
Amazon S3 Nouvelles capacités de découverte de données sensibles par DataSunrise
Introduction
Selon une enquête récente, plus de 50 % des entreprises hébergent une grande quantité de données sensibles dans des stockages cloud, comme S3 d’Amazon.
La découverte de données sensibles de DataSunrise est disponible pour la recherche rapide, la classification et la gestion des données. La recherche et l’analyse des données dans vos stockages de données vous permettent de repérer les données sensibles dans Amazon S3 à temps, rapidement et sans effort. Nous avons amélioré notre outil. Auparavant, nous pouvions découvrir des données semi-structurées et non structurées dans S3 grâce à la fonction NLP, et maintenant nous pouvons encore plus.
Découverte de données sensibles de DataSunrise
La découverte de données pour Amazon S3 dispose de nouvelles capacités pour la détection et la protection des données sensibles. Désormais, la découverte de données est disponible pour :
- Le format de fichier Apache Parquet ;
- Des fichiers semi-structurés comme XML, JSON, CSV ;
- Des formats de texte non structurés comme les documents Microsoft Word ;
- Les images.
La découverte de données pour S3 analyse non seulement les objets mais aussi leurs noms et chemins. DataSunrise relie les relations sémantiques avec le contexte de l’objet pour une découverte complète et exhaustive des données sensibles. Vous n’avez donc pas besoin de vous préoccuper des noms spécifiques des objets contenant des informations sensibles et privées.
Modèles prédéfinis et personnalisés pour les PII. DataSunrise dispose de nombreux modèles prédéfinis pour la recherche de données sensibles comme les numéros de carte de crédit, les passeports, les permis de conduire. Pour une recherche plus flexible, vous pouvez utiliser des types d’informations personnalisées (qui peuvent être configurés à l’aide d’expressions régulières, de scripts Lua, etc.). Grâce à ces filtres, vous aurez une image exhaustive des données sensibles collectées. Le réglage fin de la découverte vous fera gagner du temps et des ressources. Le plus important est que vous serez sûr qu’aucune donnée sensible n’est pas sous votre contrôle et peut entraîner une exposition des données.
Découverte de données à la demande. Vous pouvez créer et exécuter la découverte de données non seulement manuellement via la console Web. Utilisez le terminal système avec l’Interface en ligne de commande pour créer des systèmes automatisés qui répondent aux événements de sécurité sans intervention manuelle.
Découverte de données sensibles dans les images. Les entreprises qui stockent des données sensibles dans des images (permis de conduire, SSN, etc.) seront ravies d’utiliser la découverte de données de DataSunrise avec la reconnaissance optique des caractères. L’utilisation de la découverte d’images vous permet de rechercher des données sensibles dans les images grâce au moteur OCR. Il extrait le texte des images, analyse ces informations et trouve des données privées dans les documents. Notre découverte de données dans les images prend en charge les formats de fichiers suivants : JPG, PNG, GIF, TIFF, PSD.
Découverte de données dans les fichiers compressés et archivés. En plus des objets et des différents formats de fichiers, la découverte de données pour S3 peut également rechercher des données sensibles dans des formats compressés et archivés. Les fichiers compressés vous permettent de réduire l’espace utilisé, économisant ainsi les coûts. Les fichiers archivés vous permettent de collecter et de regrouper des fichiers en un seul endroit en les combinant. Quelle que soit la taille de l’archive, les données sensibles seront découvertes.
Performances de la découverte de données sensibles
La découverte de données sensibles fonctionne à différents niveaux dans S3. Tout d’abord, vous pouvez découvrir vos seaux S3 et objets pour les informations sensibles. C’est le moyen le plus simple de trouver des informations privées à protéger. Mais lorsque vous avez beaucoup de seaux S3 et d’objets en eux, cette tâche sera chronophage et fatigante. Avec DataSunrise, vous pourrez économiser votre temps, votre budget et d’autres ressources car désormais DataSunrise prend en charge plusieurs techniques pour augmenter les performances.
Inventaire AWS S3. Il conserve toutes les métadonnées sur vos seaux S3 en un seul endroit sous la forme d’un fichier CSV archivé. Pour réduire la consommation de trafic et les coûts d’opération, DataSunrise peut obtenir ces métadonnées à l’aide de l’inventaire S3 sans appels d’API AWS.
