
Mascheramento dei Dati per Amazon Redshift

Introduzione
Con l’uso crescente di data warehouse sul cloud come Amazon Redshift, le organizzazioni affrontano nuove sfide nella protezione dei loro dati preziosi. Gli attori interni sono responsabili di quasi la metà (49%) delle violazioni dei dati in Europa, Medio Oriente e Africa, indicando frequenti occorrenze di minacce interne come l’abuso dei privilegi e gli errori non intenzionali dei dipendenti. Questa statistica allarmante evidenzia l’importanza di implementare misure di sicurezza robuste, come il mascheramento dei dati, per proteggere le informazioni sensibili e garantire la conformità normativa.
Comprendere il Mascheramento dei Dati per Amazon Redshift
Il mascheramento dei dati è una tecnica potente utilizzata per proteggere i dati sensibili in Redshift sostituendoli con informazioni fittizie ma realistiche. Quando applicato ad Amazon Redshift, aiuta le organizzazioni a mantenere la privacy dei dati consentendo allo stesso tempo agli utenti autorizzati di accedere e analizzare le informazioni di cui hanno bisogno.
Perché il Mascheramento dei Dati è Importante?
- Protegge i dati sensibili dall’accesso non autorizzato
- Garantisce la conformità con regolamenti come GDPR e HIPAA
- Riduce il rischio di violazioni dei dati e minacce interne
- Permette l’uso sicuro dei dati di produzione in ambienti non di produzione
Capacità di Mascheramento dei Dati Native di Amazon Redshift
Amazon Redshift offre funzioni di mascheramento dei dati integrate che possono aiutare a proteggere le informazioni sensibili. Queste funzioni permettono di mascherare i dati direttamente nelle vostre query o viste.
Funzioni di Mascheramento dei Dati Chiave di Redshift
Utilizziamo la seguente tabella con i dati sintetici di mockaroo.com:
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email) values (1, 'Garvey', 'Dummer', '[email protected]'); insert into MOCK_DATA (id, first_name, last_name, email) values (2, 'Sena', 'Trevna', '[email protected]'); …
Utilizzando le funzioni di mascheramento native, è possibile impiegare costruzioni come:
SELECT RIGHT(email, 4) AS masked_email FROM mock_data;
SELECT '[email protected]' AS masked_email FROM mock_data;
CREATE VIEW masked_users AS
SELECT
id,
LEFT(email, 1) || '****' || SUBSTRING(email FROM POSITION('@' IN email)) AS masked_email,
LEFT(first_name, 1) || REPEAT('*', LENGTH(first_name) - 1) AS masked_first_name
FROM mock_data;
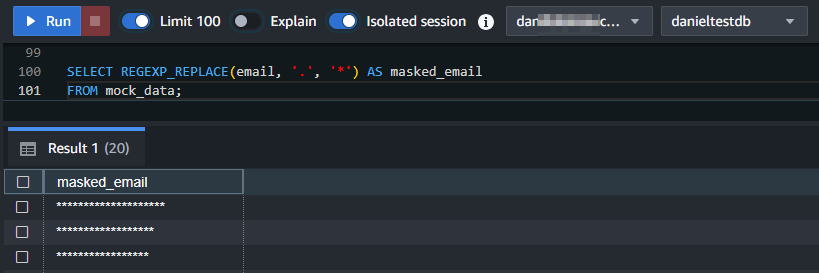
SELECT * FROM masked_users;SELECT REGEXP_REPLACE(email, '.', '*') AS masked_email FROM mock_data;
Il risultato per l’esempio di sostituzione con REGEXP_REPLACE è mostrato di seguito:
Un approccio più complesso può coinvolgere le funzioni Python integrate di Redshift.
-- Mask Email --
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
Mascheramento Dinamico vs. Mascheramento Statico dei Dati
Quando si implementa il mascheramento dei dati per Amazon Redshift, è essenziale comprendere la differenza tra mascheramento dinamico e statico.
Mascheramento Dinamico dei Dati
Il mascheramento dinamico applica le regole di mascheramento in tempo reale quando i dati vengono interrogati. Questo approccio offre flessibilità e non modifica i dati originali.
