
Qu’est-ce que le masquage de données ?
Le masquage de données, également connu sous le nom d’obfuscation des données, est le processus de remplacement des informations sensibles par des données réalistes mais non authentiques. Son objectif principal est de protéger les informations confidentielles, telles que les données personnelles, stockées dans des bases de données propriétaires. Cependant, un masquage efficace trouve un équilibre entre la sécurité et l’utilité, s’assurant que les données obfusquées restent adaptées aux activités essentielles de l’entreprise comme les tests logiciels et le développement d’applications.
Le masquage s’avère inestimable dans des situations telles que :
- une entreprise doit donner accès à sa ou ses base(s) de données à des entreprises informatiques externalisées et tierces. Lors du masquage des données, il est très important de les rendre cohérentes afin que les pirates et autres acteurs malveillants pensent qu’ils ont affaire à des données authentiques.
- une entreprise doit atténuer les erreurs des opérateurs. Les entreprises font généralement confiance à leurs employés pour prendre de bonnes décisions en matière de sécurité, cependant, bon nombre de violations résultent d’erreurs des opérateurs. Si les données sont masquées, les conséquences de telles erreurs ne sont pas si catastrophiques. De plus, il convient de mentionner que toutes les opérations dans les bases de données n’ont pas besoin de l’utilisation de données entièrement réelles et précises.
- une entreprise mène des tests basés sur les données.
Dans cet article, nous allons examiner de plus près le masquage statique, le masquage dynamique et le masquage en place.
Exemples de Données Masquées
Dans l’exemple ci-dessous, vous pouvez voir comment la colonne Carde apparaissait avant le masquage :
SQL> select * from scott.emp;
EMPNO ENAME JOB MGR HIREDATE CARD
--------- --------- ---------- ------- --------- -------------------
1 SMITH CLERK 0 17-DEC-80 4024-0071-8423-6700
2 SCOTT SALESMAN 0 20-FEB-01 4485-4392-7160-9980
3 JONES ANALYST 0 08-JUN-95 6011-0551-9875-8094
4 ADAMS MANAGER 1 23-MAY-87 5340-8760-4225-7182
4 rows selected.
Et après le masquage :
SQL> select * from scott.emp;
EMPNO ENAME JOB MGR HIREDATE CARD
--------- --------- ---------- ------- --------- -------------------
1 SMITH CLERK 0 17-DEC-80 XXXX-XXXX-XXXX-6700
2 SCOTT SALESMAN 0 20-FEB-01 XXXX-XXXX-XXXX-9980
3 JONES ANALYST 0 08-JUN-95 XXXX-XXXX-XXXX-8094
4 ADAMS MANAGER 1 23-MAY-87 XXXX-XXXX-XXXX-7182
4 rows selected.
