
Intégration de DataSunrise avec Splunk Enterprise
Splunk Enterprise est une plateforme pour l’intelligence opérationnelle. Elle est utilisée pour collecter et évaluer les grandes quantités de données générées par diverses applications. Splunk Enterprise offre de nombreuses fonctionnalités mais pour les besoins de DataSunrise, il peut être utilisé pour l’agrégation des journaux d’audit.
Dans ce manuel, nous décrivons comment configurer Splunk Enterprise pour l’intégrer avec DataSunrise. Les résultats d’audit des données sont exportés de DataSunrise vers Splunk via Syslog. À des fins de démonstration, une copie d’essai de Splunk Enterprise est utilisée. Vous pouvez la télécharger à partir du site officiel. Avant d’essayer d’utiliser Splunk pour collecter des journaux d’audit de données, configurez Syslog de DataSunrise.
Pour ce faire, entrez dans l’interface GUI de DataSunrise, “Configurations” -> “Paramètres Syslog”, “Paramètres Syslog” et configurez un serveur Syslog distant (voir la capture d’écran ci-dessous). Étant donné que notre Splunk est installé sur notre PC où DataSunrise est installé, la valeur de l’hôte du serveur est 127.0.0.1. Le numéro de port est 514.
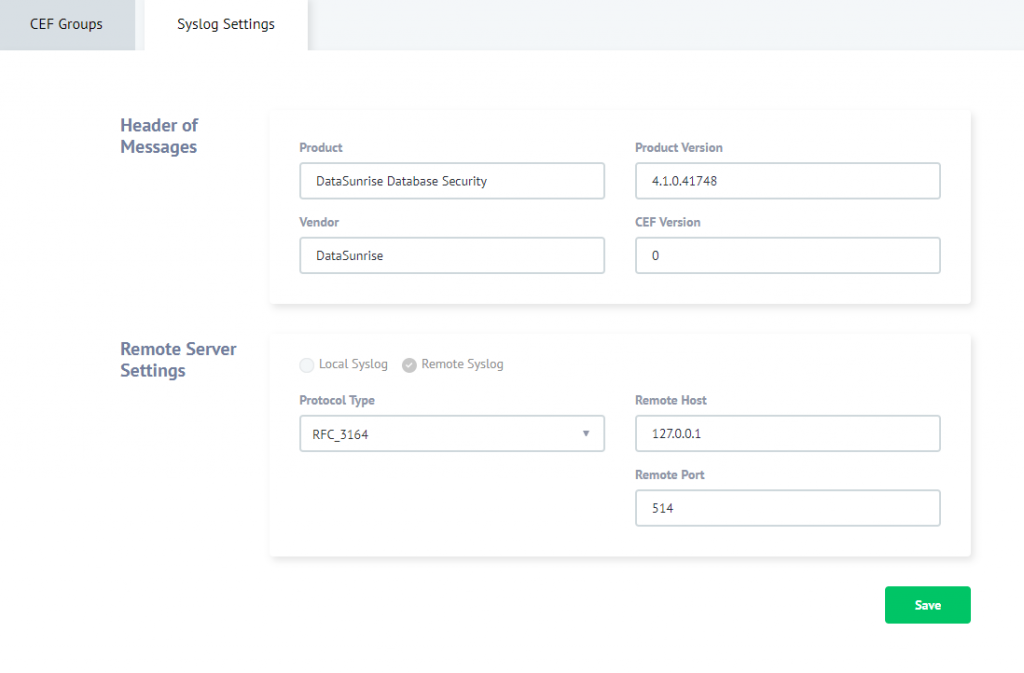
Ensuite, naviguez vers “Configurations” -> “Paramètres Syslog” et créez un nouveau groupe CEF si nécessaire ou utilisez le “groupe par défaut”. Vous devez inclure dans le groupe les événements que vous souhaitez transférer à Syslog.