Vantaggi del mascheramento dinamico:
- Nessuna modifica ai dati di origine
- Le regole di mascheramento possono essere aggiornate facilmente
- Utenti diversi possono vedere diversi livelli di dati mascherati
Mascheramento Statico dei Dati
Il mascheramento statico altera permanentemente i dati nel database. Questo metodo è tipicamente utilizzato quando si creano copie dei dati di produzione per scopi di test o sviluppo.
Vantaggi del mascheramento statico:
- Mascheramento coerente in tutti gli ambienti
- Impatto ridotto delle prestazioni sulle query
- Adatto per la creazione di set di dati sanitizzati
Creare un’Istanza di DataSunrise per il Mascheramento Dinamico dei Dati
Per implementare il mascheramento dinamico avanzato dei dati per Amazon Redshift, è possibile utilizzare soluzioni di terze parti come DataSunrise. Ecco come iniziare con DataSunrise:
- Accedi alla tua dashboard di DataSunrise
- Vai alla sezione “Istanze”
- Fai clic su “Aggiungi Istanza” e seleziona “Amazon Redshift”
- Inserisci i dettagli della tua connessione Redshift
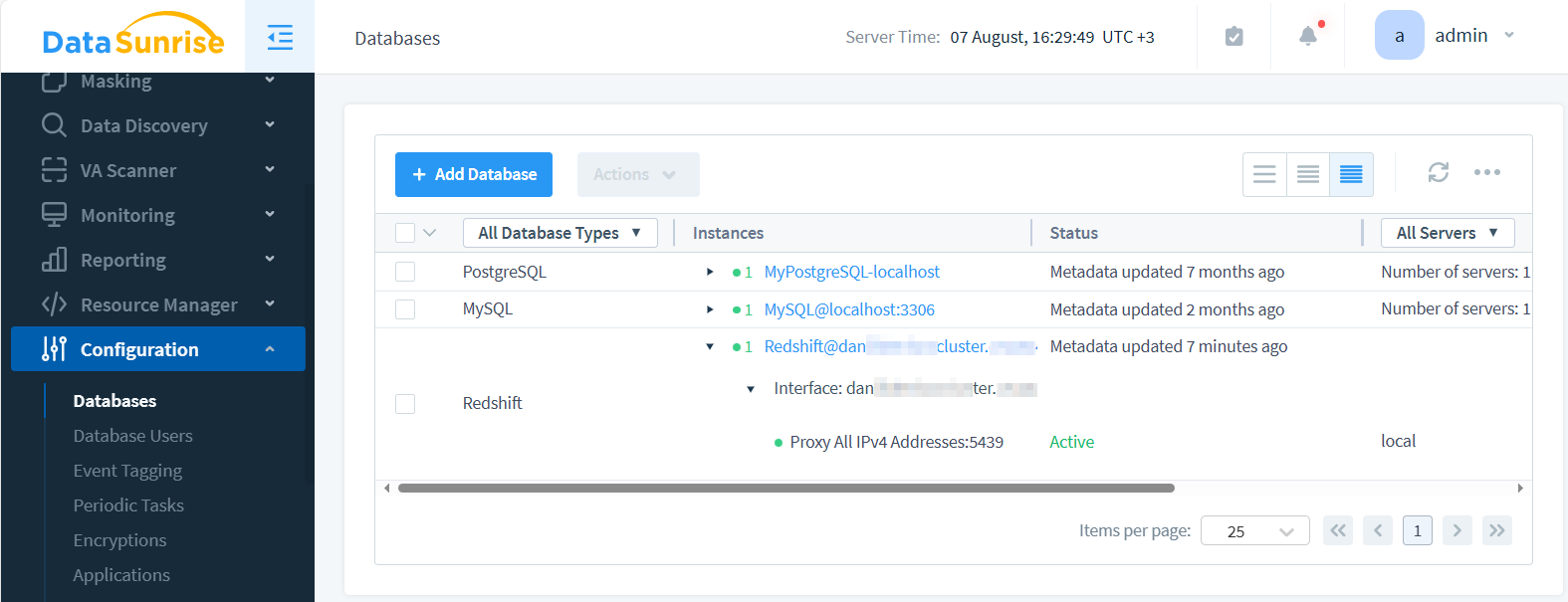
L’immagine qui sotto mostra l’istanza appena creata, che appare alla fine della lista.
