
Mascheramento Statico dei Dati in Greenplum: Potenziare la Sicurezza dei Dati e la Conformità

Greenplum, un potente data warehouse open-source, offre robuste funzionalità per la gestione e l’analisi di grandi insiemi di dati. Man mano che le organizzazioni trattano quantità crescenti di informazioni sensibili, il bisogno di efficaci metodi di protezione dei dati è diventato fondamentale. Il mascheramento statico dei dati protegge le informazioni sensibili in Greenplum consentendo comunque agli utenti di utilizzarle per diverse esigenze. Questo articolo esplora il concetto del mascheramento statico dei dati in Greenplum, i suoi benefici, le sfide e le migliori pratiche per l’implementazione.
Mascheramento Statico dei Dati: Definizione e Benefici
Il mascheramento statico dei dati è un processo che sostituisce i dati sensibili con informazioni realistiche ma fittizie. Questo metodo aiuta le organizzazioni a mantenere i propri dati importanti al sicuro, consentendo loro di utilizzare i dati mascherati per test, sviluppo, o analisi.
In Greenplum, il mascheramento statico dei dati aggiunge un ulteriore livello di sicurezza. Mantiene l’informazione sensibile privata, anche quando condivisa con utenti non autorizzati o spostata in ambienti di non produzione.
Il principale obiettivo del mascheramento statico dei dati è quello di creare una versione dei dati che appaia e si comporti come l’originale, senza però contenere informazioni sensibili.
Questo metodo permette alle organizzazioni di utilizzare i dati nascosti per diverse finalità, mantenendo sicurezza e riservatezza dei dati originali.
L’implementazione del mascheramento statico dei dati in Greenplum offre diversi vantaggi significativi:
Potenzia la Sicurezza dei Dati: Sostituendo informazioni sensibili con dati fittizi, le organizzazioni possono ridurre significativamente il rischio di violazioni dei dati. Anche se utenti non autorizzati accedono ai dati mascherati, non potranno estrarre informazioni sensibili o preziose.
Conformità alle Norme: Molti settori sono soggetti a rigide regolamentazioni sulla protezione dei dati come GDPR, HIPAA, o PCI DSS. Il mascheramento statico dei dati aiuta le organizzazioni a seguire queste norme, assicurando che i dati sensibili non compaiano in ambienti di non produzione.
Migliora Test e Sviluppo: Il mascheramento statico dei dati permette alle organizzazioni di utilizzare dati simili a quelli di produzione in ambienti di test e sviluppo. Questo approccio fornisce risultati di test più accurati e affidabili. Sviluppatori e tester possono utilizzare dati simili a situazioni reali senza rischiare le informazioni sensibili.
Riduzione dei Costi: L’utilizzo di dati mascherati invece di set di dati sintetici aiuta le organizzazioni, specialmente nella preparazione dei dati per scopi di non produzione. Questa efficienza può portare a significativi risparmi sui costi nel lungo termine.
Condivisione dei Dati: Il mascheramento statico dei dati permette alle organizzazioni di condividere dati con fornitori terzi, partner o team di sviluppo offshore senza esporre le informazioni sensibili. Questa capacità facilita la collaborazione mantenendo la sicurezza dei dati.
Le Sfide e le Tecniche
Seppur offrendo numerosi vantaggi, il mascheramento statico dei dati presenta alcune sfide che le organizzazioni devono affrontare:
Mantenimento della Coerenza dei Dati: Una delle sfide principali è assicurare che i dati mascherati rimangano coerenti tra le tabelle correlate. Per mantenere l’integrità referenziale del database, è necessario preservare le relazioni tra i diversi elementi di dati.
Preservazione dell’Utilità dei Dati: I dati mascherati devono mantenere gli stessi schemi e caratteristiche dei dati originali, essenziale per l’analisi e il test. Mantenere il giusto equilibrio tra protezione dei dati e utilità dei dati può essere impegnativo.
Impatto sulle Prestazioni: Il processo di mascheramento può richiedere molto tempo e risorse, a seconda delle tecniche utilizzate e della quantità di dati. Le organizzazioni devono considerare l’impatto sulle prestazioni nel loro ambiente Greenplum.
Identificazione dei Dati Sensibili: Identificare accuratamente tutti gli elementi di dati sensibili all’interno di una struttura complessa può essere una sfida ardua. Omettere anche solo un singolo campo sensibile può compromettere l’intero sforzo di mascheramento.
