Masquage des Données sur Place
Un des moyens de protéger les données sensibles dans les bases de données est le masquage des données. Dans cet article, nous allons en apprendre davantage sur le masquage des données sur place et les étapes pour masquer vos données sur place en utilisant DataSunrise Database Security.
Masquage Statique et Masquage sur Place
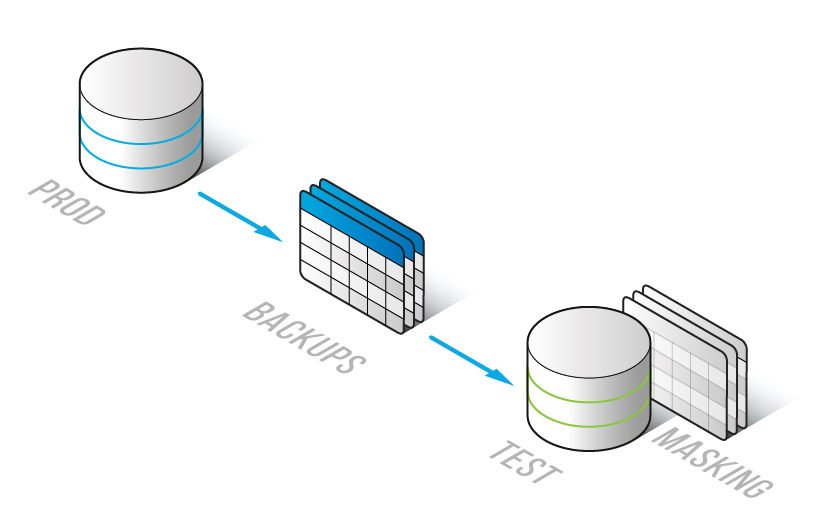
Le Masquage sur place ressemble au masquage statique car les données masquées sont masquées de manière persistante, et ce processus ne peut pas être inversé.
La différence entre le masquage sur place et le masquage statique est que dans le masquage statique, nous avons 2 bases de données :
- base de données source contenant les données originales
- base de données cible avec des données masquées
Dans le cas du masquage sur place, nous avons une seule base de données qui est à la fois source et cible.
Le masquage sur place est mieux utilisé comme partie d’une approche de protection des bases de données hybride où différentes bases de données sont protégées en utilisant différents types de masquage :
- masquage statique
- masquage sur place
- masquage dynamique
Tous ces types de masquage sont disponibles dans la suite de protection des bases de données DataSunrise pour garantir que vos bases de données sont protégées à tout moment.
Masquage sur Place en Pratique
Parfois, le masquage statique n’est pas une bonne option :
- il donne une charge supplémentaire sur la base de données de production.
- il nécessite un accès de l’environnement de test à l’environnement de production. Dans certaines architectures système, c’est physiquement impossible.
Dans ce cas, les données peuvent être répliquées dans l’environnement de test en utilisant des sauvegardes de la base de données de production. Les sauvegardes de toute base de données de production sont effectuées régulièrement. Donc, nous avons seulement besoin de :
- restaurer la base de données dans l’environnement de test
- masquer les données dans notre environnement de test, où les données sensibles originales sont perdues car elles sont remplacées par des données masquées
Cette méthode de masquage est appelée « masquage sur place » parce que les données sont masquées là où elles résident. Utilisez cette méthode uniquement dans des bases de données non-produites.
DataSunrise essaie de préserver (reconstruit après le masquage) toutes les contraintes uniques, les clés étrangères, les index, les contraintes de vérification et les contraintes par défaut dans une base de données. Cependant, ce n’est pas toujours possible. Les compteurs d’auto-incrémentation sont également préservés (sauf pour les bases de données Redshift).
Le filtrage sur place des tables fonctionne de la même manière que dans le masquage statique, c’est-à-dire que les données ne respectant pas les conditions de filtrage sont définitivement supprimées.