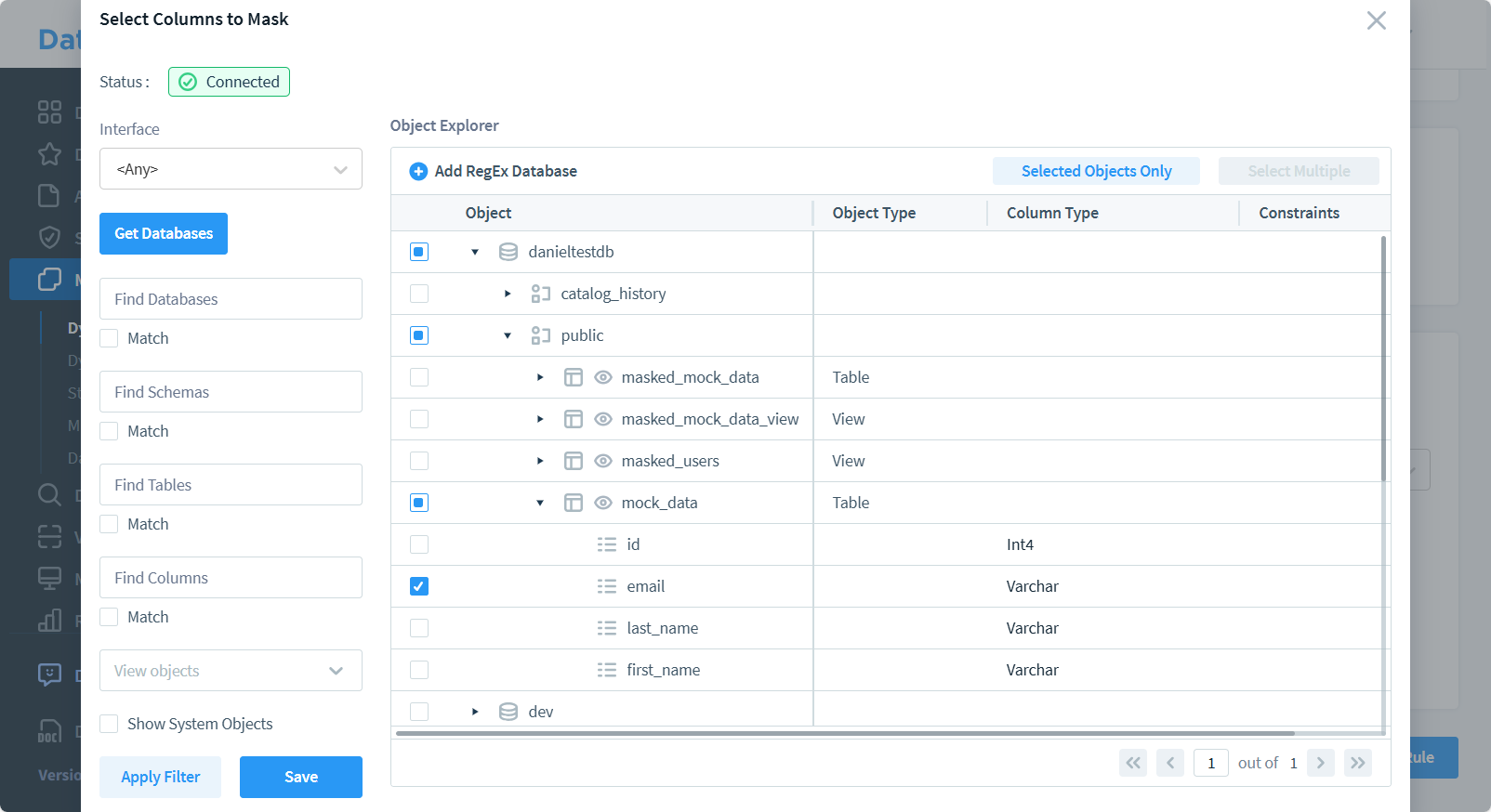
- Configura le regole di mascheramento per le colonne sensibili
- Salva e applica la configurazione
Una volta impostato, è possibile visualizzare i dati mascherati dinamicamente interrogando la propria istanza Redshift tramite il proxy di DataSunrise.
