
Qu’est-ce que le partitionnement ?
Le partitionnement consiste à diviser des objets de base de données stockés (tables, index, vues) en parties distinctes. Le partitionnement est utilisé pour accroître la contrôlabilité, les performances et la disponibilité des gros objets de base de données.
- Dans certains cas, le partitionnement améliore les performances lors de l’accès aux tables partitionnées.
- Le partitionnement peut jouer le rôle de colonnes principales dans les index, ce qui réduit la taille de l’index et augmente la possibilité de trouver les index les plus recherchés en mémoire. Lorsqu’une grande partie d’une section est utilisée dans le jeu de résultats, le balayage de cette section peut être effectué beaucoup plus rapidement qu’un accès occasionnel aux données réparties dans toute la table par index.
- Le téléchargement et la suppression massifs de données peuvent être effectués en ajoutant et en supprimant des sections, ce qui permet d’augmenter les performances.
- Les données rarement utilisées peuvent être téléchargées sur des dispositifs de stockage de données moins coûteux.
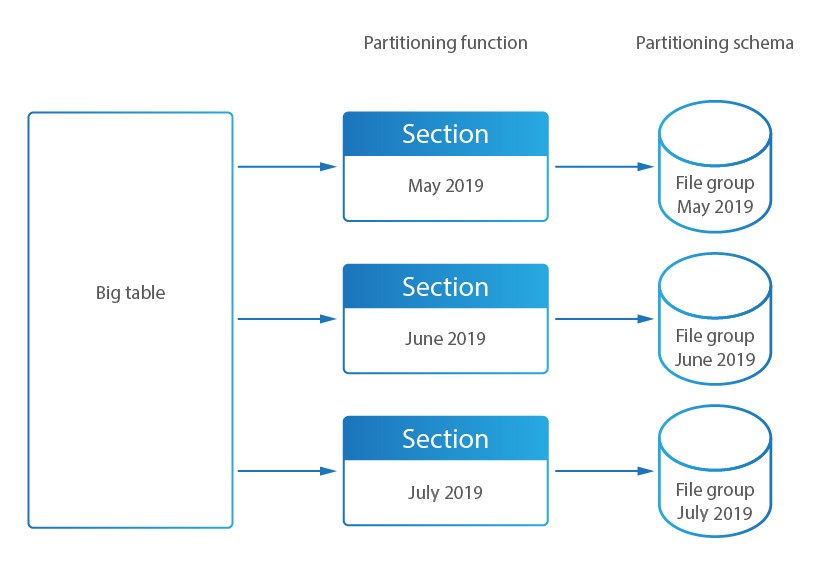
Dans DataSunrise, le partitionnement est utilisé pour diviser les tables de la base de données de stockage d’audit en sections (plus petites tables). Le stockage d’audit est une base de données utilisée pour stocker les résultats de la surveillance de l’activité de la base de données DataSunrise.
- Rend l’administration du stockage d’audit plus simple, car les données partitionnées sont distribuées par partitions en fonction du moment de partitionnement. L’administrateur de la base de données peut désactiver l’interrogation des partitions, les archiver, etc.
- Augmente les performances lors de l’accès, de la récupération des données et de l’écriture des données dans les tables partitionnées;
- Augmente les performances lors de la suppression des données obsolètes d’audit à partir du stockage d’audit;
DataSunrise prend en charge le partitionnement pour les types suivants de bases de données de stockage d’audit :
- PostgreSQL
- MySQL
- MS SQL Server
Paramètres de partitionnement
Peuvent être trouvés dans Paramètres du système -> Paramètres supplémentaires.
- Longueur des partitions (jours) – longueur de la partition, en jours (si AuditPartitionShort == 1, alors en minutes). Peut être trouvé dans Paramètres du système -> Stockage d’audit. Si Longueur des partitions est modifiée, toutes les partitions créées à l’avance seraient supprimées et de nouvelles partitions seraient créées avec les nouveaux paramètres de longueur de partition.
- AuditPartitionCountCreatedInAdvance – nombre de partitions créées à l’avance. Ainsi, des partitions vides créées pour être remplies à l’avenir. Cela permet à DataSunrise de rédiger des données dans des partitions existantes sans retard;
- AuditPartitionFirstEndDateTime – date/heure de la fin de la première partition. Cette fois est nécessaire pour ajuster les limites de partition autour de la valeur “ronde”. Par exemple : lundi 00:00:00 (pour une longueur de partition de 7 jours).
Gestion des partitions dans DataSunrise
DataSunrise comprend des mécanismes de gestion des partitions : DataSunrise crée des tables supplémentaires nécessaires au fonctionnement (pour PostgreSQL), crée et maintient à jour les fonctions de partitionnement, les schémas partitionnés, les groupes de fichiers et les index (pour MS SQL), modifie les clés et les index pour se conformer aux exigences de partitionnement (MySQL), active le partitionnement, crée et supprime des partitions.
Les SELECTs sont effectués via la table maître. Les INSERT/UPDATEs sont effectués directement à la partition (sauf pour MS SQL Server). Cela permet d’augmenter la vitesse d’écriture.
Noms des partitions et des tables
Les partitions pour PostgreSQL sont organisées comme des tables enfants nommées <table_name>_p<datetime>, où <table_name> est la table maître, <datetime> est le moment de la limite supérieure de la partition dans le format suivant : YYYYMMDDhhmm.
Pour MySQL, le partitionnement est implémenté en utilisant des mécanismes natifs. Les noms des partitions sont formés selon le schéma suivant : p<datetime>, où <datetime> est le moment de la limite supérieure de la partition dans le format suivant : YYYYMMDDhhmm.
Pour MS SQL Server, le partitionnement est implémenté via un schéma.
