
Come i Dati Self-Service Stanno Rivoluzionando il Processo Decisionale Aziendale

Che Cos’è il Self Service Data (SSD)?
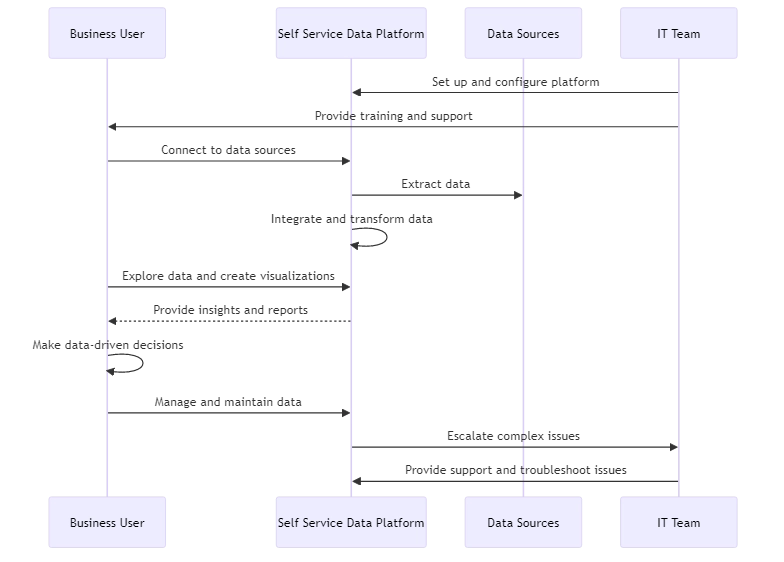
Nel veloce mondo aziendale moderno guidato dai dati, le organizzazioni necessitano di modi efficienti per sfruttare i loro asset dati. Il self service data consente agli utenti aziendali di accedere, analizzare e gestire i dati senza bisogno di assistenza dai team IT. SSD rende più facile per gli utenti accedere ai dati e prendere decisioni rapidamente.
SSD comprende due aree principali: analytics SSD e gestione SSD. Approfondiamo ciascuna di queste componenti.
Analisi dei Dati Self Service
Il self service data analytics consente agli utenti aziendali di esplorare i dati, creare visualizzazioni e derivare intuizioni in modo indipendente. Gli utenti possono utilizzare strumenti di BI e analytics intuitivi per interagire direttamente con i dati, senza dover attendere i report dagli analisti.
Alcuni vantaggi chiave dell’analytics SSD includono:
- Tempo di risposta più rapido: Gli utenti possono rispondere rapidamente a quesiti aziendali senza ritardi.
- Maggiore agilità: Le aziende possono rispondere più rapidamente alle condizioni di mercato e alle opportunità in evoluzione.
- Riduzione del carico sull’IT: Con gli utenti che si servono autonomamente, i team IT possono concentrarsi su iniziative più strategiche.
Ad esempio, consideriamo un analista di marketing che vuole valutare l’efficacia di una recente campagna email. Può facilmente ottenere informazioni, creare una dashboard con i principali numeri e condividere le idee con il proprio team senza bisogno dell’aiuto dell’IT.
Ecco uno script Python semplice che dimostra come connettersi a un database PostgreSQL e interrogare i dati della campagna email:
import psycopg2
conn = psycopg2.connect(
host="localhost",
database="marketing",
user="analyst",
password="password"
)
cur = conn.cursor()
cur.execute("""
SELECT
campaign_name,
SUM(num_delivered) AS total_delivered,
SUM(num_opened) AS total_opened,
SUM(num_clicked) AS total_clicked
FROM email_campaigns
WHERE campaign_date
BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY campaign_name;
""")
results = cur.fetchall()
for row in results:
campaign_name, total_delivered, total_opened, total_clicked = row
open_rate = total_opened / total_delivered * 100
click_rate = total_clicked / total_delivered * 100
print(f"{campaign_name}: Delivered={total_delivered}, Open Rate={open_rate:.2f}%,
Click Rate={click_rate:.2f}%")
cur.close()
conn.close()Questo script si connette a un database per il marketing. Analizza i dati della campagna email e mostra i numeri importanti per ogni campagna nel primo trimestre del 2023.
Gestione dei Dati Self Service
La self service analytics riguarda l’uso dei dati, mentre la gestione SSD riguarda la gestione e la manutenzione dei dati. Ciò include attività come l’integrazione dei dati, l’assicurazione della qualità e la governance.
Le piattaforme di gestione SSD hanno interfacce intuitive. Gli utenti possono connettere le fonti di dati, pulire e trasformare i dati, e impostare regole aziendali con facilità. Questo permette agli esperti di dominio di prendere responsabilità delle attività di gestione dei dati senza competenze tecniche approfondite.
I vantaggi della gestione SSD includono:
- Miglior qualità dei dati: I data steward possono applicare la loro conoscenza aziendale per garantire che i dati siano accurati e adatti allo scopo.
- Aumento dell’efficienza: Automatizzare le attività di gestione dei dati tramite strumenti self service risparmia tempo e risorse.