Étapes du Masquage sur Place avec DataSunrise
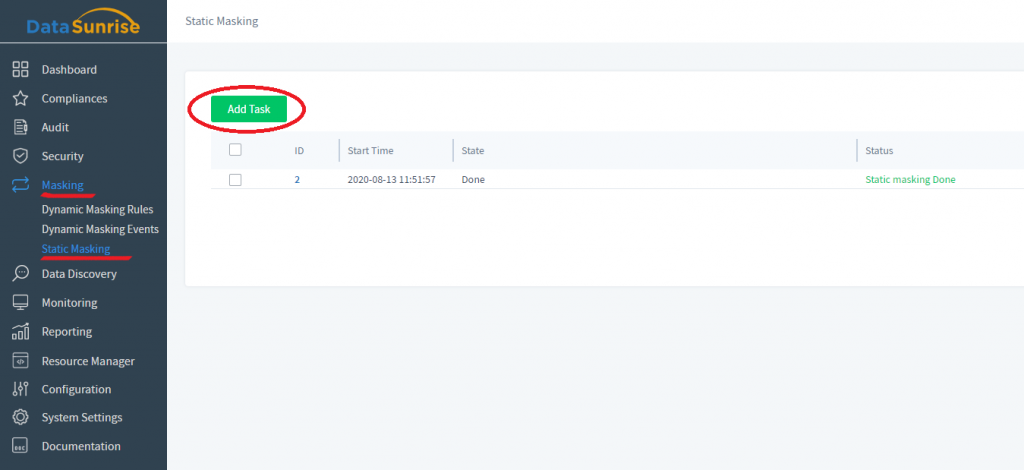
1) Si vous souhaitez masquer les données sur place, choisissez Masquage → Masquage statique dans le panneau de gauche de l’interface Utilisateur de DataSunrise. Ensuite, cliquez sur Ajouter une tâche. Toutes les tâches de masquage sur place précédentes seront enregistrées ici pour votre référence.
2) Après cela, choisissez l’instance source. Dans le champ instance cible, choisissez Masquer sur Place. N’oubliez pas de sauvegarder vos données, car à la suite du masquage sur place les données originales sont définitivement remplacées par des données masquées. Après cela, choisissez une base de données que vous souhaitez masquer sur place et un schéma. Dans l’image ci-dessous, cette base de données s’appelle “sales_summer” et le schéma est “public”. Dans la section Tables transférées ci-dessous, certaines cases sont cochées automatiquement pour assurer un meilleur masquage.
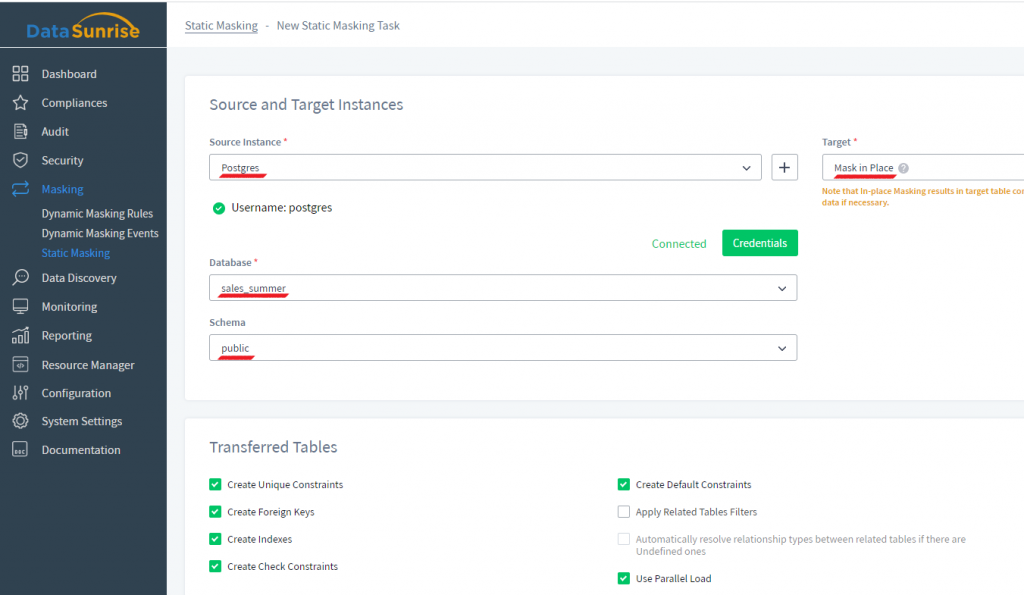
Voici ce que ces cases à cocher font :
- Créer des Contraintes Uniques, Créer des Clés Étrangères, Créer des Index, Créer des Contraintes de Vérification, Créer des Contraintes par Défaut signifient que ces éléments doivent être reconstruits dans le schéma masqué, si c’est possible.