Greenplum fornisce vari metodi per implementare il mascheramento statico dei dati, inclusi funzioni integrate, strumenti di terze parti e script personalizzati. Alcune delle tecniche comuni utilizzate nel mascheramento statico dei dati in Greenplum comprendono:
Sostituzione: Questa tecnica prevede la sostituzione dei dati sensibili con valori realistici ma fittizi.
Rimescolamento: Questo metodo coinvolge la randomizzazione dei valori all’interno di una colonna, mantenendo le proprietà statistiche complessive dei dati pur oscurando i singoli record.
Cifratura: È possibile trasformare i dati sensibili utilizzando algoritmi di cifratura. Sebbene questo metodo offra una protezione forte, potrebbe limitare l’usabilità dei dati per certe finalità.
Migliori Pratiche e Implementazione
Per massimizzare l’efficacia del mascheramento statico dei dati in Greenplum, considerare le seguenti migliori pratiche:
Identificare i Dati Sensibili: Analizzare accuratamente il database Greenplum per identificare tutti gli elementi di dati sensibili. Questo passo garantisce che il processo di mascheramento non trascuri alcuna informazione riservata.
Scegliere Tecniche di Mascheramento Appropriate: Selezionare tecniche di mascheramento che meglio si adattano ai tipi di dati e ai requisiti di sicurezza. Diversi elementi di dati possono richiedere approcci di mascheramento differenti per mantenere l’integrità dei dati e la loro usabilità.
Mantenere le Relazioni tra i Dati: Quando si mascherano dati tra più tabelle, assicurarsi di preservare le relazioni tra di esse. Questo passo è cruciale per mantenere la coerenza dei dati ed evitare problemi nelle applicazioni che dipendono da queste relazioni.
Documentare le Regole di Mascheramento: Mantenere una chiara documentazione di tutte le regole e procedure di mascheramento. Questa documentazione dovrebbe includere i campi mascherati, le tecniche utilizzate e qualsiasi eccezione o caso speciale.
Creazione di una Tabella Separata con Dati Mascherati
Ecco un esempio di come creare una tabella separata riempita con dati mascherati in Greenplum:
-- Tabella originale
CREATE TABLE customer_data (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
credit_card VARCHAR(16),
date_of_birth DATE
);
-- Inserimento di dati di esempio
INSERT INTO customer_data (name, email, credit_card, date_of_birth)
VALUES ('John Doe', 'john@example.com', '1234567890123456', '1980-05-15');
-- Creazione della tabella mascherata
CREATE TABLE masked_customer_data AS
SELECT
id,
'Customer_' || id AS masked_name,
'user_' || id || '@masked.com' AS masked_email,
SUBSTRING(credit_card, 1, 4) || 'XXXXXXXXXXXX' AS masked_credit_card,
date_of_birth + (RANDOM() * 365 * INTERVAL '1 day') AS masked_date_of_birth
FROM customer_data;
-- Visualizzazione dei dati mascherati
SELECT * FROM masked_customer_data;
Questo esempio crea una nuova tabella chiamata `masked_customer_data` con versioni mascherate dei campi sensibili. Cambiamo il `name` in “Customer_” seguito dall’ID.
Il sistema nasconde l’`email` in un formato mascherato. Il `credit_card` mostra solo le prime quattro cifre. Il resto è sostituito con caratteri ‘X’.
La `date_of_birth` viene spostata di un numero casuale di giorni, fino a un anno. Questo mantiene la distribuzione generale delle età pur nascondendo le date di nascita esatte.
Implementazione tramite DataSunrise
Greenplum aiuta gli utenti a mascherare i dati statici, tuttavia questo può essere complicato e lento per database di grandi dimensioni. In tali circostanze, suggeriamo l’utilizzo di soluzioni di terze parti. Per iniziare questo in DataSunrise, è necessario creare un’istanza di un database Greenplum.