- Migliore governance: Gli utenti operano all’interno di confini definiti, garantendo la conformità alle politiche sui dati.
Immagina un direttore delle operazioni di vendita che necessita di integrare i dati di Salesforce con il sistema ERP dell’azienda. Può facilmente mappare i dati, definire le regole per le modifiche e programmare aggiornamenti automatici utilizzando uno strumento di dati self service.
Tuttavia, alcune attività di gestione dei dati possono ancora richiedere codice. Ecco un esempio di utilizzo di Python e della libreria Pandas per pulire e trasformare un file CSV:
import pandas as pd
df = pd.read_csv('salesforce_data.csv')
# Rimuovi le righe con valori mancanti
df = df.dropna()
# Rinomina le colonne per adattarli al sistema ERP
df = df.rename(columns={
'Account': 'CustomerID',
'Industry': 'Vertical',
'AnnualRevenue': 'Revenue'
})
# Converti il fatturato in tipo numerico
df['Revenue'] = pd.to_numeric(df['Revenue'], errors='coerce')
# Filtra per clienti attivi
df = df[df['Status'] == 'Active']
# Salva i dati puliti in un nuovo file
df.to_csv('salesforce_data_cleaned.csv', index=False)Questo script pulisce un file esportato da Salesforce rimuovendo valori vuoti, rinominando colonne, cambiando formati dei dati e organizzando le righe. Il sistema salva i dati puliti in un nuovo file per un facile caricamento nel sistema ERP.
Tecnologie Abilitanti Chiave
Diverse tecnologie si sono unite per rendere SSD una realtà:
- Cloud computing: I data warehouse cloud e le piattaforme di analisi forniscono risorse scalabili e on-demand per archiviare e processare dati. Gli utenti possono avviare nuovi progetti rapidamente senza dover configurare l’infrastruttura.
- Basi di dati NoSQL: I database flessibili e senza schema possono ingerire facilmente vari tipi di dati. Questo consente agli utenti di lavorare con dati semi-strutturati e non strutturati comuni negli scenari self service.
- Visualizzazione dei dati: Gli strumenti BI moderni offrono interfacce drag-and-drop per esplorare dati e creare dashboard interattive. Funzionalità avanzate come l’interrogazione in linguaggio naturale rendono l’analisi ancora più accessibile agli utenti aziendali.
- IA e Machine Learning: Gli algoritmi intelligenti possono automatizzare attività complesse di gestione dei dati e far emergere intuizioni nascoste. Funzionalità come la data discovery intelligente e la preparazione automatizzata dei dati ottimizzano i flussi di lavoro self service.
Implementare il Self Service Data
Nonostante le promesse allettanti del SSD, implementarlo con successo richiede una pianificazione e esecuzione attenta. Alcune considerazioni chiave includono:
- Definire ruoli e responsabilità chiari: Stabilire chiaramente quali attività possono essere eseguite autonomamente dagli utenti aziendali e quali rimangono gestite dall’IT.
- Fornire formazione e supporto: Assicurarsi che gli utenti aziendali siano competenti con gli strumenti self service e comprendano le migliori pratiche di gestione dei dati. Offrire risorse per la formazione continua e il supporto.
- Garantire sicurezza dei dati e conformità: Implementare rigorosi controlli di accesso e politiche di governance per mitigare i rischi. Auditare regolarmente l’attività degli utenti e le autorizzazioni.
- Iniziare in piccolo e iterare: Iniziare con un esempio specifico per dimostrare i vantaggi prima di rendere le opzioni self-service disponibili a tutti. Raccogliere feedback e raffinare continuamente i processi.
Esempi Reali
Molte organizzazioni hanno adottato con successo approcci SSD. Ecco alcuni esempi:
- Procter & Gamble utilizza l’analisi self service per mettere i dati nelle mani di oltre 50.000 dipendenti a livello globale. Gli utenti aziendali possono ottenere risposte in pochi minuti anziché attendere settimane per i report.
- Comcast ha oltre 2.000 utenti che interagiscono regolarmente con la sua piattaforma BI self service. L’azienda ha registrato una riduzione del 25% dei costi BI e una riduzione del 50% nel tempo di creazione dei report.
- Hertz utilizza una piattaforma di gestione SSD per integrare oltre 100 fonti di dati. Gli utenti aziendali possono integrare nuovi set di dati in poche ore anziché in mesi. La qualità dei dati è migliorata significativamente.
Conclusione
I dati self-service stanno trasformando il modo in cui le organizzazioni sfruttano i loro asset dati. Fornendo agli utenti aziendali strumenti intuitivi per l’analisi e la gestione dei dati, le aziende possono accelerare le intuizioni, aumentare l’agilità e ottenere risultati aziendali migliori.
Sebbene l’implementazione del SSD richieda una gestione del cambiamento attenta, i benefici sono chiari. Man mano che i dati continuano a crescere e le aziende accelerano, i dati self-service diventeranno sempre più critici. Le organizzazioni che abbracceranno questo cambiamento saranno ben posizionate per competere in un mondo sempre più centrato sui dati.
