
Dati Spazzatura

Nell’odierno mondo guidato dai dati, la qualità delle informazioni gioca un ruolo cruciale nei processi decisionali. Tuttavia, le organizzazioni spesso si trovano ad affrontare la sfida dei dati spazzatura perché non tutti i dati sono sufficientemente buoni. Questo articolo esamina tali processi di elaborazione dei dati e come influenzano i data set. Offriamo anche soluzioni per mantenere l’accuratezza dei dati.
Che Cos’è il Dato Spazzatura?
I dati spazzatura si riferiscono a informazioni che sono inaccurate, incomplete, irrilevanti o corrotte all’interno di un dataset. Possono anche contenere errori umani. Questi dati assumono varie forme, come:
- Voci duplicate
- Informazioni obsolete
- Errori di formattazione
- Registrazioni incomplete
- Punti dati irrilevanti
Questi dati possono rendere l’analisi dei dati meno efficace e portare a intuizioni errate se non corretti.
L’Impatto dei Dati Spazzatura sull’Analisi dei Dati
I dati spazzatura possono avere conseguenze di vasta portata sul processo di analisi dei dati. Ecco alcuni modi chiave in cui influenzano l’integrità e l’utilità dei tuoi dati:
1. Risultati Distorti
Quando dati fuorvianti sono presenti in un dataset, possono portare a calcoli statistici inaccurati e tendenze mal rappresentate. Questa distorsione dei risultati può causare alle organizzazioni di prendere decisioni errate basate su informazioni fallaci.
2. Ridotta Efficienza
Elaborare e analizzare i dati consuma tempo e risorse preziosi. Gli analisti dei dati possono passare ore a pulire e ordinare informazioni irrilevanti, riducendo la produttività complessiva.
3. Costi Aumentati
La presenza di dati duplicati spesso richiede spazio di archiviazione e potenza di elaborazione aggiuntivi. Questo può portare a costi infrastrutturali aumentati per le organizzazioni che gestiscono grandi volumi di dati.
4. Perdita di Credibilità
Le intuizioni derivate da dati errati possono erodere la fiducia nei processi decisionali di un’organizzazione. Questa perdita di credibilità può avere effetti duraturi sia sulle operazioni interne che sulle relazioni esterne.
Approcci di Classificazione dei Dati Utilizzando Strumenti Open-Source
Per gestire efficacemente i dati spazzatura, le organizzazioni possono implementare vari approcci di classificazione dei dati. Ecco alcuni strumenti open-source che possono aiutare in questo processo:
1. Apache NiFi
Apache NiFi è uno strumento potente per l’integrazione e l’elaborazione dei dati che può aiutare a classificare e instradare i dati in base a regole predefinite. Offre un’interfaccia user-friendly per creare flussi di dati e applicare filtri per identificare e segregare i dati spazzatura.
Esempio:
Apache NiFi Data Classification Flow
- Crea un nuovo gruppo di processi
- Aggiungi un processore GetFile per ingerire i dati
- Connettiti a un processore RouteOnAttribute
- Definisci le regole per classificare i dati (es. ${filename:contains(‘junk’)})
- Instrada i dati classificati verso le destinazioni appropriate
Risultato: Questo setup classificherà automaticamente i file in entrata in base ai loro attributi e li instraderà di conseguenza. Aiuta a isolare i potenziali dati cattivi per ulteriori elaborazioni o rimozioni.
2. OpenRefine
OpenRefine (precedentemente Google Refine) è uno strumento versatile per pulire e trasformare i dati disordinati. Fornisce funzionalità per rilevare e rimuovere voci duplicate, standardizzare formati e raggruppare punti dati simili.
Esempio:
OpenRefine Duplicate Detection
- Carica il tuo dataset in OpenRefine
- Seleziona la colonna contenente potenziali duplicati
- Scegli “Facets” > “Customized facets” > “Duplicates facet”
- Rivedi e unisci o rimuovi le voci duplicate
Risultato: Questo processo identificherà i record duplicati nel tuo dataset, permettendoti di pulire le informazioni ridondanti.