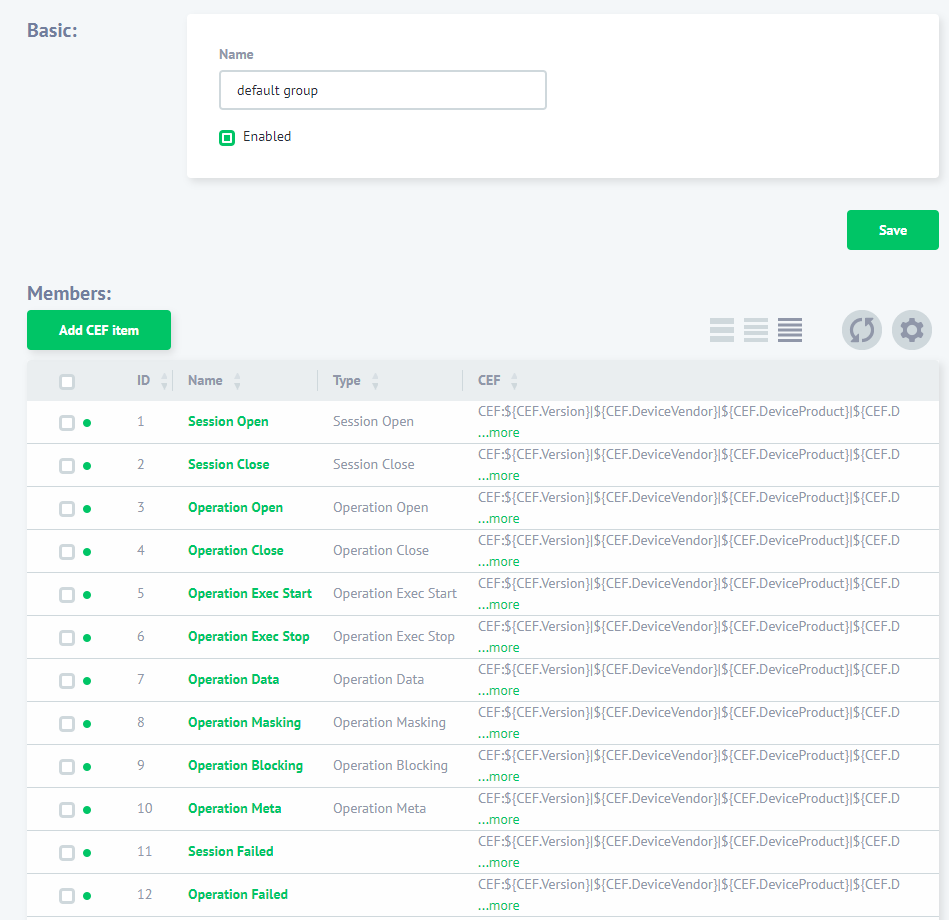
Ensuite, créez une règle DataSunrise et dans les paramètres de la règle, sous-section “Actions”, sélectionnez votre groupe CEF dans la liste déroulante “Configuration Syslog”. Cela vous permettra de transmettre les données d’audit collectées par DataSunrise à Splunk via Syslog. Pour plus de détails, consultez le guide de l’utilisateur DataSunrise. Ensuite, dans “Filter Statements”, sélectionnez “Sessions Events” et spécifiez les événements de session pour envoyer des messages Syslog.
Il existe des versions de Splunk Enterprise pour les systèmes d’exploitation Windows, UNIX et Mac OS, de sorte que chaque version de programme a ses propres spécificités. Dans ce guide, nous décrivons l’installation de Splunk sur Windows et Linux. Pour préparer le programme au travail, effectuez les opérations suivantes :
Installation de Splunk Enterprise
Windows
Effectuez la procédure d’installation standard pour les applications Windows. Consultez le guide d’installation officiel si nécessaire.
Linux
Effectuez la procédure d’installation standard pour les applications Linux. Consultez le guide d’installation officiel si nécessaire.