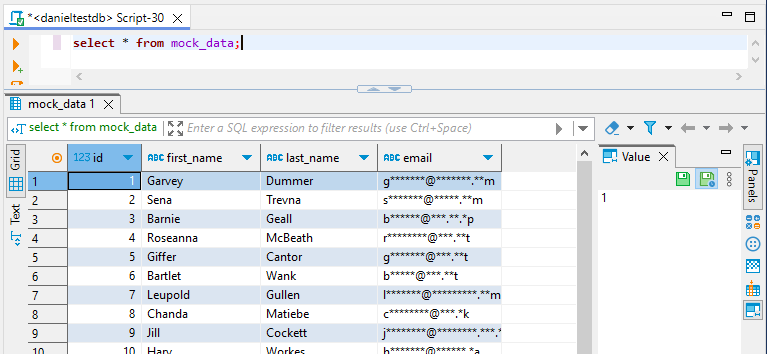
Notate che la colonna dell’email è mascherata. Questo dimostra una regola di mascheramento dinamico in azione. I dati vengono offuscati in tempo reale mentre la query viene eseguita, proteggendo le informazioni sensibili senza alterare i dati sottostanti.
Migliori Pratiche per il Mascheramento dei Dati in Amazon Redshift
Per garantire una protezione efficace dei dati, segui queste migliori pratiche:
- Identificare e classificare i dati sensibili
- Utilizzare una combinazione di tecniche di mascheramento
- Rivedere e aggiornare regolarmente le regole di mascheramento
- Monitorare l’accesso ai dati mascherati
- Formare i dipendenti sulle politiche di privacy dei dati
Garantire la Conformità Normativa con il Mascheramento dei Dati
Il mascheramento dei dati svolge un ruolo cruciale nel soddisfare i requisiti normativi. Implementando strategie di mascheramento robuste, le organizzazioni possono:
- Proteggere le informazioni di identificazione personale (PII)
- Assicurare i principi di minimizzazione dei dati
- Mantenere l’integrità dei dati preservando la privacy
- Dimostrare la dovuta diligenza negli sforzi di protezione dei dati
Sfide e Considerazioni
Sebbene il mascheramento dei dati offra vantaggi significativi, è importante essere consapevoli delle potenziali sfide:
- Impatto delle prestazioni sulle query
- Mantenere la coerenza dei dati tra sistemi
- Bilanciare la sicurezza con l’usabilità dei dati
- Gestire relazioni complesse tra dati
Tendenze Future nel Mascheramento dei Dati per i Data Warehouse sul Cloud
Man mano che l’adozione del cloud continua a crescere, ci aspettiamo di vedere progressi nelle tecnologie di mascheramento dei dati:
- Algoritmi di mascheramento basati su AI
- Integrazione con piattaforme di governance dei dati
- Compatibilità migliorata tra cloud
- Reportistica di conformità automatizzata
DataSunrise ha già implementato tutte le tendenze descritte qui, rendendo il nostro prodotto la soluzione leader per ambienti multi-storage.
Conclusione
Il mascheramento dei dati per Amazon Redshift è una componente essenziale di una strategia di protezione dei dati completa. Implementando tecniche di mascheramento efficaci, le organizzazioni possono proteggere le informazioni sensibili, garantire la conformità normativa e mitigare i rischi associati alle violazioni dei dati. Con l’evolversi dello scenario delle minacce, è cruciale rimanere aggiornati sulle ultime tecnologie e migliori pratiche di mascheramento dei dati.
Per chi cerca soluzioni avanzate di protezione dei dati, DataSunrise offre strumenti all’avanguardia e di ultima generazione per la sicurezza nel database, incluse funzionalità di audit e scoperta dei dati. Per sperimentare la potenza della suite di protezione dei dati completa di DataSunrise, visita il nostro sito web per una demo online e fai il primo passo verso la sicurezza dei tuoi preziosi asset di dati.
