
AI Data Generator

Poiché gli approfondimenti basati sui dati sono diventati cruciali per le aziende di tutte le dimensioni, la domanda di dataset di alta qualità e diversificati è aumentata enormemente. Tuttavia, ottenere dati reali può essere difficile, dispendioso in termini di tempo e spesso solleva preoccupazioni sulla privacy. È qui che entra in gioco l’AI data generator, offrendo una potente soluzione attraverso la generazione di dati sintetici. Esploriamo questo affascinante mondo e scopriamo come l’AI sta trasformando il panorama della creazione di dati.
Dato che DataSunrise implementa le proprie capacità di generazione di dati sintetici ricche di funzionalità e di facile utilizzo, approfondiremo questo argomento, esplorando specificamente gli strumenti open-source oggi disponibili.
Comprendere i Dati Sintetici
I dati sintetici sono informazioni create artificialmente che imitano le caratteristiche e le proprietà statistiche dei dati reali. Vengono generati utilizzando vari algoritmi e tecniche AI, senza copiare direttamente i punti dati reali. Questo approccio offre numerosi vantaggi, particolarmente in scenari in cui i dati reali sono scarsi, sensibili o difficili da ottenere.
La Necessità di Dati Sintetici
Superare la Scarsità di Dati
Uno dei principali motivi per utilizzare dati sintetici è superare la carenza di dati reali. In molti campi, specialmente nelle tecnologie emergenti, raccogliere dati sufficienti per addestrare modelli di machine learning può essere difficile. I generatori di dati AI possono produrre enormi quantità di dati diversificati, aiutando a colmare questo divario.
Proteggere Privacy e Sicurezza
Con l’aumento delle preoccupazioni riguardo alla privacy dei dati e alla sicurezza, i dati sintetici offrono un’alternativa sicura. Permettono alle organizzazioni di lavorare con dati che assomigliano da vicino a informazioni reali senza rischiare l’esposizione di dati personali o aziendali sensibili. Questo è particolarmente cruciale in settori come la sanità e la finanza, dove la protezione dei dati è fondamentale.
Migliorare l’Addestramento dei Modelli
I dati sintetici possono essere usati per aumentare i dataset esistenti, migliorando le prestazioni e la robustezza dei modelli di machine learning. Generando ulteriori esempi diversificati, i modelli AI possono apprendere a gestire un’ampia gamma di scenari, portando a una migliore generalizzazione.
Tipologie di Dati Sintetici
I generatori di dati AI possono produrre vari tipi di dati sintetici:
1. Dati Numerici
Questi includono valori continui come misurazioni, dati finanziari o letture di sensori. I generatori AI possono creare dati numerici con specifiche proprietà statistiche, come:
- Distribuzione di densità di probabilità
- Media
- Varianza
- Correlazione tra variabili
2. Dati Categoriali
I dati categoriali rappresentano categorie o etichette discrete. I generatori AI possono creare dati categoriali sintetici mantenendo la distribuzione e le relazioni presenti nei dataset del mondo reale.
3. Dati Testuali
Da semplici frasi a documenti complessi, l’AI può generare dati testuali sintetici. Questo è particolarmente utile per compiti di elaborazione del linguaggio naturale e generazione di contenuti.
4. Dati Immagine
Le immagini generate dall’AI stanno diventando sempre più sofisticate. Queste possono variare da semplici forme geometriche a immagini fotorealistiche, utili per applicazioni di visione artificiale.
Meccanismi per la Generazione di Dati Sintetici
Diverse metodologie e tecniche vengono utilizzate nella generazione di dati AI:
Modellazione Statistica
Questo approccio coinvolge la creazione di modelli matematici che catturano le proprietà statistiche dei dati reali. I dati sintetici vengono quindi generati per abbinare queste proprietà.
Generazione Basata su Machine Learning
Tecniche avanzate di machine learning, in particolare modelli generativi, vengono utilizzate per creare dati sintetici altamente realistici. Alcuni metodi popolari includono:
- Reti Generative Avversarie (GANs): Coinvolgono due reti neurali che competono tra loro, una generando dati sintetici e l’altra cercando di distinguerli dai dati reali.