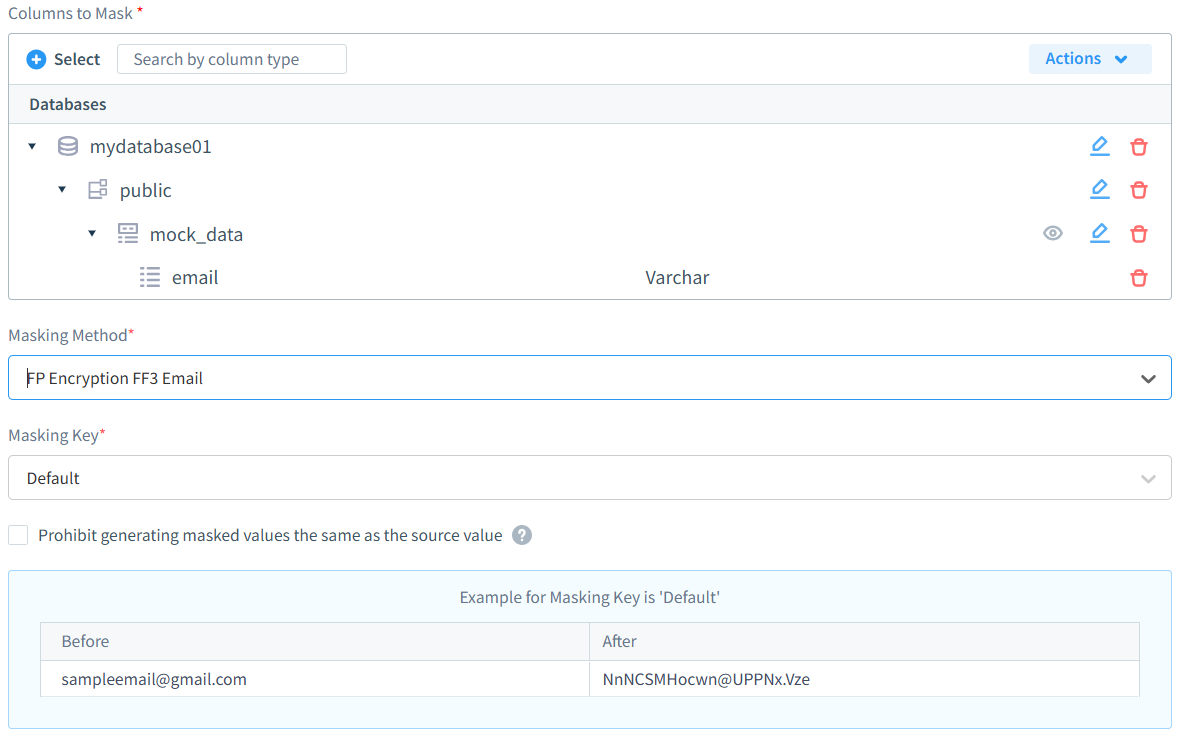
DataSunrise vous permet d’appliquer différentes méthodes de masquage à chaque champ. Vous pouvez choisir parmi les options préréglées ou créer des règles de masquage personnalisées pour des types de données spécifiques. Le masquage préservant le format maintient la structure des données tout en protégeant les informations sensibles. Cela garantit que les données masquées restent utilisables et conservent leurs propriétés statistiques.
| Méthode de Masquage | Données Originales | Données Masquées |
|---|---|---|
| Masquage de carte de crédit | 4111 1111 1111 1111 | 4111 **** **** 1111 |
| Masquage d’email | john.doe@example.com | j***e@e*****e.com |
| Masquage d’URL | https://www.example.com/user/profile | https://www.******.com/****/****** |
| Masquage de numéros de téléphone | +1 (555) 123-4567 | +1 (***) ***-4567 |
| Masquage aléatoire d’adresse IPv4 | 192.168.1.1 | 203.45.169.78 |
| Date aléatoire avec année constante pour les types de colonne chaîne | 2023-05-15 | 2023-11-28 |
| Date/Date-heure aléatoire et Heure à partir de l’intervalle pour le type de colonne chaîne | 2023-05-15 14:30:00 | 2024-02-19 09:45:32 |
| Masquage par valeur vide, NULL, sous-chaîne | Informations Sensibles | NULL |
| Masquage par valeurs fixes et aléatoires | John Doe | Utilisateur Anonyme 7392 |
| Masquage avec une fonction personnalisée | Secret123! | S****t1**! |
| Masquer les premiers et derniers caractères des chaînes | Motdepasse | *otdepass* |
| Masquage des données sensibles dans un texte brut | Mon SSN est 123-45-6789 et ma DDN est 01/15/1980 | Mon SSN est XXX-XX-XXXX et ma DDN est XX/XX/XXXX |
| Masquage par valeurs provenant de dictionnaires prédéfinis | John Smith, Ingénieur en Logiciel, New York | Ahmet Yılmaz, Analyste de Données, Chicago |
Étapes de Masquage de Données
Pour une mise en œuvre pratique, vous avez besoin de la meilleure stratégie qui fonctionne au sein de votre organisation. Voici les étapes à suivre pour rendre le masquage efficace :
- Trouvez vos données sensibles. La première étape consiste à récupérer et identifier les données qui peuvent être sensibles et nécessitent une protection. Il est préférable d’utiliser un outil logiciel spécial automatisé pour cela, comme la découverte de données sensibles de DataSunrise qui utilise les relations de table.
