être décompressés pour lire les informations (par exemple, les utilisateurs peuvent utiliser la commande gunzip).
Une fois que les données d’audit sont téléchargées vers le S3, la structure est préservée de la même manière que sur le serveur DataSunrise :
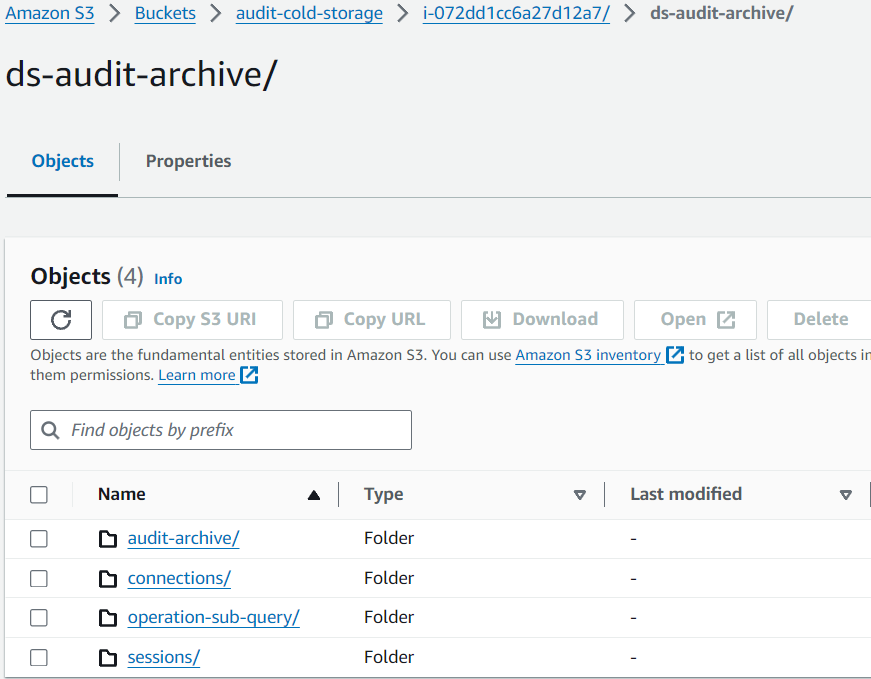
Image 5. Données dans le seau Amazon S3
Utilisation d’AWS Athena pour lire les données d’archive d’audit depuis S3
Une fois que les données d’audit sont téléchargées vers le S3, vous pouvez créer le schéma de base de données d’audit dans le service AWS Athena pour une analyse ultérieure. Passez à AWS Athena dans AWS Management Console pour configurer des objets Database et ExternalTable pour lire vos données archivées.
Créer des tables d’archive d’audit dans AWS Athena
Les scripts SQL supposent les éléments suivants pour la clause LOCATION des requêtes CREATE EXTERNAL TABLE:
- Le nom du seau S3 est datasunrise-audit
Le fichier SQL DDL pour les tables d’archive d’audit d’AWS Athena est également disponible à partir de la distribution DataSunrise avec le chemin par défaut /opt/datasunrise/scripts/aws/aws-athena-create-audit-archive-tables.sql.
-- La requête suivante crée une base de données dans Athena
CREATE DATABASE IF NOT EXISTS datasunrise_audit;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.audit_archive (
operations__id STRING,
operations__session_id STRING,
operations__begin_time STRING,
operations__end_time STRING,
operations__type_name STRING,
operations__sql_query STRING,
operations__exec_count STRING,
sessions__user_name STRING,
sessions__db_name STRING,
sessions__service_name STRING,
sessions__os_user STRING,
sessions__application STRING,
sessions__begin_time STRING,
sessions__end_time STRING,
connections__client_host_name STRING,
connections__client_port STRING,
connections__server_port STRING,
connections__sniffer_id STRING,
connections__proxy_id STRING,
connections__db_type_name STRING,
connections__client_host STRING,
connections__server_host STRING,
connections__instance_id STRING,
connections__instance_name STRING,
operation_rules__rule_id STRING,
operation_rules__rule_name STRING,
operation_rules__chain STRING,
operation_rules__action_type STRING,
operation_exec__row_count STRING,
operation_exec__error STRING,
operation_exec__error_code STRING,
operation_exec__error_text STRING,
operation_group__query_str STRING,
operations__operation_group_id STRING,
operations__all_exec_have_err STRING,
operations__total_affected_rows STRING,
operations__duration STRING,
operations__type_id STRING,
connections__db_type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/audit-archive/' -- chemin vers le dossier S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La requête suivante charge les partitions pour pouvoir interroger les données.
MSCK REPAIR TABLE datasunrise_audit.audit_archive;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.sessions (
partition_id STRING,
id STRING,
connection_id STRING,
host_name STRING,
user_name STRING,
scheme STRING,
application STRING,
thread_id STRING,
process_id STRING,
begin_time STRING,
end_time STRING,
error_str STRING,
params STRING,
db_name STRING,
service_name STRING,
os_user STRING,
external_user STRING,
domain STRING,
realm STRING,
sql_state STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/sessions/' -- chemin vers le dossier S3
TBLPROPERTIES ('has_encrypted_data'='false','skip.header.line.count'='1');
-- La requête suivante charge les partitions pour pouvoir interroger les données.
MSCK REPAIR TABLE datasunrise_audit.sessions;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.connections (
partition_id STRING,
id STRING,
interface_id STRING,
client_host STRING,
client_port STRING,
begin_time STRING,
end_time STRING,
client_host_name STRING,
instance_id STRING,
instance_name STRING,
proxy_id STRING,
sniffer_id STRING,
server_host STRING,
server_port STRING,
db_type_id STRING,
db_type_name STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/connections/' -- chemin vers le dossier S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La requête suivante charge les partitions pour pouvoir interroger les données.
MSCK REPAIR TABLE datasunrise_audit.connections;
--------------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.operation_sub_query (
operation_sub_query__operation_id STRING,
operation_sub_query__session_id STRING,
operation_sub_query__type_name STRING,
operations__begin_time STRING,
operation_sub_query__type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/operation-sub-query/' -- chemin vers le dossier S3
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- La requête suivante charge les partitions pour pouvoir interroger les données. MSCK REPAIR TABLE datasunrise_audit.operation_sub_query; --------------------------------------------------------------------- CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.session_rules ( session_id STRING, rule_id STRING, rule_name STRING, chain STRING, action_type STRING, sessions__begin_time STRING ) PARTITIONED BY ( `year` STRING, `month` STRING, `day` STRING ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( 'separatorChar' = ',', 'quoteChar' = '\"', 'escapeChar' = '\\' ) LOCATION 's