- Variational Autoencoders (VAEs): Questi modelli imparano a codificare i dati in una rappresentazione compressa e quindi a decodificarla, generando nuovi campioni di dati nel processo.
- Modelli Trasformatori: Particolarmente efficaci per la generazione di testi, questi modelli hanno rivoluzionato i compiti di elaborazione del linguaggio naturale.
Generazione Basata su Regole
Questo metodo coinvolge la creazione di dati sintetici basati su regole e vincoli predefiniti. È spesso utilizzato quando i dati devono seguire specifici schemi o logiche aziendali.
Strumenti AI nella Generazione di Dati di Test
L’AI svolge un ruolo cruciale nella generazione di dati di test per lo sviluppo software e il controllo qualità. Questi strumenti possono creare dataset realistici e diversificati che coprono vari scenari di test, aiutando a scoprire potenziali problemi e casi limite.
Ad esempio, un generatore di dati di test basato su AI per un’applicazione e-commerce potrebbe creare:
- Profili utente con diversi dati demografici
- Cataloghi di prodotti con attributi diversi
- Storici di ordini con modelli diversificati
Questi dati di test sintetici possono aiutare sviluppatori e team QA a garantire la robustezza e l’affidabilità delle loro applicazioni senza utilizzare dati reali dei clienti.
L’AI Generativa nella Creazione di Dati
L’AI generativa rappresenta l’ultima frontiera della creazione di dati sintetici. Questi modelli possono produrre dataset altamente realistici e diversificati attraverso vari domini. Alcune applicazioni chiave includono:
- Sintesi di immagini per l’addestramento sulla visione artificiale
- Generazione di testi per l’elaborazione del linguaggio naturale
- Sintesi vocale e audio per applicazioni audio
- Generazione di dati di serie temporali per modelli predittivi
Ad esempio, un modello AI generativo addestrato su immagini mediche potrebbe creare radiografie o scansioni MRI sintetiche, aiutando i ricercatori a sviluppare nuovi algoritmi diagnostici senza compromettere la privacy dei pazienti.
Strumenti e Librerie per la Generazione di Dati Sintetici
Sono disponibili diversi strumenti e librerie per la generazione di dati sintetici. Un’opzione popolare è la libreria Python Faker. A differenza di strumenti più complessi, non si basa su machine learning o tecniche AI correlate. Faker utilizza invece approcci classici e robusti per la generazione di dati.
Libreria Python Faker
Faker è un pacchetto Python che genera dati falsi per vari scopi. È particolarmente utile per creare dati di test dall’aspetto realistico.
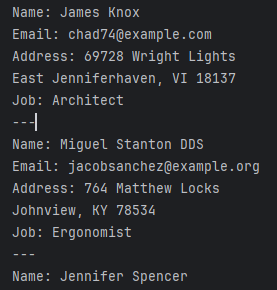
Ecco un semplice esempio di utilizzo di Faker per generare dati utente sintetici:
from faker import Faker
fake = Faker()
# Genera 5 profili utente falsi
for _ in range(5):
print(f"Name: {fake.name()}")
print(f"Email: {fake.email()}")
print(f"Address: {fake.address()}")
print(f"Job: {fake.job()}")
print("---")Questo script potrebbe produrre un output come:
Libreria CTGAN
CTGAN è una libreria Python specificamente progettata per la generazione di dati tabulari sintetici utilizzando Reti Generative Avversarie (GANs). Fa parte del progetto Synthetic Data Vault (SDV) ed è adatta per creare versioni sintetiche di dataset strutturati. CTGAN funziona molto più come un generatore di dati AI rispetto a Faker.
