
Esplorare i Vantaggi della Generazione di Dati Sintetici per i Flussi di Lavoro Moderni

Un recente sondaggio di Gartner su oltre 2.500 leader esecutivi ha rivelato che il 45% ha aumentato i propri investimenti in AI in risposta al clamore attorno a ChatGPT. Da DataSunrise, stiamo tenendo il passo con questa tendenza. Probabilmente ha già letto il nostro precedente articolo sugli strumenti basati su AI per la generazione di dati sintetici (casuali o falsi). Questo articolo si concentra maggiormente sul tema della generazione di dati sintetici con DataSunrise e alcuni altri strumenti gratuiti disponibili.
Sia per testare, addestrare o sviluppare, ottenere dati del mondo reale pone delle sfide. Preoccupazioni sulla privacy, problemi di disponibilità dei dati e restrizioni normative spesso ostacolano l’accesso ai dati reali. È qui che la generazione di dati casuali entra in gioco. Offre una soluzione creando dati artificiali che imitano le caratteristiche dei dati reali senza compromettere la privacy o la sicurezza.
Che Cos’è il Dato Sintetico?
I dati sintetici sono dati generati artificialmente che assomigliano ai dati del mondo reale in termini di proprietà statistiche, modelli e strutture. Non contengono alcuna informazione reale su individui o entità. Invece, crea questi dati utilizzando algoritmi e modelli matematici per mantenere l’autenticità evitando i rischi associati alla gestione di dati sensibili.
Capacità di DataSunrise nella Generazione di Dati Sintetici
DataSunrise offre una funzionalità robusta di generazione di dati casuali che imita accuratamente i dati reali. Le persone utilizzano questa funzionalità per vari scopi aziendali, dallo sviluppo e test al miglioramento degli algoritmi di machine learning. Esploriamo le capacità di DataSunrise nel campo della generazione di dati sintetici.
Test sulla Privacy e Sicurezza dei Dati
Una delle principali applicazioni dei dati è nei test sulla privacy e la sicurezza dei dati. Le organizzazioni, specialmente nei settori come finanza, sanità e legale, possono utilizzare dati sintetici per valutare i loro sistemi di sicurezza senza esporre informazioni sensibili reali. Ad esempio, un’ istituzione finanziaria può generare dati di transazioni sintetiche per testare i suoi sistemi di rilevamento delle frodi.
Addestramento di Modelli di Machine Learning
Le industrie utilizzano sempre più dati falsi per addestrare i modelli di machine learning. Questo approccio garantisce che la privacy dei dati effettivi non sia compromessa. Ad esempio, una società sanitaria può generare registri di pazienti sintetici per addestrare un modello predittivo per la diagnosi delle malattie senza violare la riservatezza dei pazienti.
Sviluppo e Test di Software
I dati sintetici sono inestimabili nello sviluppo del software. Forniscono dataset realistici per creare e valutare applicazioni, particolarmente in industrie come le telecomunicazioni. Ad esempio, una compagnia di telecomunicazioni può generare registri di chiamate sintetici per testare il suo software di fatturazione.
Analisi Sanitaria
Nella sanità, tali dati consentono ai ricercatori e agli scienziati dei dati di condurre studi ed esperimenti senza violare la riservatezza dei pazienti. Per esempio, un team di ricerca può generare dati di pazienti sintetici per studiare gli effetti di un nuovo farmaco.
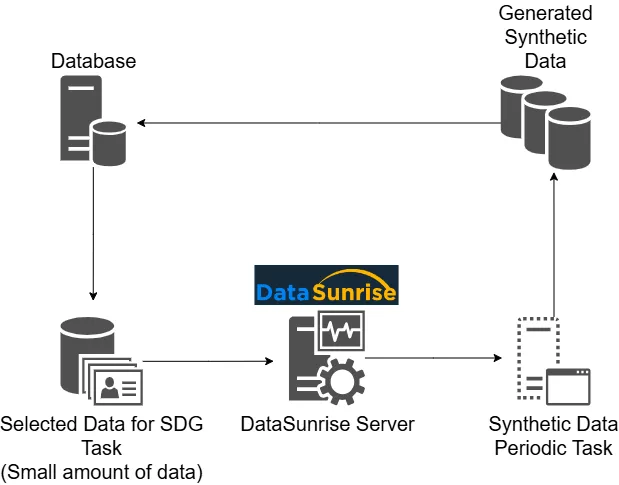
Come Generare Dati Sintetici con DataSunrise
DataSunrise semplifica il processo di generazione di dati casuali, rendendo facile integrare i dati in vari flussi di lavoro. Ecco una guida passo a passo su come generare dati usando DataSunrise.
