
Mascheramento Statico dei Dati in PostgreSQL

La protezione dei dati è cruciale per le aziende che gestiscono informazioni sensibili. PostgreSQL, un potente sistema di database open-source, offre diverse funzionalità di sicurezza. Una di queste è il mascheramento statico dei dati. Questo articolo esplora il mascheramento statico dei dati in PostgreSQL, i suoi vantaggi e come implementarlo efficacemente.
Che Cos’è il Mascheramento Statico dei Dati?
Il mascheramento statico dei dati è una tecnica che sostituisce i dati sensibili con informazioni realistiche ma false. Questo processo avviene prima che i dati vengano trasferiti in ambienti non di produzione. Aiuta a proteggere le informazioni confidenziali consentendo al contempo a sviluppatori e tester di lavorare con rappresentazioni accurate dei dati.
Il mascheramento statico dei dati in PostgreSQL prevede diversi passaggi. Innanzitutto, si identificano i dati sensibili.
Successivamente, si scelgono le tecniche di mascheramento appropriate. Poi, si creano copie mascherate dei dati originali. Infine, si sostituiscono i dati originali con quelli mascherati negli ambienti non di produzione.
Tecniche Comuni di Mascheramento Statico dei Dati
PostgreSQL offre varie tecniche di mascheramento. La sostituzione sostituisce i dati sensibili con valori falsi ma realistici. Ad esempio, sostituire nomi reali con nomi generati casualmente.
La miscelazione riordina i dati all’interno di una colonna. Mantiene la distribuzione dei dati ma interrompe il collegamento tra i record. L’alterazione numerica modifica i valori numerici mantenendo le loro proprietà statistiche. Lo spostamento delle date sposta le date avanti o indietro di un periodo fisso.
Implementare il Mascheramento Statico dei Dati in PostgreSQL
Per implementare il mascheramento statico dei dati in PostgreSQL, inizia identificando i dati sensibili. Esamina lo schema del tuo database e identifica le colonne contenenti informazioni sensibili.
Successivamente, crea regole di mascheramento. Sviluppa regole per ogni tipo di dato sensibile. Assicurati che i dati mascherati rimangano utili per test e sviluppo.
Scrivi query di mascheramento per applicare le tue regole. Ecco un esempio che crea una nuova tabella con dati mascherati:
-- Creare una nuova tabella per i dati mascherati
CREATE TABLE masked_customers AS
SELECT
id,
MD5(RANDOM()::TEXT) AS masked_name,
CONCAT(
SUBSTRING(MD5(RANDOM()::TEXT) FOR 8),
'@example.com'
) AS masked_email,
CASE
WHEN age < 18 THEN 'minor'
WHEN age BETWEEN 18 AND 65 THEN 'adult'
ELSE 'senior'
END AS masked_age_group,
ROUND(credit_score / 100) * 100 AS masked_credit_score
FROM customers;
-- Aggiungere eventuali indici necessari
CREATE INDEX ON masked_customers (id);
Questo esempio crea una nuova tabella chiamata `masked_customers` basata sulla tabella originale `customers`. Applica diverse tecniche di mascheramento:
- I nomi sono sostituiti con hash MD5 casuali.
- Il sistema maschera le email con stringhe casuali e un dominio generico.
- Le età delle persone vengono categorizzate in gruppi.
- I punteggi di credito sono arrotondati al centinaio più vicino.
Testa le tue query di mascheramento su un piccolo set di dati per assicurarti che funzionino correttamente. Poi, crea una copia mascherata del tuo database di produzione e applica le query di mascheramento a questa copia. Verifica che i dati mascherati nascondano correttamente le informazioni sensibili. Infine, utilizza questa tabella mascherata per ambienti non di produzione.
Implementazione tramite DataSunrise
Utilizzando solo strumenti nativi, è possibile fare il mascheramento statico. Tuttavia, potrebbe essere impegnativo con un database sostanziale. Per semplificare il processo, suggeriamo di utilizzare soluzioni di terze parti come DataSunrise. L'ordine di implementazione è il seguente:
In primo luogo, deve essere creata un'istanza del database PostgreSQL.