Ecco come è possibile utilizzare CTGAN in Python:
Ecco un esempio di base su come utilizzare CTGAN (al momento Readme suggerisce di installare la libreria SDV che fornisce API user-friendly per accedere a CTGAN.):
import pandas as pd
from ctgan import CTGAN
import numpy as np
# Crea un dataset di esempio
data = pd.DataFrame({
'age': np.random.randint(18, 90, 1000),
'income': np.random.randint(20000, 200000, 1000),
'education': np.random.choice(['High School', 'Bachelor', 'Master', 'PhD'], 1000),
'employed': np.random.choice(['Yes', 'No'], 1000)
})
print("Original Data Sample:")
print(data.head())
print("\nOriginal Data Info:")
print(data.describe())
# Inizializza e addestra il modello CTGAN
ctgan = CTGAN(epochs=10) # Utilizzando meno epoch per questo esempio
ctgan.fit(data, discrete_columns=['education', 'employed'])
# Genera campioni sintetici
synthetic_data = ctgan.sample(1000)
print("\nSynthetic Data Sample:")
print(synthetic_data.head())
print("\nSynthetic Data Info:")
print(synthetic_data.describe())
# Confronta le distribuzioni
print("\nOriginal vs Synthetic Data Distributions:")
for column in data.columns:
if data[column].dtype == 'object':
print(f"\n{column} distribution:")
print("Original:")
print(data[column].value_counts(normalize=True))
print("Synthetic:")
print(synthetic_data[column].value_counts(normalize=True))
else:
print(f"\n{column} mean and std:")
print(f"Original: mean = {data[column].mean():.2f}, std = {data[column].std():.2f}")
print(f"Synthetic: mean = {synthetic_data[column].mean():.2f}, std = {synthetic_data[column].std():.2f}")Il codice produce un output simile (notare la differenza nei parametri statistici):
Original Data Sample: age income education employed 0 57 25950 Master No 1 78 45752 High School No … Original Data Info: age income count 1000.00000 1000.000000 mean 53.75300 109588.821000 std 21.27013 50957.809301 min 18.00000 20187.000000 25% 35.00000 66175.250000 50% 54.00000 111031.000000 75% 73.00000 152251.500000 max 89.00000 199836.000000 Synthetic Data Sample: age income education employed 0 94 78302 Bachelor Yes 1 31 174108 Bachelor No … Synthetic Data Info: age income count 1000.000000 1000.000000 mean 70.618000 117945.021000 std 18.906018 55754.598894 min 15.000000 -5471.000000 25% 57.000000 73448.000000 50% 74.000000 112547.500000 75% 86.000000 163881.250000 max 102.000000 241895.000000
In questo esempio:
- Importiamo le librerie necessarie.
- Carichiamo i dati reali in un DataFrame pandas.
- Inizializziamo il modello CTGAN.
- Adattiamo il modello ai dati, specificando quali colonne sono discrete.
- Generiamo campioni sintetici utilizzando il modello addestrato.
CTGAN è particolarmente utile quando è necessario generare dati sintetici che mantengono complesse relazioni e distribuzioni presenti nel dataset originale. È più avanzato di metodi di campionamento casuale semplici come quelli utilizzati in Faker.
Alcune caratteristiche chiave di CTGAN includono:
- Gestire colonne sia numeriche che categoriali
- Preservare le correlazioni tra colonne
- Gestire distribuzioni multimodali
- Campionamento condizionato in base a valori di colonne specifiche
Altri Strumenti Notabili
- SDV (Synthetic Data Vault): Una libreria Python per generare dati sintetici relazionali su più tabelle.
- Gretel.ai: Una piattaforma che offre varie tecniche di generazione di dati sintetici, inclusa la privacy differenziale.

Generazione di Dati Immagine
Sebbene sia vero che Faker, SDV e CTGAN non supportano nativamente la generazione di dati immagine e voce, esistono comunque strumenti open-source disponibili per questi scopi. Questi strumenti rappresentano la tecnologia più vicina all’AI in questo campo e attualmente possono servire come generatori di dati AI completi. Tuttavia, sono tipicamente più specializzati e spesso richiedono più configurazioni e competenze per essere utilizzati efficacemente. Ecco una breve panoramica:
Per la generazione di immagini:
- StyleGAN: Un’architettura GAN avanzata, particolarmente buona per immagini di volti di alta qualità.