Fase 1: Impostazioni Generali
Vai a Configurazione – Attività Periodiche. Clicca +Nuova Attività. Nella sottosezione Impostazioni Generali, imposta il nome per la tua Attività Periodica. Seleziona il tipo di attività – Generazione di Dati Sintetici – e su quale server avviare (opzionale).
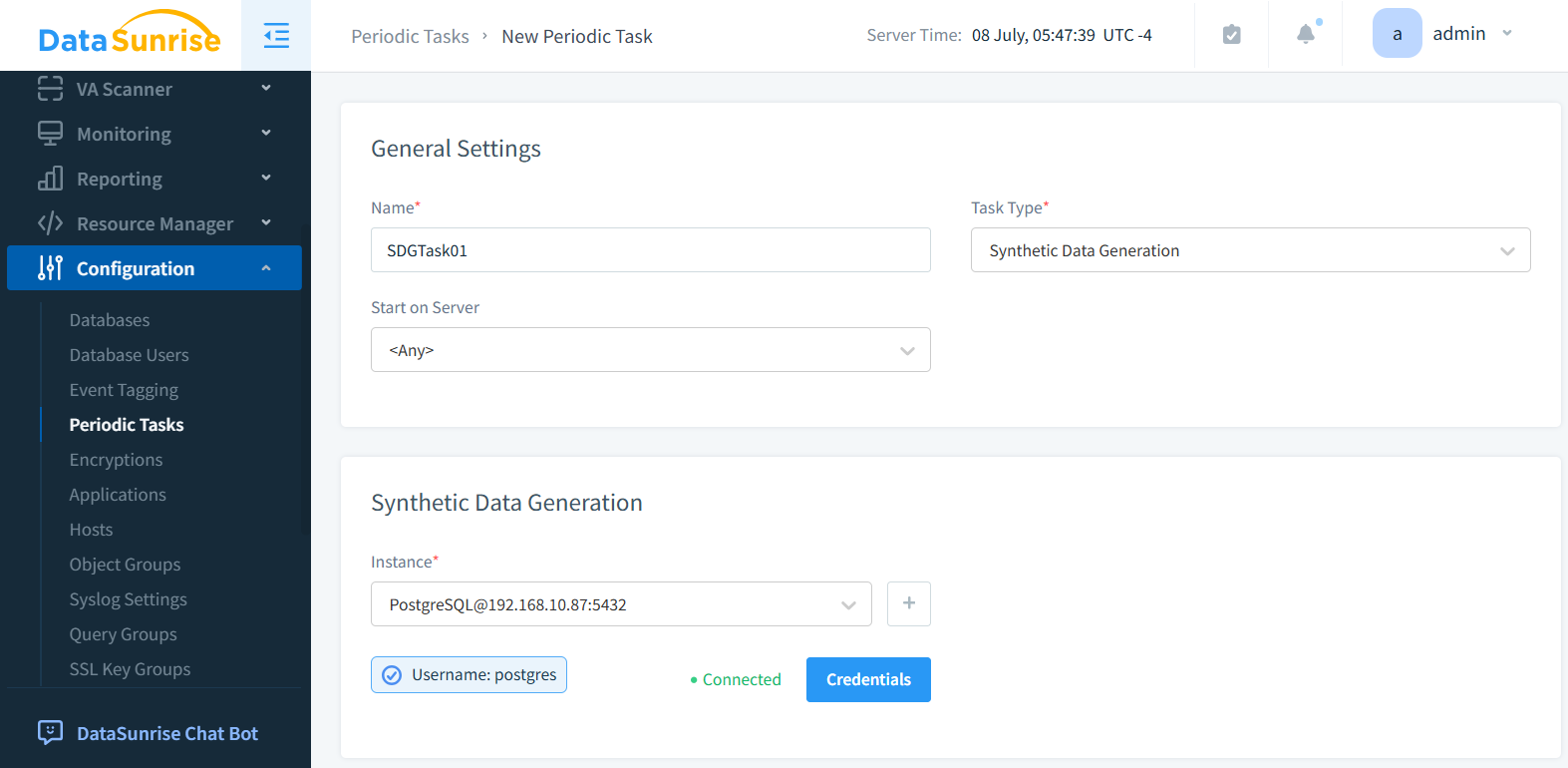
Fase 2: Selezionare l’Istanza del Database
Nella sottosezione Generazione di Dati Sintetici, seleziona l’istanza del database. L’istanza di PostgreSQL è selezionata nella figura sottostante.