3. Talend Open Studio
Talend Open Studio (ritirato) è una piattaforma di integrazione dati open-source che include potenti strumenti di qualità e profilazione dei dati. Può aiutare a identificare modelli e anomalie nei tuoi dati.
Esempio:
Analisi della Qualità dei Dati con Talend
- Crea un nuovo job in Talend Open Studio
- Trascina e rilascia un componente tFileInputDelimited per leggere i tuoi dati
- Connettiti a un componente tDataProfiler
- Configura il profiler per analizzare colonne specifiche
- Esegui il job e rivedi il report sulla qualità dei dati
Risultato: Questo job genererà un report completo sulla qualità dei tuoi dati, evidenziando potenziali problemi di dati spazzatura come valori mancanti, outliers e inconsistenze di formato.
Evitare la Rimozione o l’Uso Improprio di Dati Sensibili
Mentre si elaborano i dati cattivi, è cruciale assicurarsi che le informazioni sensibili non vengano rimosse o utilizzate in modo improprio. Ecco alcune best practices da seguire:
1. Implementare il Mascheramento dei Dati
Utilizza tecniche di mascheramento dei dati per oscurare le informazioni sensibili mantenendo intatta la struttura generale dei dati. Questo permette di effettuare analisi senza esporre dettagli confidenziali.
2. Stabilire Controlli di Accesso
Implementa controlli di accesso rigidi per assicurare che solo il personale autorizzato possa visualizzare e manipolare i dati sensibili durante la fase di elaborazione dei dati spazzatura.
3. Mantenere le Tracce di Audit
Tieni log dettagliati di tutte le attività di elaborazione dei dati, inclusi chi ha accesso ai dati, quali cambiamenti sono stati fatti e quando. Questo aiuta a tracciare eventuali usi impropri o rimozioni accidentali di informazioni importanti.
4. Utilizzare Tag di Classificazione dei Dati
Applica tag di classificazione ai tuoi dati, marcando chiaramente le informazioni sensibili. Questo aiuta a identificare quali dati richiedono una gestione speciale durante il processo di rimozione dei dati spazzatura.
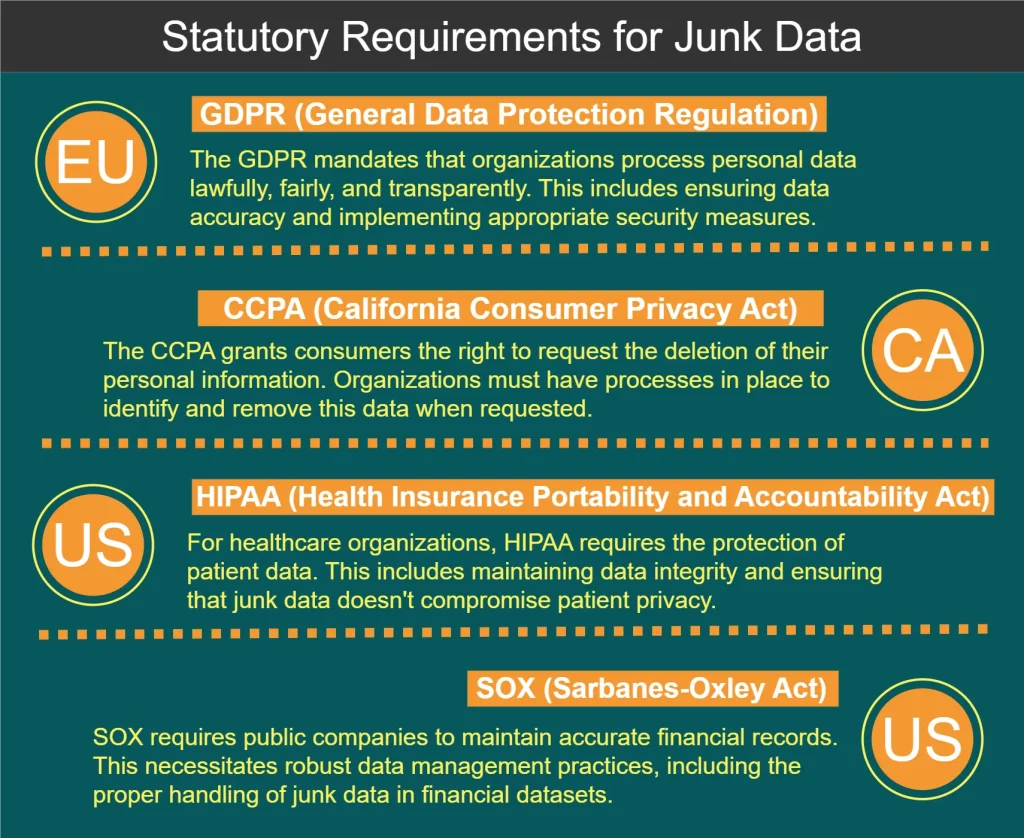
Requisiti di Legge per l’Elaborazione dei Dati Spazzatura
Diverse regolamentazioni e standard governano la gestione dei dati, inclusa l’elaborazione dei dati spazzatura. Alcuni requisiti chiave sono mostrati nel diagramma qui sotto:
Migliori Pratiche per l’Elaborazione dei Dati Spazzatura
Per gestire efficacemente i dati e mantenere l’integrità dei dati, considera le seguenti migliori pratiche:
- Implementa la validazione dei dati al momento dell’inserimento per prevenire l’ingresso di dati spazzatura nei tuoi sistemi.
