
Che Cos’è un File CSV?
Introduzione: Il Modesto File CSV
Sapeva che i file CSV esistono dai primi giorni dell’informatica? Negli anni ’70 e all’inizio degli anni ’80, il linguaggio Fortran 77 di IBM ha introdotto il tipo di dato carattere, che ha abilitato il supporto per input e output separati da virgola. Questi file semplici ma potenti hanno superato la prova del tempo, rimanendo una scelta popolare per lo scambio di dati anche nel nostro mondo moderno alimentato dalla tecnologia. Esploriamo il mondo dei file separati da virgola e scopriamo perché continuano a essere un formato di riferimento per molti professionisti dei dati e utenti occasionali.
Abbiamo descritto in precedenza le capacità di DataSunrise per gestire dati semistrutturati in file JSON. Controlli quelle informazioni per saperne di più sulle funzionalità di sicurezza dei dati di DataSunrise.
Con DataSunrise Lei può mascherare e scoprire i dati sensibili nei file CSV memorizzati localmente o in archiviazione S3. Ecco l’esempio di mascheramento.
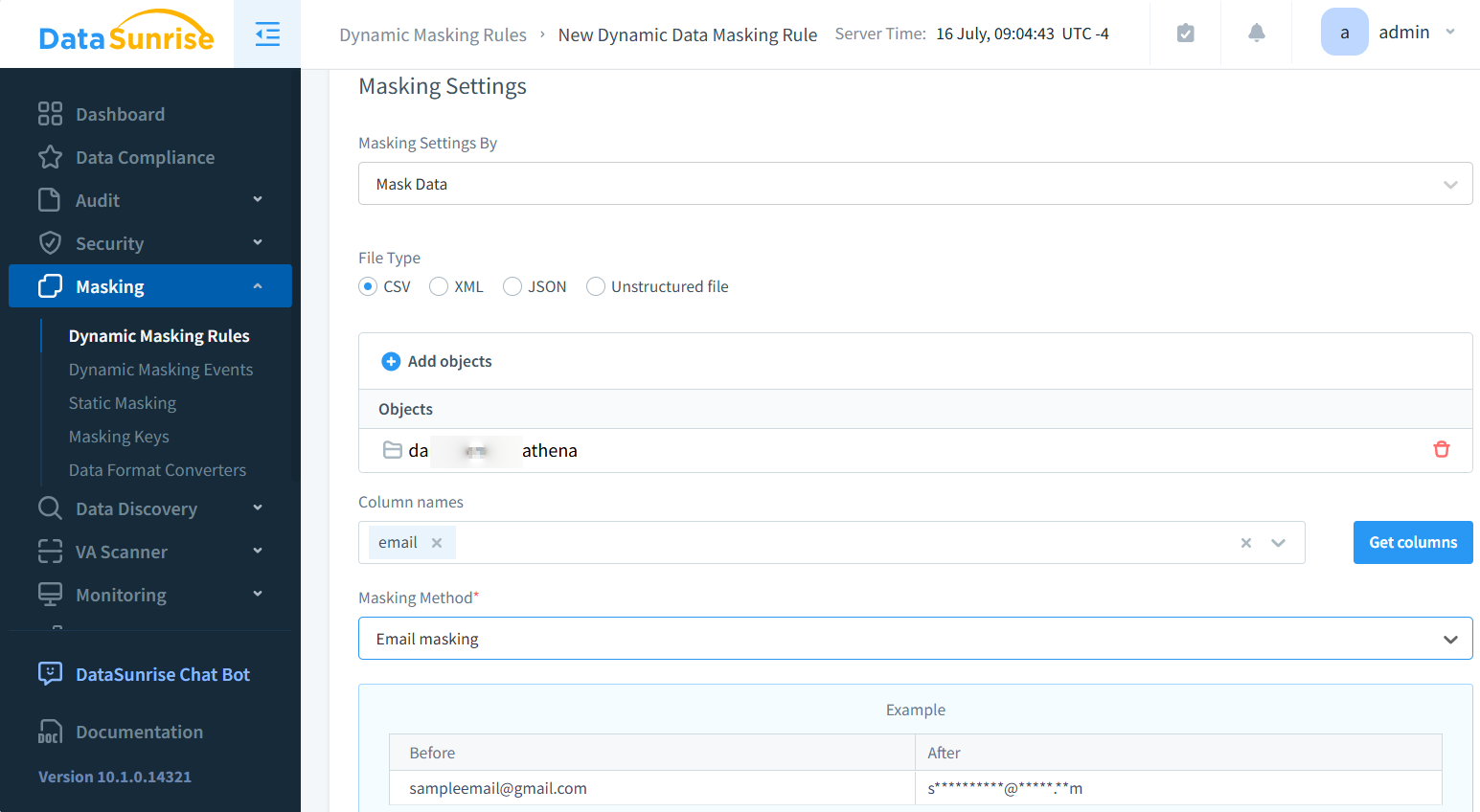
Dopo una configurazione semplice, può accedere (scaricare) ai file CSV mascherati tramite il proxy S3 di DataSunrise utilizzando software specializzati come S3Browser. È necessaria una configurazione adeguata delle impostazioni del proxy nel software client. Il risultato è il seguente:

Nella vasta gamma di formati di file, il CSV si distingue per la sua semplicità e versatilità. CSV, abbreviazione di Comma-Separated Values, è un tipo di file di testo semplice che memorizza dati tabulari. Ogni riga nel file rappresenta una riga di dati, con virgole che separano i valori individuali. Questa struttura semplice rende tali file facili da creare, leggere e manipolare su varie piattaforme e applicazioni.
