
Mascheramento Statico dei Dati per Amazon Aurora

Introduzione
Man mano che le aziende si affidano sempre più ai database in Cloud come Amazon Aurora, cresce la necessità di misure robuste di sicurezza dei dati. Una tecnica cruciale in questo ambito è il mascheramento statico dei dati. Questo processo aiuta le organizzazioni a proteggere i dati riservati permettendo al contempo ambienti di test realistici. Sapeva che secondo uno studio recente di Verizon il 64% di tutti i dati compromessi sono informazioni personali? Questa statistica allarmante sottolinea l’importanza di implementare forti misure di protezione dei dati, incluso il mascheramento statico dei dati.
Che Cos’è il Mascheramento Statico dei Dati?
Il mascheramento statico dei dati è una tecnica di sicurezza dei dati che crea una replica di un database di produzione con informazioni sensibili sostituite da dati realistici ma fittizi. Questo approccio permette alle organizzazioni di utilizzare dati mascherati per test, sviluppo e analisi senza esporre le informazioni riservate effettive.
I principali vantaggi del mascheramento statico dei dati includono:
- Migliorata sicurezza dei dati
- Conformità alle normative sulla protezione dei dati
- Rischio ridotto di violazioni dei dati
- Migliore accuratezza dei test
Capacità di Amazon Aurora per il Mascheramento dei Dati
Dati di Test
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50), phone VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email, phone) values (1, 'Alica', 'Collyer', '[email protected]', '676-612-4979'); … insert into MOCK_DATA (id, first_name, last_name, email, phone) values (10, 'Nevsa', 'Justun', '[email protected]', '997-928-5900');
Amazon Aurora stessa non ha regole di trasformazione o mascheramento integrate. Invece, sarà necessario implementare la logica di mascheramento utilizzando query SQL o funzioni. Ecco alcuni approcci pratici (sia dinamici che statici):
Query SQL
Utilizza SQL per creare versioni mascherate dei tuoi dati. Ad esempio:
SELECT
id,
CONCAT(LEFT(first_name, 1), REPEAT('*', LENGTH(first_name) - 1)) AS masked_name,
CONCAT('****-****-****-', RIGHT(phone, 4)) AS masked_phone
FROM mock_data;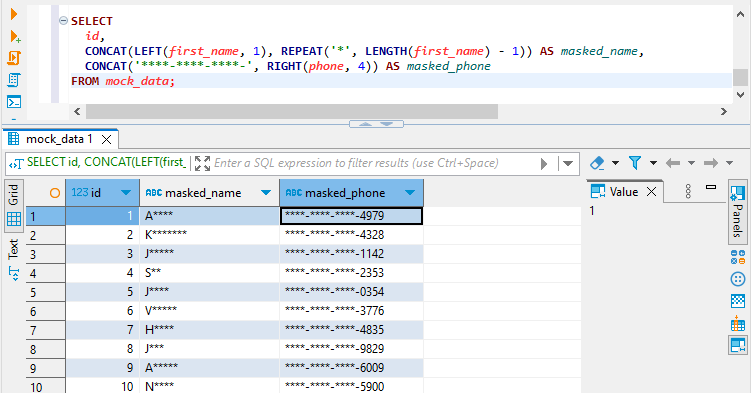
Funzioni Definite dall’Utente
Crea funzioni personalizzate per mascheramento più complesso o inserisci nella tabella statica:
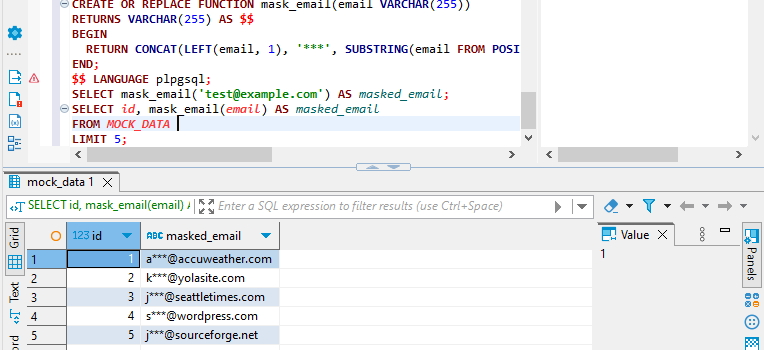
CREATE OR REPLACE FUNCTION mask_email(email VARCHAR(255))
RETURNS VARCHAR(255) AS $$
BEGIN
RETURN CONCAT(LEFT(email, 1), '***', SUBSTRING(email FROM POSITION('@' IN email)));
END;
$$ LANGUAGE plpgsql;
SELECT mask_email('[email protected]') AS masked_email;
SELECT id, mask_email(email) AS masked_email
FROM MOCK_DATA
LIMIT 5;Questi metodi permettono di implementare il mascheramento dinamico dei dati direttamente all’interno di Aurora senza fare affidamento su regole di trasformazione esterne. Essi sono più diretti e applicabili direttamente ai database Aurora.