Démarrage de Splunk Enterprise
Windows
Exécutez l’invite de commande Windows, déplacez-vous vers le dossier d’installation de Splunk avec la commande “cd” et exécutez la commande “splunk start”. (Par exemple, si Splunk a été installé dans le dossier par défaut, utilisez la commande suivante : cd C:\Program Files\Splunk\bin splunk start). Vous pouvez également créer la variable d’environnement %SPLUNK_HOME% pour simplifier le processus de démarrage de Splunk. Consultez le guide de démarrage officiel si nécessaire.
Linux
Exécutez la commande suivante via l’invite de commande Linux : sudo /bin/splunk start . Vous pouvez également créer la variable d’environnement SPLUNK_HOME pour démarrer le programme avec la commande suivante : export SPLUNK_HOME= $SPLUNK_HOME/bin/splunk start
Configuration de Syslog pour Splunk
1. Entrez dans l’interface GUI de Splunk. Pour ce faire, ouvrez l’adresse suivante via votre navigateur Web : localhost:8000. Sur la page de connexion, utilisez “admin” comme登录 et “changeme” comme mot de passe (Splunk vous demandera de définir un nouveau mot de passe).
2. À la page de démarrage de l’interface GUI, cliquez sur le bouton Ajouter des données.

3. Ensuite, sur la page suivante, cliquez sur “Moniteur” pour l’onglet “Sélectionner la source”.