Perché Usare i File CSV?
I file CSV offrono diversi vantaggi che contribuiscono al loro uso diffuso:
- Semplicità: Il formato è facile da comprendere e usare, anche per utenti non tecnici. Può aprirlo in Notepad o Notepad++ (qualsiasi editor di testo).
- Compatibilità: I file possono essere aperti e modificati da una vasta gamma di software, dalle applicazioni per fogli di calcolo agli editor di testo.
- Scambio di dati: Servono come formato universale per il trasferimento dei dati tra diversi sistemi e applicazioni.
- Efficienza dimensionale: I file sono generalmente più piccoli rispetto ai loro equivalenti binari, rendendoli ideali per memorizzare e trasmettere grandi set di dati.
Ecco una tabella comparativa dei formati di dati utilizzati nel Big Data e nel Machine Learning, evidenziando il ruolo dei file separati da virgola nell’elaborazione dei dati.
| Formato | Big Data | Machine Learning | Pro | Contro |
|---|---|---|---|---|
| CSV | Comune per lo scambio di dati, meno comune per l’archiviazione | Spesso usato per set di dati piccoli o medi | Semplice, leggibile per l’uomo, ampiamente supportato | Non efficiente per grandi dataset, nessuna applicazione dello schema |
| Parquet | Molto comune per l’archiviazione e l’elaborazione | Ottimo per grandi dataset e archivi delle feature | Archiviazione colonnare, compressione efficiente | Non leggibile per l’uomo, richiede strumenti speciali per visualizzare |
| Avro | Comune per la serializzazione dei dati | Meno comune, ma usato in alcune pipeline | Evoluzione dello schema, formato binario compatto | Più complesso del CSV, non così efficiente come Parquet per analitica |
| JSON | Comune per le API e negozi di documenti | Usato per memorizzare metadata e piccoli dataset | Flessibile, leggibile per l’uomo, ampiamente supportato | Meno efficiente nell’archiviazione dei formati binari |
| TFRecord | Non comunemente usato | Specifico per TensorFlow, comune nelle pipeline ML | Efficiente per grandi dataset, buono con TensorFlow | Non ampiamente supportato fuori dall’ecosistema TensorFlow |
Esempio di CSV
Osserviamo un semplice esempio di CSV per illustrare la sua struttura:
Nome, Età, Città John Doe, 30, New York Jane Smith, 25, London Bob Johnson, 35, Paris
Questo esempio mostra come i dati sono organizzati in un file CSV, con ogni riga che rappresenta un record e virgole che separano i valori.
Lavorare con File CSV in Python
Python fornisce strumenti integrati per gestire i file CSV, rendendolo una scelta popolare per le attività di elaborazione dei dati. Esploriamo come lavorare con i file CSV usando il core Python e la potente libreria pandas.
Usando Core Python
Il modulo csv di Python offre metodi semplici per la lettura e la scrittura di file CSV. Ecco un esempio di base:
import csv
# Lettura di un file
with open('data.csv', 'r') as file:
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
# Scrittura su un file
with open('output.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['Nome', 'Età', 'Città'])
csv_writer.writerow(['Alice', '28', 'Berlino'])Questo codice dimostra come leggere e scrivere file CSV usando il modulo csv integrato di Python.
Usando Pandas
Per una manipolazione dei dati più avanzata, la libreria pandas è un’ottima scelta. Fornisce strumenti potenti per lavorare con dati semi-strutturati, inclusi i file CSV:
import pandas as pd
# Lettura di un file
df = pd.read_csv('data.csv')
# Visualizzazione delle prime righe
print(df.head())
# Scrittura su un file
df.to_csv('output.csv', index=False)Pandas rende facile eseguire operazioni complesse sui dati CSV, come filtraggio, ordinamento e aggregazione. Puoi facilmente salvare nuovamente i dati in CSV in seguito.
I Pro e i Contro dei File Separati da Virgola
Sebbene i file CSV siano ampiamente utilizzati, è importante comprenderne i punti di forza e le limitazioni:
Vantaggi
- Leggibile per l’uomo: I file separati da virgola possono essere facilmente visualizzati e modificati negli editor di testo.
- Leggeri: Hanno dimensioni di file ridotte rispetto a molti altri formati.
- Ampio supporto: La maggior parte degli strumenti di elaborazione dei dati e dei linguaggi di programmazione possono lavorare con i file CSV.