- Utiliser le Chargement en Parallèle – augmente la vitesse de masquage pour les grandes tables.
- Appliquer les Filtres aux Tables Connexes – le filtre sera appliqué non seulement à une table spécifiée, mais aussi aux tables liées à cette table via des clés étrangères.
- Résoudre automatiquement les types de relations entre les tables liées s’il y en a des indéfinies – cela signifie que les tables liées ne seront pas découvertes uniquement par l’outil de Relations de Table (Configuration → Relations de Table dans l’interface utilisateur DataSunrise), mais aussi en fonction d’un algorithme utilisant les relations de table indirectes.
3) Faites défiler vers le bas et cliquez sur Sélectionner sous la section Tables transférées.
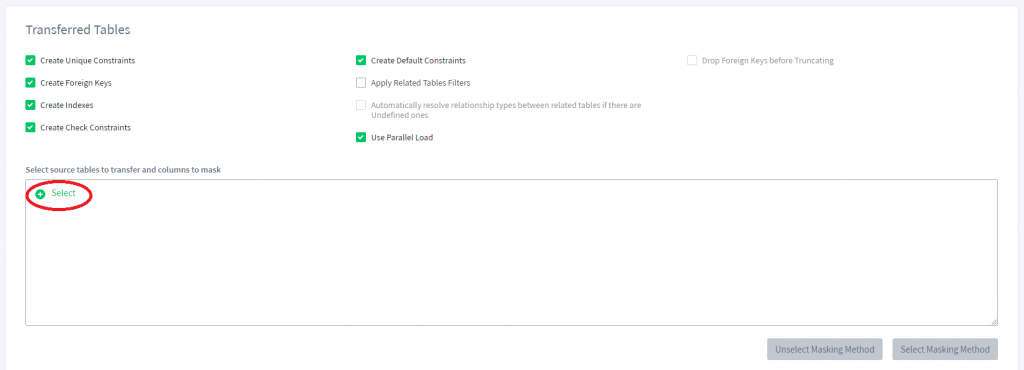
4) Maintenant, sélectionnons l’ensemble du schéma où nous voulons sélectionner plusieurs tables (chez nous, c’est le schéma “public”) et cliquez sur Terminé.
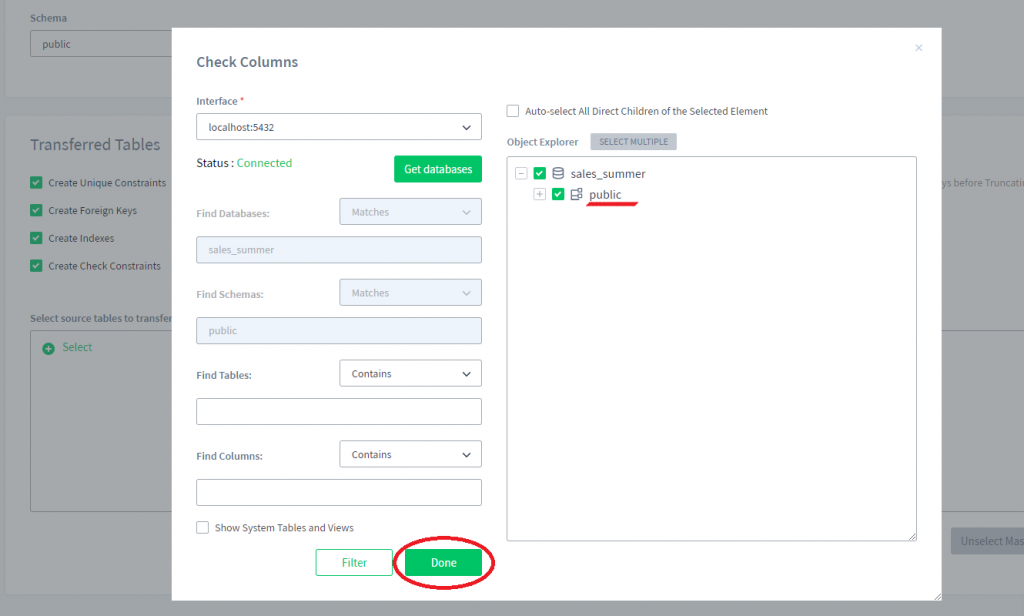
5) Maintenant, nous pouvons développer le schéma “public” sélectionné et choisir des colonnes à masquer.