- Audita regolarmente i tuoi dataset per identificare e affrontare i problemi di qualità dei dati.
- Sviluppa una politica completa di governance dei dati che includa linee guida per la gestione dei dati spazzatura.
- Investi nella formazione del personale per assicurarti che tutti i membri del team comprendano l’importanza della qualità dei dati.
- Usa strumenti automatizzati per semplificare il processo di identificazione e rimozione dei dati spazzatura.
- Implementa un sistema di valutazione della qualità dei dati per monitorare i miglioramenti nel tempo.
- Stabilisci un feedback loop con gli utenti dei dati per identificare rapidamente e risolvere i problemi di qualità dei dati.
Alla fine di questo articolo, menzioniamo anche come implementare semplici metodi di rilevamento dei dati spazzatura in Python.
Analizzare i Dati e Identificare i Dati Spazzatura Usando Python
Python è diventato un linguaggio di riferimento per l’analisi dei dati grazie alla sua semplicità, versatilità e robusto ecosistema di librerie centrate sui dati. Ecco alcuni modi per analizzare i dati e identificare i dati spazzatura usando Python:
1. Pandas per la Manipolazione e l’Analisi dei Dati
Pandas è una potente libreria per la manipolazione e l’analisi dei dati in Python. Fornisce strutture di dati come DataFrames che rendono facile lavorare con dati strutturati.
Esempio: Identificare valori mancanti e duplicati
import pandas as pd
# Load data into a DataFrame
df = pd.read_csv('your_data.csv')
# Check for missing values
missing_values = df.isnull().sum()
# Identify duplicate rows
duplicates = df.duplicated().sum()
print("Missing values:\n", missing_values)
print("Number of duplicate rows:", duplicates)Risultato: Questo script restituirà il conteggio dei valori mancanti per ciascuna colonna e il numero totale delle righe duplicate nel tuo dataset, aiutandoti a identificare i potenziali dati spazzatura.
2. Matplotlib e Seaborn per la Visualizzazione dei Dati
Visualizzare i tuoi dati può aiutare a identificare outliers e schemi insoliti che potrebbero indicare dati spazzatura.
Esempio: Creare un box plot per individuare outliers
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load data
df = pd.read_csv('your_data.csv')
# Create a box plot
plt.figure(figsize=(10, 6))
sns.boxplot(x='category', y='value', data=df)
plt.title('Distribution of Values by Category')
plt.show()Risultato: Questo genererà un box plot che rappresenta visivamente la distribuzione dei valori attraverso diverse categorie, rendendo facile individuare outliers che potrebbero essere dati spazzatura.