4. Dans l’onglet “Sélectionner les données sources”, sélectionnez le protocole TCP/UDP. Sélectionnez le port UDP en activant l’interrupteur correspondant. Spécifiez le numéro de port d’écoute (port 514). Laissez les autres paramètres dans leur état par défaut. Passez à l’onglet suivant en appuyant sur Suivant.

5. Dans l’onglet “Paramètres d’entrée”, utilisez la liste déroulante “Sélectionner le type de source” pour sélectionner Système d’exploitation -> Syslog. Cliquez sur “Réviser” pour passer à l’étape suivante.

6. Dans l’onglet “Réviser”, vérifiez vos paramètres : type d’entrée — UDP, numéro de port — 514, type de source — Syslog. Cliquez sur Soumettre pour terminer la configuration.
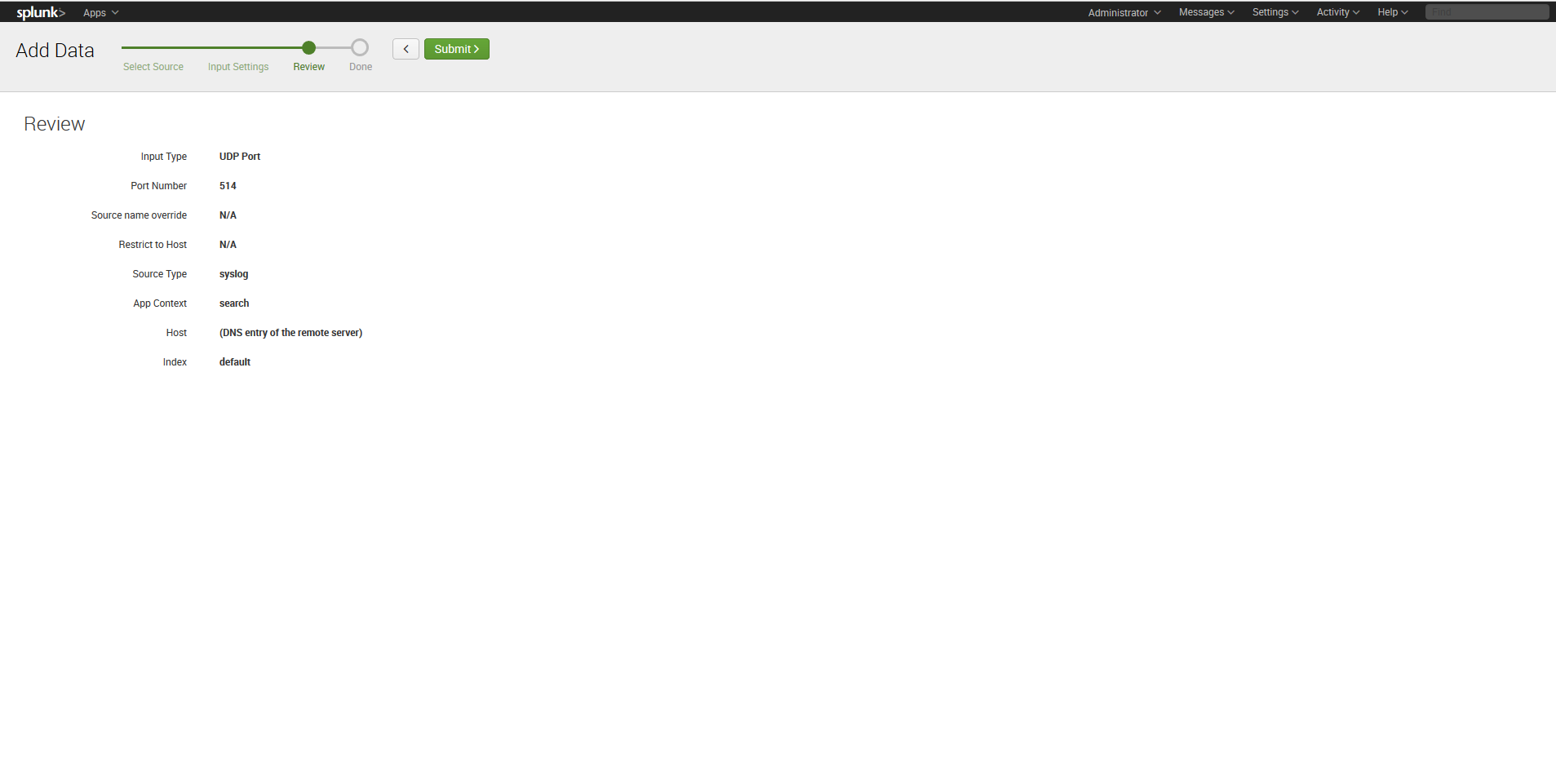
7. Une fois la configuration terminée, cliquez sur “Commencer la recherche” pour rechercher des journaux.

8. Étant donné que DataSunrise crée des journaux pendant son fonctionnement, vous ne verrez probablement pas d’entrées. C’est pourquoi vous devez configurer les règles d’audit DataSunrise si ce n’est pas déjà fait. Effectuez les actions nécessaires pour que DataSunrise crée des journaux d’audit et actualisez la page de recherche dans Splunk.