Fase 3: Tabelle Generate
Nella sottosezione Tabelle Generate, seleziona le caselle di controllo necessarie (ad esempio, Tabella Vuota di Destinazione e Salta Generazione Tabella in Caso di Errore). Clicca +Seleziona per aprire una finestra in cui puoi selezionare gli oggetti del database di cui hai bisogno. Scegli un database, schema, tabella e colonna per cui verranno generati i dati sintetici. Dopo aver effettuato le tue selezioni, clicca Salva.
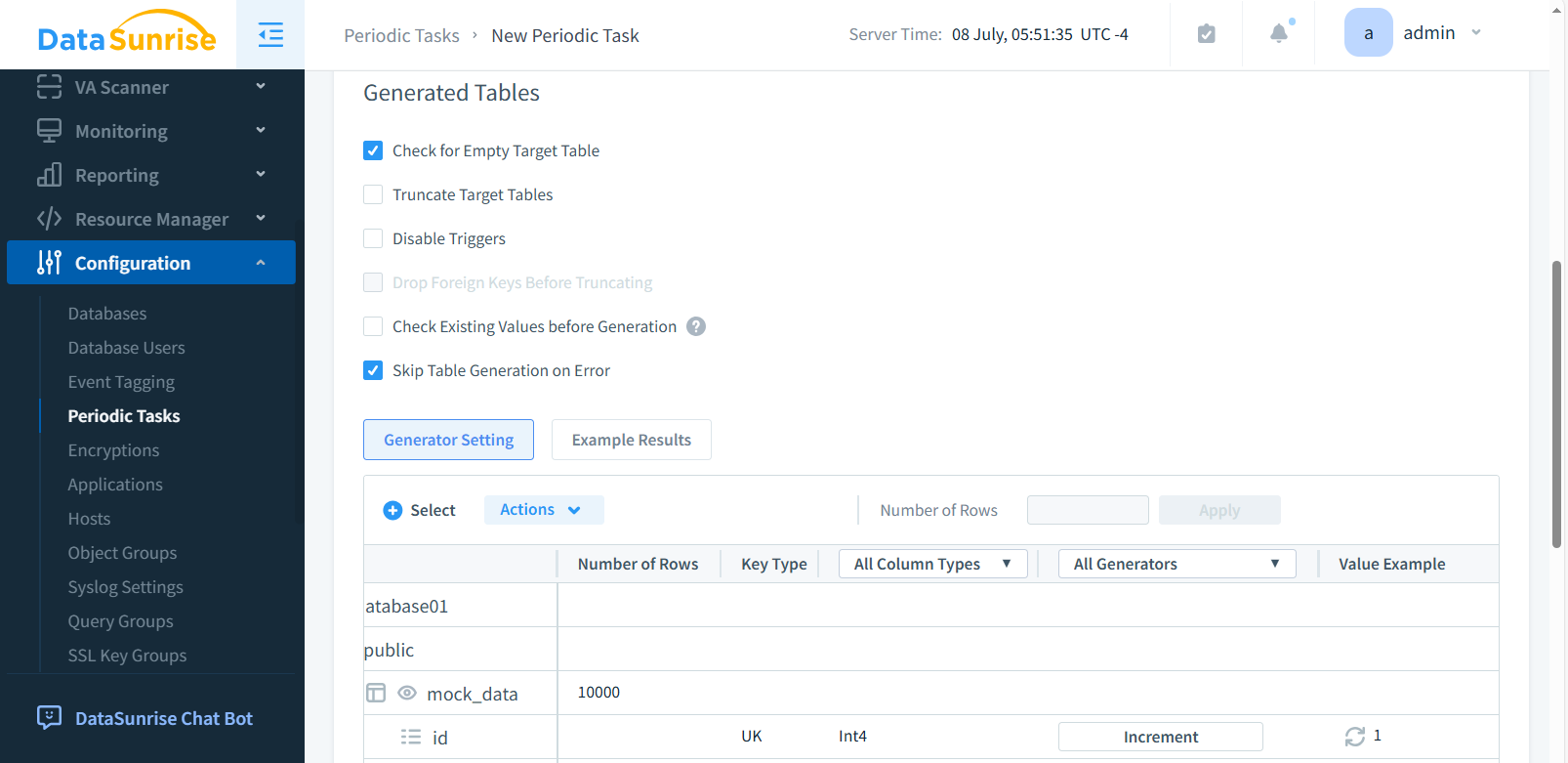
Fase 4: Selezione dei Generator (opzionale)
Nella colonna Tutti i Generator, puoi selezionare o creare il generator. Nella sezione Esempi di Risultati, vedrai l’elenco dei dati generati. Dopo aver completato tutto, clicca Applica o Salva. Questo è opzionale in quanto il sistema assegna generator predefiniti alle colonne selezionate.