3. Scikit-learn per il Rilevamento delle Anomalie
Scikit-learn offre algoritmi di machine learning che possono essere usati per il rilevamento delle anomalie, aiutando a identificare punti dati insoliti che potrebbero essere spazzatura.
Esempio: Utilizzare Isolation Forest per il rilevamento delle anomalie
import pandas as pd
from sklearn.ensemble import IsolationForest
# Load and prepare data
df = pd.read_csv('your_data.csv')
X = df[['feature1', 'feature2']] # Select relevant features
# Create and fit the model
iso_forest = IsolationForest(contamination=0.1, random_state=42)
outliers = iso_forest.fit_predict(X)
# Add results to the DataFrame
df['is_outlier'] = outliers
# View potential junk data (outliers)
junk_data = df[df['is_outlier'] == -1]
print(junk_data)Risultato: Questo script utilizzerà l’algoritmo Isolation Forest per identificare potenziali outliers nel tuo dataset, che potrebbero indicare dati spazzatura.
4. Funzioni Custom per i Controlli di Qualità dei Dati
Puoi creare funzioni Python personalizzate per eseguire controlli di qualità dei dati specifici per il tuo dataset.
Esempio: Controllare valori irrealistici in un dataset di temperature
import pandas as pd
def check_temperature_range(df, column, min_temp, max_temp):
"""Check if temperature values are within a realistic range."""
outliers = df[(df[column] < min_temp) | (df[column] > max_temp)]
return outliers
# Load data
df = pd.read_csv('temperature_data.csv')
# Check for unrealistic temperatures (e.g., below -100°C or above 60°C)
junk_temps = check_temperature_range(df, 'temperature', -100, 60)
print("Potentially junk temperature readings:")
print(junk_temps)Risultato: Questa funzione identificherà le letture della temperatura che cadono al di fuori di un intervallo realistico specificato, aiutando a individuare potenziali dati errati o spazzatura.
5. Profiling dei Dati con ydata-profiling
La libreria ydata-profiling (precedentemente pandas-profiling) fornisce un modo facile per generare report comprensivi sui tuoi dati, inclusi potenziali problemi di qualità.
Esempio: Generare un report di profilazione dei dati
import pandas as pd
from ydata_profiling import ProfileReport
# Load data
df = pd.read_csv('your_data.csv')
# Generate report
profile = ProfileReport(df, title="Data Profiling Report", explorative=True)
# Save report to file
profile.to_file("data_profile_report.html")Risultato: Questo script genererà un report HTML con statistiche dettagliate, visualizzazioni e potenziali problemi di qualità nel tuo dataset, fornendo una panoramica completa che può aiutare a identificare i dati spazzatura.
Incorporando queste tecniche basate su Python nel tuo flusso di lavoro di analisi dei dati, puoi identificare e affrontare in modo più efficace i problemi di dati spazzatura, migliorando la qualità e l’affidabilità complessiva dei tuoi dataset.
Conclusione: Il Percorso verso una Migliore Integrità dei Dati
L’elaborazione dei dati spazzatura è un aspetto critico per mantenere l’integrità dei dati e garantire l’affidabilità dei tuoi sforzi di analisi dei dati. Utilizzando metodi di classificazione forti, strumenti gratuiti e seguendo le regole, le organizzazioni possono migliorare notevolmente la qualità dei loro dati.
Ricorda che la pulizia dei dati è uno sforzo continuo che richiede vigilanza costante e adattamento agli scenari in evoluzione. Prioritizzando la qualità dei dati e implementando strategie efficaci di elaborazione dei dati fuorvianti, le organizzazioni possono sbloccare il vero potenziale dei loro dati e prendere decisioni più informate.
Per strumenti user-friendly e flessibili progettati per migliorare la sicurezza dei dati e garantire la conformità, considera di esplorare le offerte di DataSunrise. Visita il nostro sito web su DataSunrise.com per una demo online e scopri come possiamo aiutarti a mantenere l’integrità dei