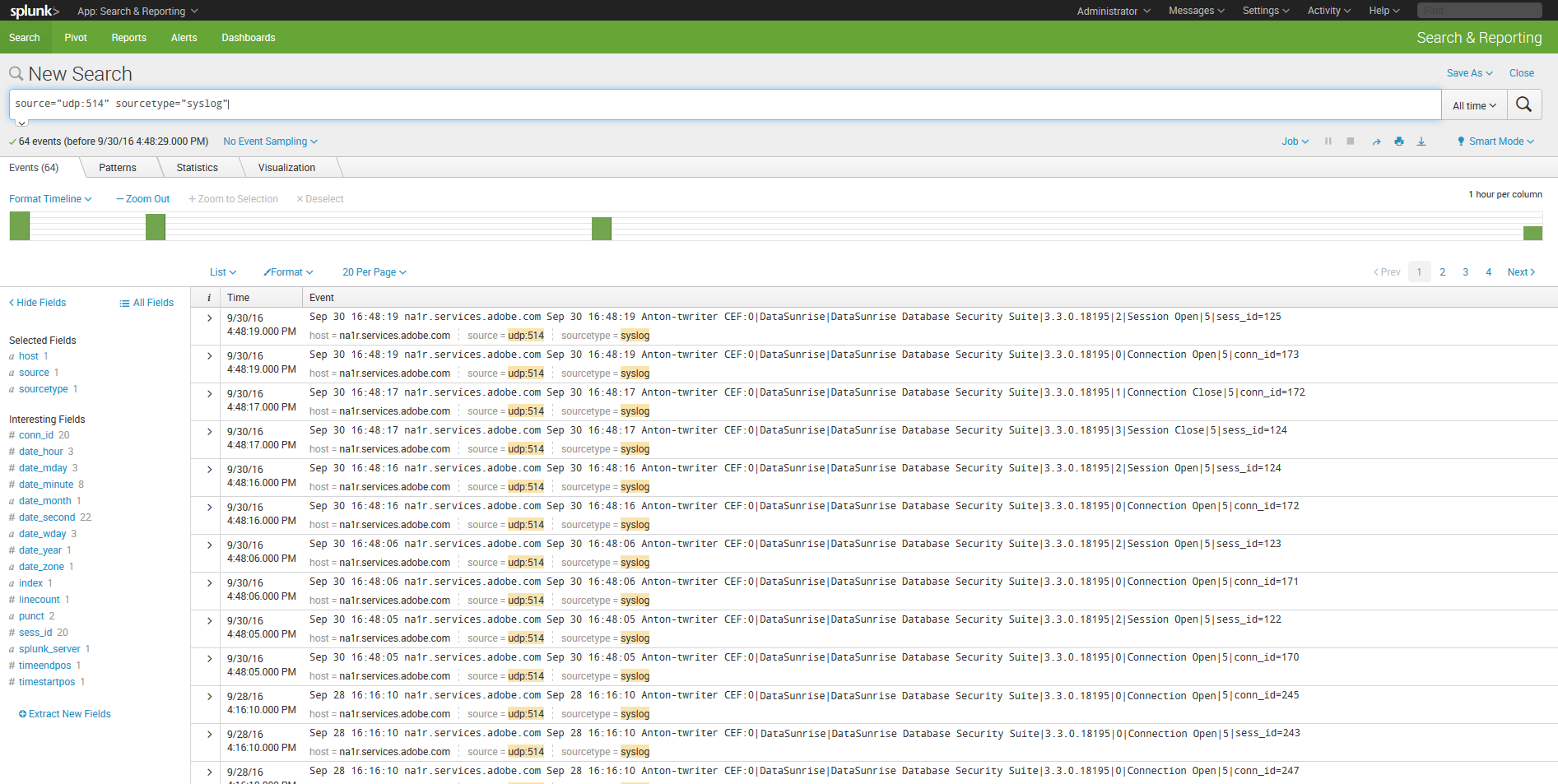
9. Pour voir les détails d’un événement, cliquez sur > dans la colonne “I” de l’événement requis. Puis utilisez la liste déroulante Actions sur les événements pour sélectionner Extraire des champs afin de visualiser les informations détaillées.

10. Un nouvel onglet de navigateur s’ouvrira. Vous devez choisir une méthode d’extraction. Expressions régulières — en tant qu’expressions régulières ou Délimiteurs — extraction avec des virgules, des espaces et des caractères. Cette méthode est recommandée pour les données séparées par des caractères (fichiers CSV par exemple).

11. Après avoir sélectionné une méthode appropriée, cliquez sur suivant pour commencer l’extraction.
DataSunrise prend en charge toutes les principales bases de données et entrepôts de données tels qu’Oracle, Exadata, IBM DB2, IBM Netezza, MySQL, MariaDB, Greenplum, Amazon Aurora, Amazon Redshift, Microsoft SQL Server, Azure SQL, Teradata et plus encore. Vous êtes invité à télécharger une version d’essai gratuite si vous souhaitez l’installer chez vous. Si vous êtes un utilisateur cloud et que vous exécutez votre base de données sur Amazon AWS ou Microsoft Azure vous pouvez l’obtenir depuis le AWS market place ou le Azure market place.