- DALL-E mini (ora chiamato Craiyon): Una versione open-source ispirata a DALL-E di OpenAI, per generare immagini da descrizioni testuali.
- Stable Diffusion: Una recente innovazione nella generazione di immagini da testo, con implementazioni open-source disponibili.
Per la generazione di dati vocali:
- Librerie TTS (Text-to-Speech) come Mozilla TTS o Coqui TTS: Possono generare dati vocali sintetici da input testuali.
- WaveNet: Inizialmente sviluppato da DeepMind, ora con implementazioni open-source per generare voce realistica.
- Tacotron 2: Un altro modello popolare per generare voce umana, con versioni open-source disponibili.
Questi strumenti sono davvero “pronti all’uso” nel senso che sono disponibili pubblicamente, ma spesso richiedono:
- Maggiore configurazione tecnica (es. risorse GPU, dipendenze specifiche)
- Comprensione dei concetti di deep learning
- Eventualmente, messa a punto su dati specifici di dominio
Questo contrasta con strumenti come Faker, che sono più plug-and-play per tipi di dati più semplici. La complessità dei dati immagine e voce richiede modelli più sofisticati, che a loro volta richiedono più competenze per essere implementati efficacemente.
Best Practice per l’Utilizzo di Generatori di Dati AI
- Valida i dati sintetici: Assicurati che mantengano le proprietà statistiche e le relazioni dei dati originali.
- Utilizza l’esperienza sul campo: Integra la conoscenza del dominio per generare dati sintetici realistici e significativi.
- Combina con dati reali: Quando possibile, utilizza dati sintetici per aumentare i dataset reali piuttosto che sostituirli completamente.
- Considera le implicazioni sulla privacy: Anche con dati sintetici, sii cauto riguardo potenziali fughe di privacy, soprattutto in domini sensibili.
- Aggiorna regolarmente i modelli: Poiché i dati reali cambiano, aggiorna i tuoi modelli generativi per assicurarti che i dati sintetici rimangano rilevanti.
Il Futuro della Generazione di Dati AI
Poiché la tecnologia AI continua a progredire, possiamo aspettarci capacità di generazione dei dati ancora più sofisticate e versatili. Alcune tendenze emergenti includono:
- Realismo migliorato nei dati generati in tutti i domini
- Tecniche di preservazione della privacy migliorate integrate nei processi di generazione
- Strumenti più accessibili per utenti non tecnici per creare dataset sintetici personalizzati
- Aumento dell’uso di dati sintetici nel rispetto delle normative e nei test
Conclusione
I generatori di dati AI stanno rivoluzionando il modo in cui creiamo e lavoriamo con i dati. Dal superamento della scarsità di dati al miglioramento della privacy e della sicurezza, i dati sintetici offrono numerosi vantaggi in vari settori. Poiché la tecnologia continua a evolversi, svolgerà un ruolo sempre più cruciale nel guidare l’innovazione, migliorare i modelli di machine learning e consentire nuove possibilità nel prendere decisioni basate sui dati.
Sfruttando strumenti come la libreria Python Faker e generatori basati su AI più avanzati, le organizzazioni possono creare dataset diversificati e realistici su misura per le loro esigenze specifiche. Tuttavia, è cruciale affrontare la generazione di dati sintetici con attenzione, assicurandosi che i dati generati mantengano l’integrità e la rilevanza richieste per l’uso previsto.
Guardando al futuro, il potenziale dei generatori di dati AI è illimitato, promettendo di sbloccare nuove frontiere nella scienza dei dati, machine learning e oltre.
Per coloro che sono interessati a esplorare strumenti user-friendly e flessibili per la sicurezza del database, comprese le capacità di dati sintetici, consideri di visitare DataSunrise. La nostra suite completa di soluzioni offre una protezione robusta e funzionalità innovative per gli ambienti di dati moderni. Visiti il nostro sito web per una demo online e scopra come i nostri strumenti possono migliorare la Sua strategia di sicurezza dei dati.
“`Successivo