Se vuole creare il proprio generator specifico (prima di creare l’attività di Generazione di Dati Sintetici), vai a Configurazione – Generator, e clicca +Crea Generator. Seleziona un tipo di generator e specifica i suoi parametri. Clicca Salva e sarà in grado di applicare il suo generator nell’attività di Generazione di Dati Sintetici.
‘Numero di righe’ in cima alla tabella diventa attivo quando la colonna è selezionata.
Fase 5: Salvare ed Eseguire l’Attività
Qui può vedere le Attività Periodiche con l’attività di Generazione di Dati Sintetici insieme a qualche altra attività periodica di comportamento dell’utente creata in precedenza.
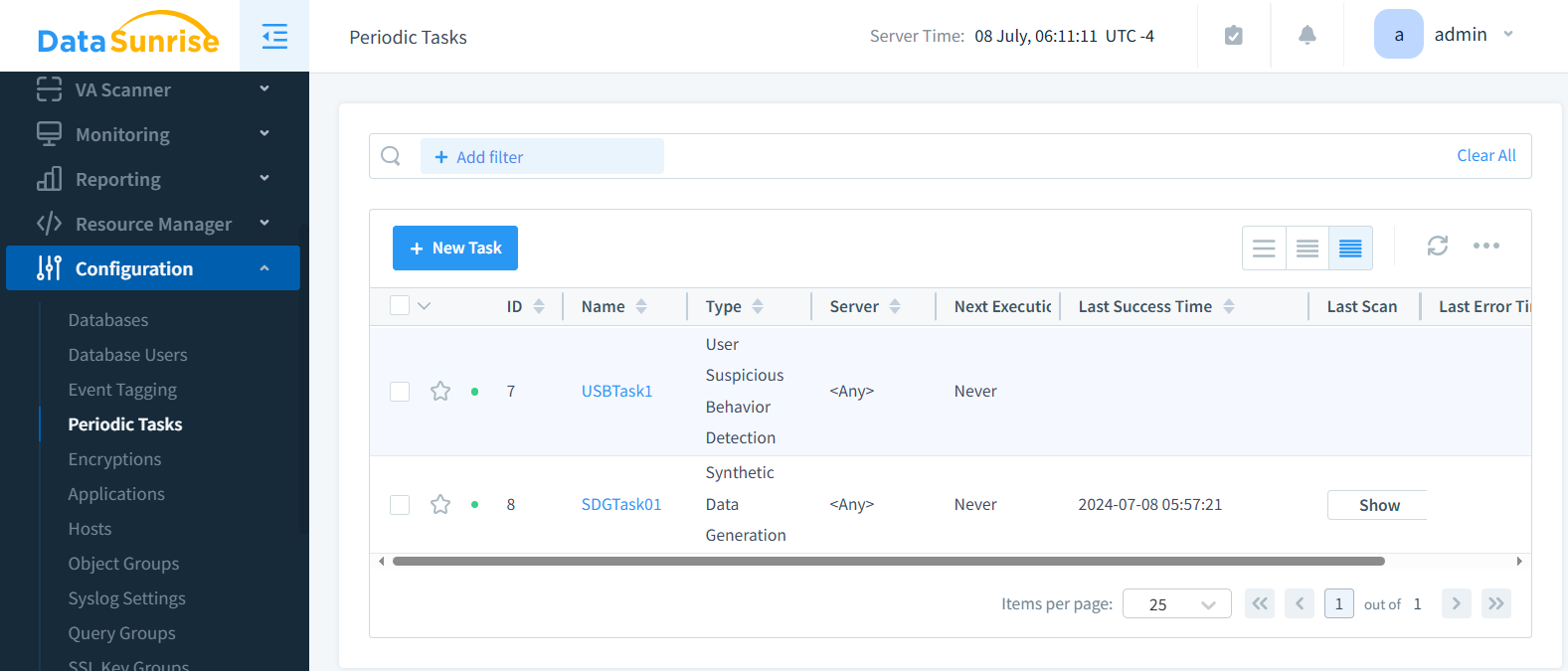
L’attività è pronta ora. Eseguire l’attività quando necessario o farla eseguire periodicamente.