Découverte de données incrémentale. Avec la découverte de données incrémentale, il n’est pas nécessaire de répéter la découverte des mêmes objets et seaux pour la présence de données sensibles. Le mode de balayage incrémental ignore les seaux et objets découverts plus tôt. Il ne numérise que les objets nouveaux ou mis à jour, en les comparant avec le dernier temps scanné. Cela vous aide à gagner du temps et de l’argent lors de la manipulation de gros volumes de données. De plus, la numérisation incrémentale est facultative, vous pouvez donc la désactiver à tout moment que vous en avez besoin.
Découverte de données en parallèle. Pour la recherche rapide de données sensibles dans de gros volumes de données, vous pouvez utiliser le traitement multiprocesseur implémenté. Il permet l’utilisation de plusieurs serveurs DataSunrise pour la découverte de données en parallèle. Avec la découverte en parallèle, vous pourrez optimiser l’utilisation du CPU et de la mémoire. L’utilisation du multiprocesseur simplifie le travail de la découverte de données lorsque vous devez traiter une énorme quantité de données. Cela réduit également la charge sur le serveur et n’impacte pas les processus parallèles que vous avez. Avec le multiprocesseur, vous pouvez choisir plusieurs attributs de recherche et exclure des objets spécifiques de la numérisation.
Découverte de données aléatoire. Elle permet de numériser des fichiers aléatoires dans les seaux S3 pour accélérer le processus de découverte de données. Il est possible de choisir le pourcentage de données sensibles à découvrir parmi de grands volumes de données.
Division des gros fichiers en morceaux. Les gros objets consomment de l’espace supplémentaire pour les calculs en mémoire. Désormais, nous pouvons diviser n’importe quel objet en morceaux pour augmenter les performances et optimiser l’utilisation de la mémoire. Avec des paramètres supplémentaires comme “DataDiscoveryChunkSize” et autres, nous pouvons facilement découvrir ces morceaux et trouver toute information sensible.
Paramètres et personnalisation de la découverte de données sensibles
Vous pouvez peaufiner le processus de découverte en ajustant quelques paramètres supplémentaires.
DataSunrise dispose de plus de 25 paramètres personnalisables. Par exemple :
- “DataDiscoveryMatchesSaveStrategy” permet d’enregistrer les occurrences de la découverte de données dans le dictionnaire en fonction de vos besoins particuliers : enregistrer les premières correspondances, toutes les correspondances ou les correspondances uniques ;
- “DataDiscoveryChunkSize” permet le téléchargement partiel des fichiers pour la découverte de données afin d’éviter le débordement de la mémoire. Vous pouvez définir la taille des morceaux et la limite de la somme des morceaux ;
- “DataDiscoveryMaxFileSizeForChunkProcessing” est pour la taille du fichier entier à scanner comme une somme de morceaux. Le traitement par morceaux scanne jusqu’à ce que la valeur de ce paramètre soit atteinte ;
- “DataDiscoveryS3FilePartToRead” est pour la taille maximale du fichier (Mb) pour la découverte de données S3. Ce paramètre fonctionne de concert avec DataDiscoveryFilesThreadPools. Il définit le nombre de threads utilisés pour le traitement des fichiers. Chaque thread traite un fichier à la fois. Ainsi, la valeur de ce paramètre dépend des ressources système disponibles.
- “DataDiscoveryBatchSplitFactor” identifie en combien de parties le lot échoué sera divisé pour la relance ultérieure de la tâche de découverte de données.
Rapports sur la découverte de données sensibles
DataSunrise offre une protection multi-niveaux pour AWS S3. En conséquence, DataSunrise traite une énorme quantité de données. Il vous permet d’obtenir toutes les informations les plus détaillées sur vos bases de données et les données qu’elles contiennent en créant des rapports personnalisés aux formats CSV ou PDF.