- Analysez la situation. À ce stade, l’équipe de sécurité des données doit comprendre où se trouvent les données sensibles, qui a besoin d’y accéder et qui n’en a pas besoin. Vous pouvez utiliser un accès basé sur les rôles. Toute personne ayant un certain rôle peut voir les données sensibles originales ou masquées.
- Appliquez le masquage. Il faut garder à l’esprit que dans de très grandes organisations, il n’est pas faisable de supposer qu’un seul outil de masquage peut être utilisé dans toute l’entreprise. Vous pourriez avoir besoin de différents types de masquage.
- Testez les résultats du masquage. C’est l’étape finale du processus. L’assurance qualité et les tests sont requis pour s’assurer que les configurations de masquage fournissent les résultats requis.
Types de Masquage de Données
Pour plus d’informations détaillées sur les types de masquage et leurs mises en œuvre en utilisant à la fois des solutions natives et tierces, veuillez visiter notre chaîne YouTube et explorer notre playlist de masquage complète.
Masquage Dynamique
Le Masquage Dynamique est un processus de masquage des données au moment où une requête de base de données contenant des données réelles est faite. Il est effectué en modifiant la requête ou la réponse. À ce stade, les données sont masquées à la volée, c’est-à-dire sans les enregistrer dans un stockage de données transitoire.
Masquage Statique
Comme son nom l’indique, lors du masquage statique des données, les administrateurs de bases de données doivent créer une copie des données originales et la conserver en lieu sûr et la remplacer par un ensemble de données fictives. Ce processus implique de dupliquer le contenu d’une base de données dans un environnement de test, que l’organisation peut ensuite partager avec des sous-traitants tiers et d’autres parties externes. Par conséquent, les données originales sensibles nécessitant une protection restent dans la base de données de production et une copie masquée est déplacée dans l’environnement de test. Aussi parfait que cela puisse sembler fonctionner avec des sous-traitants tiers utilisant le masquage statique, pour les applications nécessitant des données réelles des bases de données de production, les données masquées statiquement peuvent être un gros problème.
Masquage en Place
Le masquage en place comme le masquage statique crée également des données de test basées sur des données de production réelles. Ce processus se compose généralement de 3 étapes principales :
- Copier les données de production telles quelles dans une base de test.
- Supprimer les données de test redondantes pour diminuer le volume de stockage des données et accélérer les processus de test.
- Remplacer toutes les données PII dans une base de test par des valeurs masquées – cette étape est appelée masquage en place.
La façon de copier les données de production est hors du cadre du masquage en place. Par exemple, cela peut être une procédure ETL ou une sauvegarde-récupération d’une base de données de production ou autre chose. La chose la plus importante ici est que le masquage en place est appliqué à une copie d’une base de données de production pour masquer les données PII qu’elle contient.
Conditions au Masquage de Données
Comme mentionné précédemment, toutes les données impliquées dans le masquage doivent rester significatives à plusieurs niveaux :
- Les données doivent rester significatives et valides pour la logique de l’application.
- Les données doivent subir suffisamment de modifications pour qu’elles ne puissent pas être rétro-conçues.
- Les données obfusquées doivent rester cohérentes sur plusieurs bases de données au sein d’une organisation lorsque chaque base de données contient l’élément de données spécifique à masquer.