Strumenti Online e Soluzioni Open-Source
DataSunrise offre un controllo altamente flessibile e robusto sulla generazione di dati casuali, insieme a soluzioni di sicurezza nel database di alto livello che forniscono la copertura più grande di database e magazzini cloud disponibili sul mercato. Tuttavia, cosa dire delle opzioni gratuite? Sono disponibili diversi strumenti online e librerie open-source per generare dati falsi senza costi. Esploriamo alcune opzioni popolari:
SDV (Synthetic Data Vault)
Abbiamo discusso brevemente di questo argomento nel nostro precedente articolo sulla generazione di dati AI. Lì abbiamo menzionato che CTGAN è un componente di SDV (Synthetic Data Vault). Per riassumere, SDV è una libreria open-source Python per generare dati relazionali multi-tabella. Utilizza il machine learning per creare dati artificiali che mantengono le proprietà statistiche del dataset originale. Per installarlo utilizzando pip, usa il seguente comando:
pip install sdv
Esempio di utilizzo:
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
# Scarica il dataset demo
real_data, metadata = download_demo(
modality='single_table',
dataset_name='fake_hotel_guests'
)
# Crea e adatta il sintetizzatore
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
# Genera dati falsi
synthetic_data = synthesizer.sample(num_rows=500)
# Mostra le prime righe dei dati generati
print(synthetic_data.head())Questo script utilizza il sintetizzatore GaussianCopula da SDV per generare dati sintetici basati sulle proprietà statistiche di un dataset reale.
Il risultato può apparire così:
CTGAN (Conditional Tabular GAN)
CTGAN è un modello basato su GAN specificamente progettato per generare dati tabulari sintetici. È particolarmente utile per dataset complessi con tipi di dati misti.
Si prega di consultare il nostro precedente articolo sugli strumenti AI per la generazione di dati sintetici per un esempio di codice di CTGAN.
Mockaroo
Mockaroo è uno strumento basato sul web, scritto in Ruby, che consente di generare dati casuali realistici in vari formati (CSV, JSON, SQL, ecc.) senza bisogno di programmazione. Offre un’interfaccia user-friendly e supporta schemi di dati personalizzati. L’accesso gratuito è limitato a 1000 righe di dati.
Best Practices per la Generazione di Dati Falsi
Per garantire dati di alta qualità:
- Comprendere i requisiti e i casi d’uso dei dati
- Scegliere il metodo di generazione appropriato in base alle proprie esigenze
- Convalidare i dati generati rispetto al dataset originale o ai requisiti
- Garantire la privacy dei dati evitando l’inclusione di informazioni sensibili
- Raffinare continuamente il processo di generazione basandosi su feedback e risultati
Conclusione
La generazione di dati sintetici fornisce una soluzione preziosa per le organizzazioni che cercano di lavorare con dati realistici salvaguardando le preoccupazioni sulla privacy e sicurezza. DataSunrise semplifica questo processo, rendendo facile integrare dati artificiali in vari flussi di lavoro. Tuttavia, è essenziale convalidare l’efficacia e l’affidabilità dei dati sintetici. Le organizzazioni dovrebbero garantire che i dati generati rappresentino accuratamente la distribuzione dei dati reali e mantengano le relazioni e le dipendenze necessarie.
In sintesi, la generazione di dati offre numerosi vantaggi, dall’aumento della privacy e sicurezza dei dati al miglioramento dei modelli di machine learning e dei test software. Con la funzionalità di Generazione di Dati Sintetici di DataSunrise, le organizzazioni possono navigare con sicurezza nel panorama dei dati e sfruttare il potere dei dati generati per le proprie esigenze aziendali.
Per maggiori informazioni, visiti il nostro sito web o richieda una demo online.
Successivo