Svantaggi
- Tipi di dati limitati: I file di testo non supportano in modo intrinseco tipi di dati o strutture complessi.
- Nessuna standardizzazione: Non esiste uno standard ufficiale per i file CSV, il che può portare a problemi di compatibilità. Non ci sono colonne richieste o delimitatori obbligatori.
- Integrità dei dati: I file separati da virgola non hanno meccanismi incorporati di controllo errori o validazione dei dati. I formati Big Data (come Parquet) includono checksum integrati per i blocchi di dati.
Formati Binari: Quando e Perché Sono Migliori
Sebbene i file CSV eccellano in molti scenari, i formati binari possono essere vantaggiosi in determinate situazioni:
- Performance: I formati binari sono spesso più veloci da leggere e scrivere, specialmente per grandi dataset.
- Tipi di dati: Possono preservare tipi di dati e strutture complesse più accuratamente.
- Compressione: I formati binari offrono tipicamente migliori rapporti di compressione, risparmiando spazio di archiviazione.
- Sicurezza: Alcuni formati binari forniscono opzioni per la crittografia e il controllo degli accessi.
Esempi di formati binari includono HDF5, Parquet e Avro. Questi formati sono particolarmente utili in ambienti di big data dove la performance e l’integrità dei dati sono cruciali.
I File CSV nello Scambio di Dati
I file CSV svolgono un ruolo vitale nello scambio di dati attraverso vari settori ed applicazioni:
- Business intelligence: Le aziende spesso usano file di testo per trasferire dati tra diversi strumenti di BI e database.
- Ricerca scientifica: I ricercatori frequentemente condividono set di dati in questo formato per un’analisi facile e collaborativa.
- Applicazioni web: Molti servizi web permettono agli utenti di esportare dati in formato separato da virgola per analisi offline o backup.
- Dati IoT e sensori: I file di testo separati da virgola sono comunemente usati per registrare e trasmettere dati da dispositivi IoT e sensori.
La semplicità e la natura universale dei file di testo li rendono una scelta ideale per questi scenari di scambio di dati.
Campo dei Big Data
I file Comma-Separated Values hanno un rapporto alquanto complesso con il Big Data. Lasci che Le spieghi:
- Popolarità in certi contesti:
- Il formato dei file separati da virgola è ancora ampiamente usato per lo scambio di dati e come formato intermedio negli ecosistemi Big Data.
- Viene spesso usato per importare dati nei sistemi Big Data o esportare risultati per ulteriori analisi.
- Limitazioni per i Big Data:
- I file CSV non si comprimono bene, il che può essere un problema quando si trattano set di dati molto grandi.
- Mancano di definizioni di schema incorporate, il che può portare a incoerenze nei dati nelle operazioni su larga scala.
- Il parsing di grandi file di testo può essere più lento rispetto ad alcuni formati binari.
- Alternative preferite:
- Per le operazioni di Big Data, formati come Parquet, Avro, o ORC sono spesso preferiti.
- Questi formati offrono migliore compressione, evoluzione dello schema, e velocità di elaborazione.
- Casistica dove i file separati da virgola sono ancora rilevanti:
- Ingestione dati: Molti sistemi accettano ancora valori separati da virgola come formato di input.
- Sistemi legacy: Alcuni sistemi più vecchi possono ancora affidarsi a questi file per lo scambio di dati.
- Set di dati semplici: Per set di dati più piccoli o meno complessi all’interno di un ecosistema Big Data, CSV potrebbe ancora essere usato.
- Approcci ibridi:
- Alcuni flussi di lavoro di Big Data potrebbero usare CSV per ingestione iniziale dei dati o output finale, mentre utilizzano formati più ottimizzati per i passaggi di elaborazione intermedi.
Conclusione: Il Valore Duraturo dei File CSV
I file CSV continuano a essere uno strumento prezioso nel toolkit del professionista dei dati. La loro semplicità, versatilità, e ampio supporto li rendono una scelta eccellente per molti scenari di scambio e archiviazione di dati. Sebbene i formati binari offrano vantaggi in certe situazioni, il modesto file di testo rimane una soluzione conveniente e facile per la condivisione rapida dei dati su piattaforme e applicazioni.
Come abbiamo esplorato, lavorare con file separati da virgola in Python è semplice, sia che Lei stia usando il core Python o librerie più avanzate come pandas. Questa accessibilità contribuisce alla popolarità continua dei file CSV nei compiti di analisi ed elaborazione dei dati.
Per coloro che trattano dati sensibili in file CSV o altri formati semi-strutturati, DataSunrise offre strumenti facili da usare e flessibili per la sicurezza del database. Le nostre soluzioni includono scoperta di dati basata su NLP, che può essere particolarmente utile quando si lavora con file separati da virgola contenenti potenzialmente informazioni sensibili. Per saperne di più su come DataSunrise può migliorare le Sue misure di sicurezza dei dati, visiti il nostro sito web per una demo online ed esplori le nostre soluzioni complete di sicurezza del database.