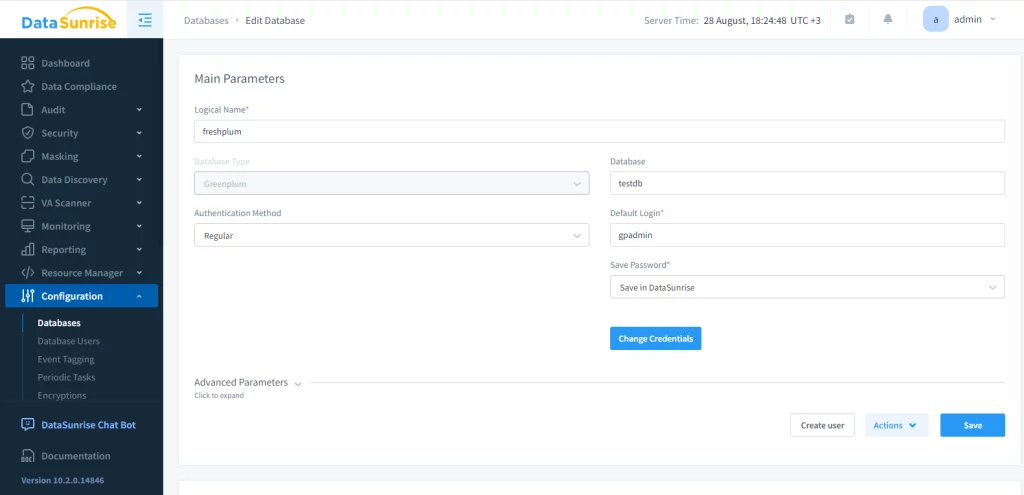
L’istanza consente di interagire con il database sorgente tramite audit, regole e compiti di mascheramento e sicurezza. Successivamente, bisogna configurare un compito di mascheramento statico. Questo passo comprende tre azioni: scegliere il server di partenza, selezionare il database sorgente e di destinazione (entrambi devono essere Greenplum) e impostare le regole di mascheramento. Per motivi di integrità, consigliamo di troncare lo schema di destinazione.
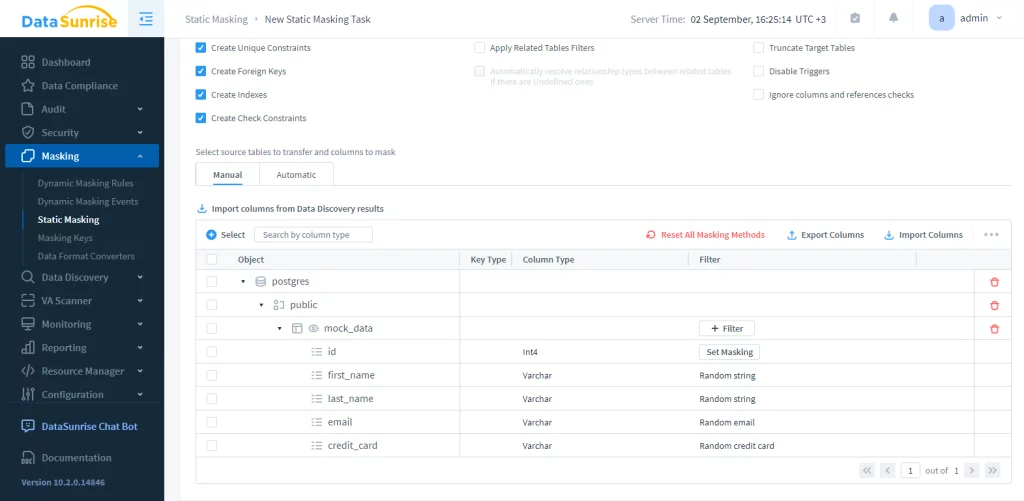
In questo esempio, la tabella mascherata è `mock_data` nel database `postgres`. È sufficiente avviare il compito. Il risultato è il seguente:

Conclusione
Il mascheramento statico dei dati in Greenplum è una potente tecnica per potenziare la sicurezza dei dati e la conformità. Utilizzando metodi efficaci, le organizzazioni possono proteggere le informazioni sensibili mantenendo comunque l’usabilità dei dati per test, sviluppo e analisi.
Con la crescente preoccupazione per la privacy dei dati e il rafforzamento delle normative, il mascheramento statico dei dati è essenziale per le aziende che utilizzano Greenplum per mantenere sicuri i loro dati. Le organizzazioni possono utilizzare le informazioni di questo articolo per creare strategie di mascheramento statico efficaci, proteggendo le informazioni sensibili e consentendo comunque l’uso efficace dei dati preziosi.
Successivo