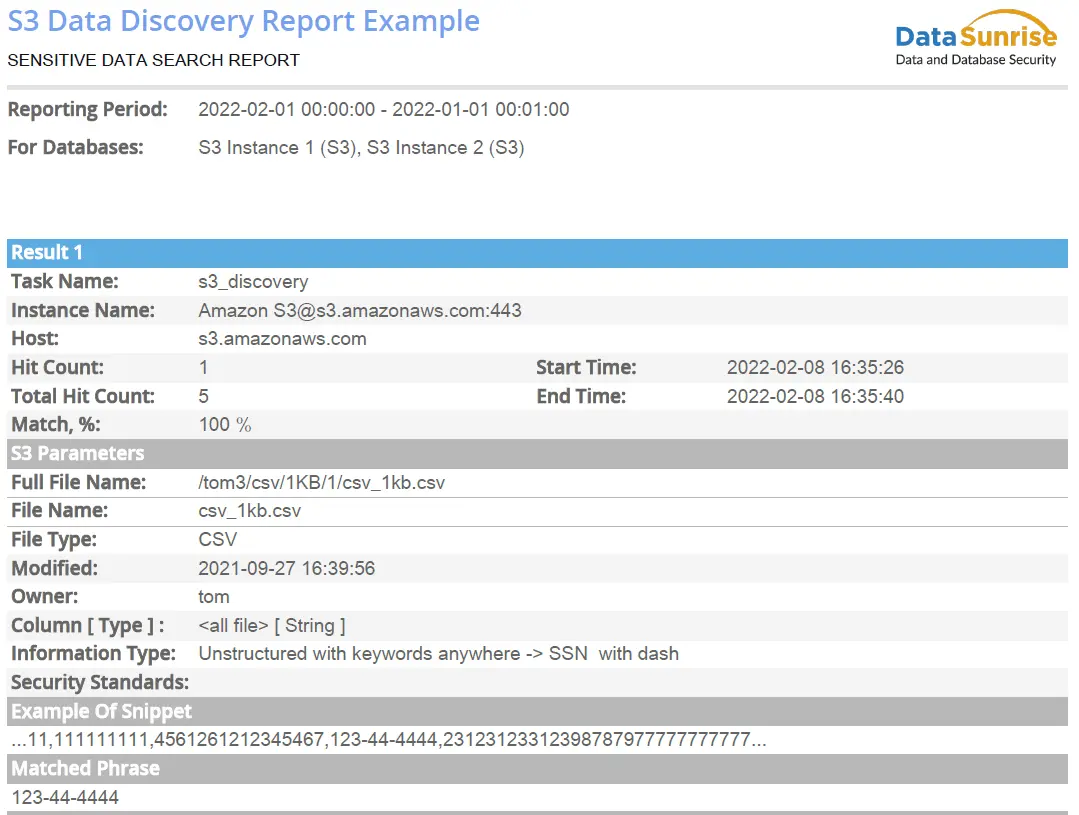
Image 1 : Exemple de rapport PDF de découverte de données sensibles
Disponibilité des rapports. Désormais, la génération de rapports est possible pendant le processus de tâche de découverte, il n’est pas nécessaire d’attendre que la tâche soit terminée. Cela vous permet de visualiser les résultats intermédiaires et de les utiliser pour des analyses.
Utilisation des rapports. Grâce aux résultats des rapports, vous pouvez collecter des analyses et obtenir des statistiques sur la vitesse de traitement des données et les attributs et utiliser les données reçues à des fins spécifiques, y compris pour enseigner votre propre IA.
Avec un système flexible de rapports personnalisables, vous n’avez plus besoin de surveiller manuellement les informations sur les niveaux de protection de vos bases de données.
Conclusion
La découverte de données sensibles vous permet de savoir où se trouvent les données sensibles dans vos seaux AWS S3 et d’utiliser les moyens de protection des données en conséquence.
DataSunrise offre une grande variété de formats et de moyens de découvrir des données sensibles dans AWS S3, où qu’elles se trouvent. Avec les performances améliorées, la découverte de données deviendra moins chronophage. Vous pouvez affiner la découverte de données sensibles de DataSunrise pour éviter les recherches répétées inutiles parmi de gros volumes de données. Les modèles de recherche éditables vous permettent d’effectuer une recherche pour n’importe quel élément de données spécifique. Avec les rapports, vous pouvez obtenir les informations les plus détaillées qui vous permettront de voir les résultats intermédiaires pour l’analyse, l’apprentissage de l’IA et d’autres processus métiers.
Pour commencer avec DataSunrise avec Amazon, visitez DataSunrise dans AWS Marketplace.