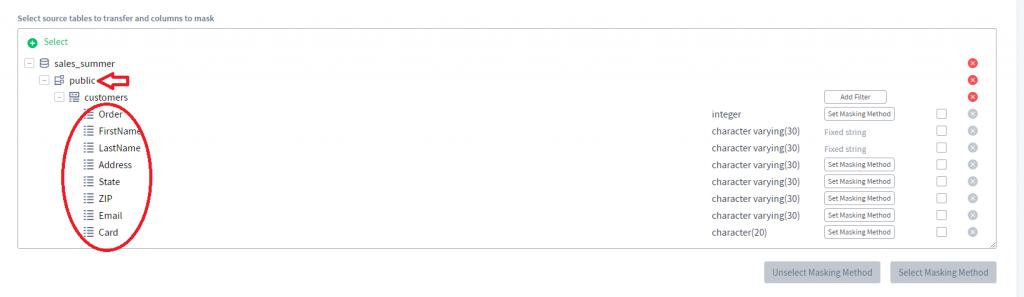
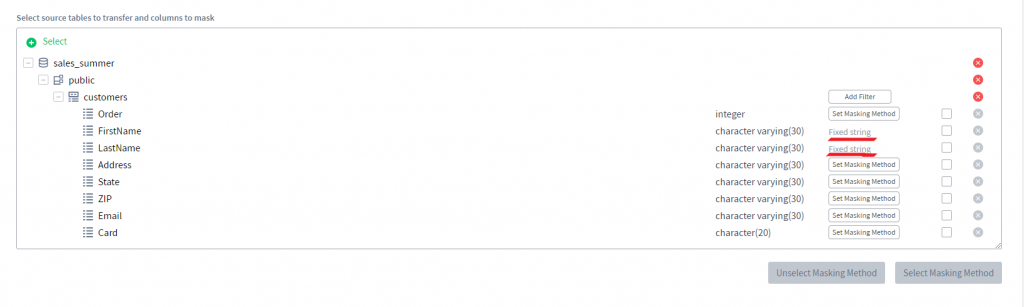
6) Pour chacune des colonnes, vous pouvez définir une méthode de masquage en cliquant sur le bouton Définir la méthode de masquage. Masquons les colonnes FirstName et LastName en utilisant une chaîne fixe.
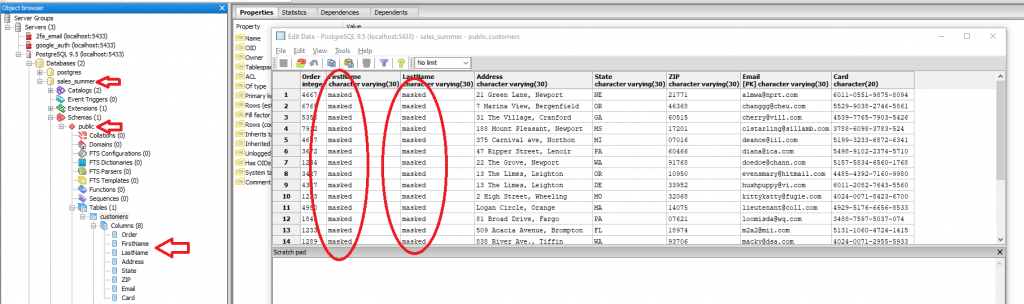
Dans l’image ci-dessous, vous pouvez voir à quoi ressemblent nos données maintenant dans notre table PostgreSQL. Comme vous pouvez le voir, les colonnes FirstName et LastName sont maintenant masquées sur place.
Le masquage sur place de DataSunrise est un outil très pratique pour garder vos données sensibles masquées et sous contrôle à tout moment.