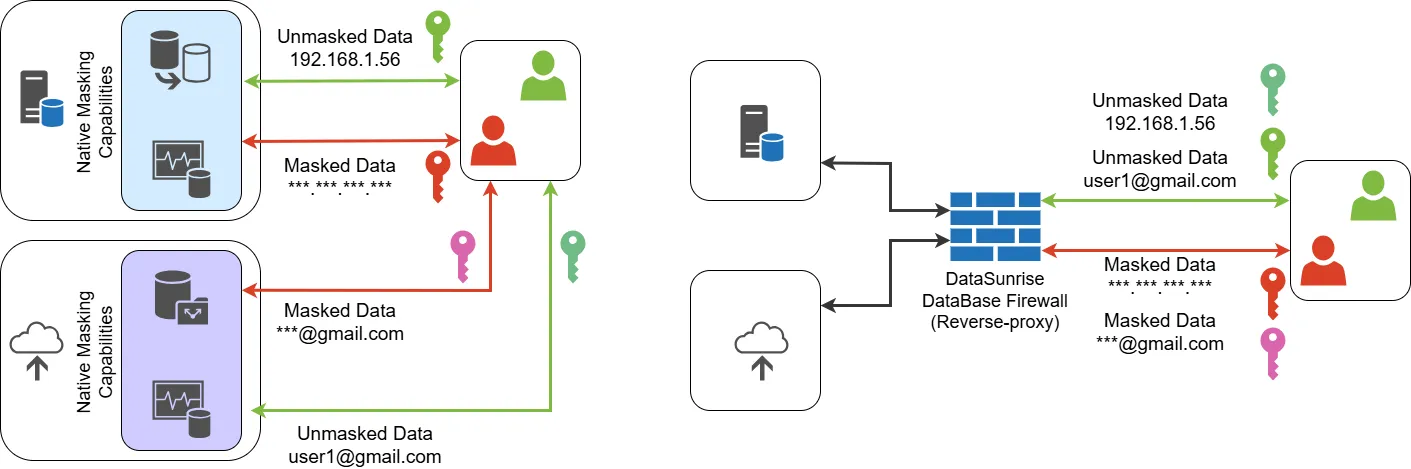
Masquage de Données avec DataSunrise
La capacité de masquage des données de DataSunrise se présente comme l’une des solutions les plus sophistiquées mais conviviales disponibles sur le marché d’aujourd’hui. Notre interface de masquage illustre ce parfait équilibre – imaginez configurer le masquage des champs d’e-mail en quelques clics. Avec des dizaines de types de masquage à votre disposition, le processus ne pourrait être plus simple : choisissez votre base de données, sélectionnez ce qui doit être masqué (que ce soit des données structurées ou non structurées), choisissez votre type de masquage préféré, et vous êtes prêt à partir. Vos données traverseront les contrôles de conformité réglementaire tout en maintenant une protection robuste.
La solution offre à la fois des capacités de masquage dynamiques et statiques, permettant aux organisations de protéger les données à la fois au repos et en mouvement. Ses algorithmes de masquage polyvalents prennent en charge divers types de données – du simple remplacement de texte au cryptage complexe préservant le format – garantissant que les informations sensibles restent protégées tout en maintenant l’intégrité référentielle et l’utilisabilité des données. Que les organisations aient besoin de masquer des informations personnellement identifiables (PII), des données financières ou des dossiers de santé, le moteur de masquage robuste de DataSunrise offre la flexibilité et la sécurité requises pour les défis de protection des données modernes tout en s’intégrant parfaitement à l’infrastructure de base de données existante.
Conclusion
DataSunrise vous offre la possibilité de masquer les données de manière statique et dynamique pour protéger vos données (y compris masquer XML, JSON, CSV et texte non structuré sur Amazon S3). De plus, la découverte de données avec les relations de table sera un outil supplémentaire indispensable à la protection de vos données. Notre suite de sécurité garantit la protection des données dans vos bases de données dans le Cloud et sur site. Essayez maintenant toutes nos capacités pour être sûr que tout est sous votre contrôle.
Suivant