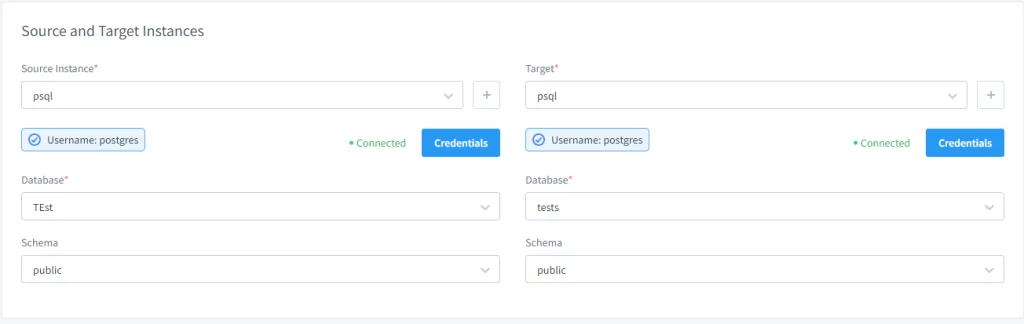
In seguito, configura il compito di mascheramento statico. Per fare ciò, devi selezionare i database e gli schemi sorgente e di destinazione. Per motivi di integrità, consigliamo di troncate lo schema di destinazione prima di trasferire i dati, anche se è facoltativo.
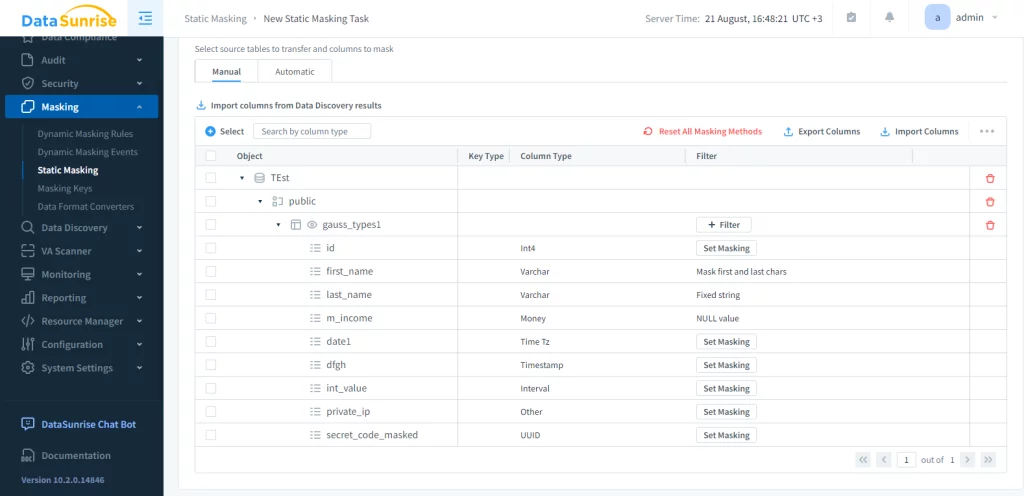
La prossima parte della configurazione del compito consiste nella selezione dei metodi di mascheramento.
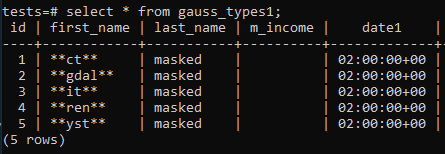
Basta avviare il compito. Puoi programmare o avviare questo processo manualmente in qualsiasi momento. Il risultato è il seguente:
Migliori Pratiche e Sfide
Segui le migliori pratiche per massimizzare l'efficacia del tuo mascheramento statico dei dati. Assicura la coerenza tra le tabelle e preserva l'integrità referenziale. Aggiorna periodicamente i tuoi dati mascherati e documenta le tue regole di mascheramento. Usa controlli di accesso solidi per limitare l'accesso sia ai dati originali che a quelli mascherati.
Il mascheramento statico dei dati presenta delle sfide. Mascherare grandi set di dati può essere dispendioso in termini di tempo e risorse. Bilanciare la protezione dei dati con il mantenimento di dati utili per i test può essere complicato. Mascherare dati in database con relazioni complesse richiede una pianificazione attenta.
Conclusione
Diversi strumenti possono aiutare con il mascheramento statico dei dati in PostgreSQL. pgMemento è un'estensione open-source per PostgreSQL per l'auditing e il mascheramento dei dati. Dataedo è uno strumento di documentazione del database e di mascheramento dei dati che supporta PostgreSQL. PostgreSQL Anonymizer è un'estensione che fornisce capacità di mascheramento dinamico dei dati.
Il mascheramento statico dei dati in PostgreSQL è una tecnica potente per proteggere le informazioni sensibili. Le organizzazioni possono proteggere la privacy dei dati, seguire le regole e mantenere i dati accurati per scopi non di produzione facendo le cose nel modo giusto. Man mano che la protezione dei dati diventa sempre più importante, padroneggiare il mascheramento statico dei dati in PostgreSQL è una competenza preziosa per gli amministratori di database e gli sviluppatori.