Copia Tabella
Per implementare il mascheramento statico dei dati in Aurora PostgreSQL puoi semplicemente copiare i dati:
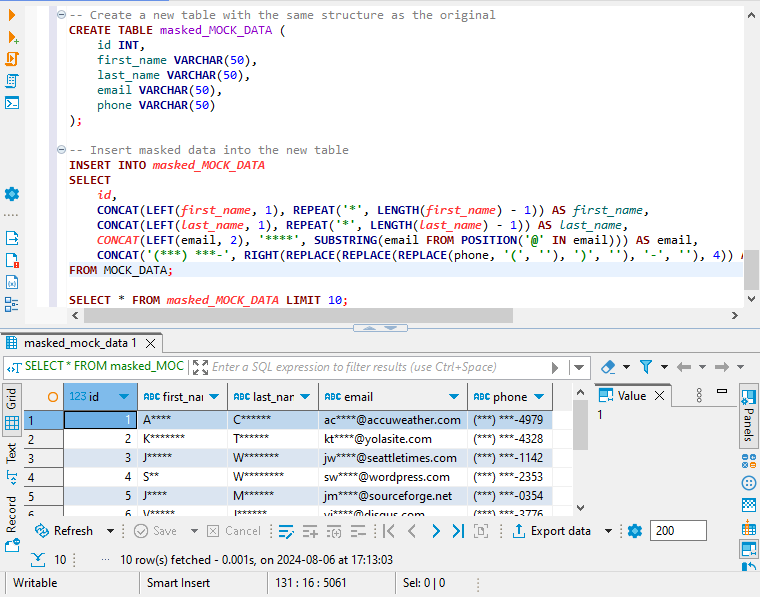
-- Crea una nuova tabella con la stessa struttura dell'originale
CREATE TABLE masked_MOCK_DATA (
id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50),
phone VARCHAR(50)
);
-- Inserisci dati mascherati nella nuova tabella
INSERT INTO masked_MOCK_DATA
SELECT
id,
CONCAT(LEFT(first_name, 1), REPEAT('*', LENGTH(first_name) - 1)) AS first_name,
CONCAT(LEFT(last_name, 1), REPEAT('*', LENGTH(last_name) - 1)) AS last_name,
CONCAT(LEFT(email, 2), '****', SUBSTRING(email FROM POSITION('@' IN email))) AS email,
CONCAT('(***) ***-', RIGHT(REPLACE(REPLACE(REPLACE(phone, '(', ''), ')', ''), '-', ''), 4)) AS phone
FROM MOCK_DATA;Per visualizzare un campione dei dati appena mascherati, eseguire la seguente query:
SELECT * FROM masked_MOCK_DATA LIMIT 10;
Per un mascheramento più avanzato o automatizzato, puoi considerare l’uso di strumenti di terze parti come DataSunrise che si integrano con Aurora e forniscono ulteriori capacità di mascheramento.
Impostare Compiti di Mascheramento Statico in DataSunrise
DataSunrise offre un’interfaccia facile da usare per impostare compiti di mascheramento statico dei dati per Amazon Aurora. Ecco una guida passo-passo:
- Crea un’istanza Aurora in DataSunrise
- Vai al modulo di Mascheramento dei Dati
- Crea un nuovo Compito di Mascheramento Statico (SMTaskAurora nella figura sotto)
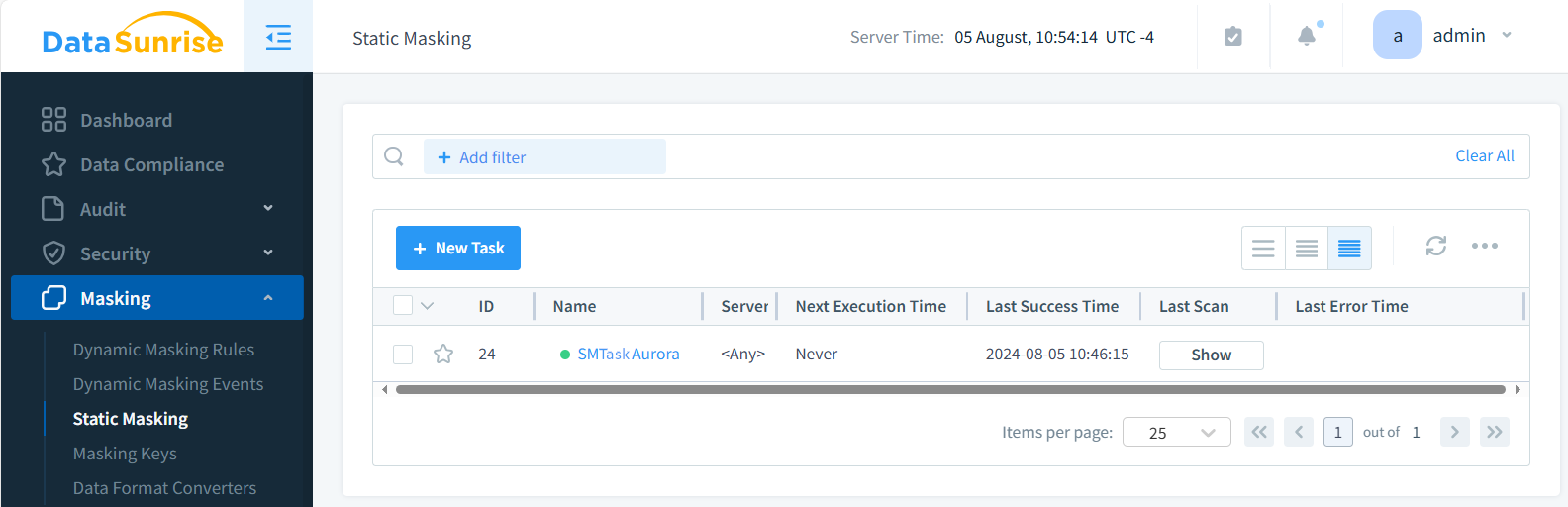
- Seleziona i database di origine e di destinazione
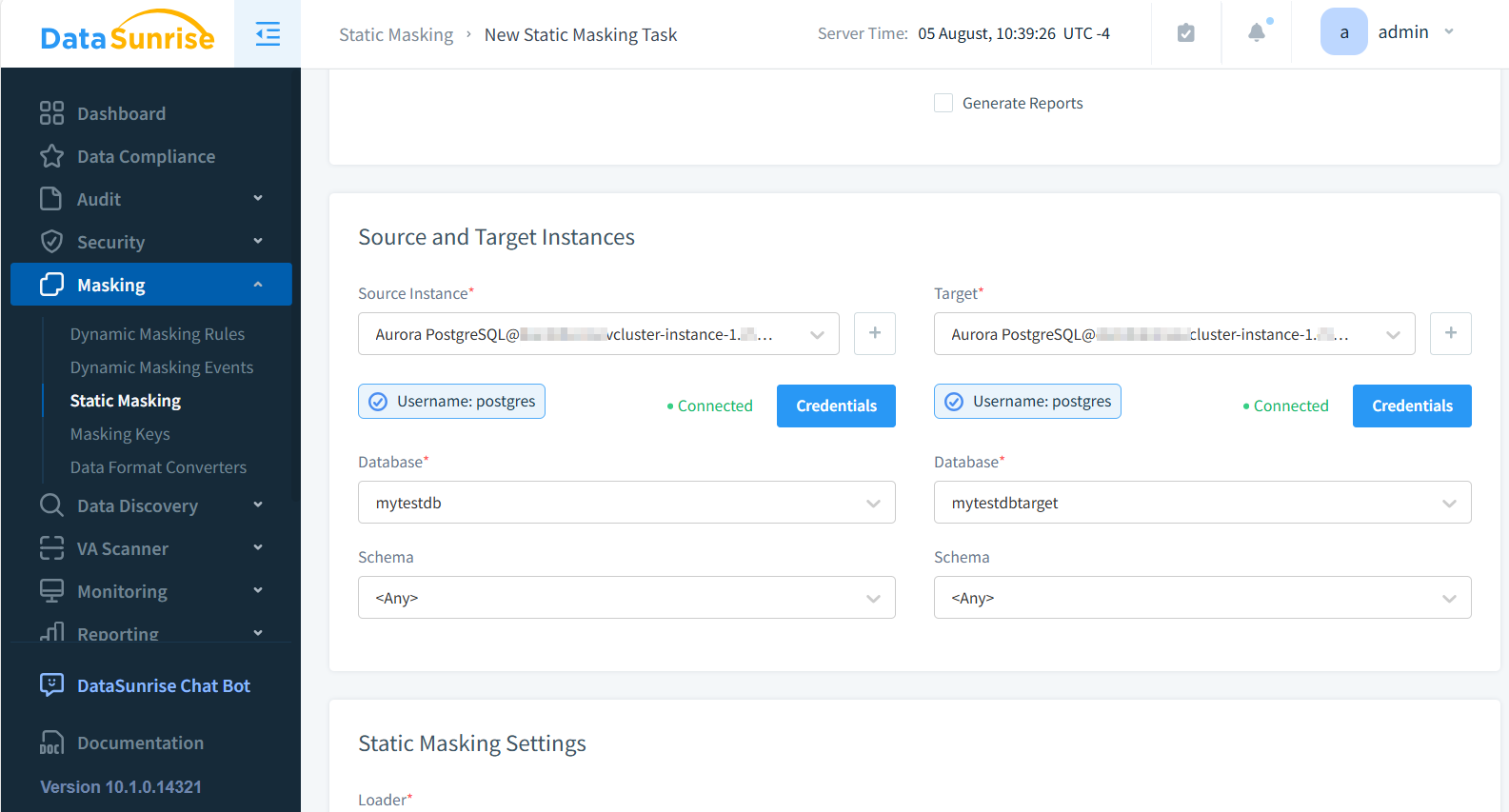
- Scegli le tabelle (mock_data nell’esempio sotto) e le colonne da mascherare (last_name, email, phone e ip_address)
- Applica il metodo di mascheramento (es., sostituzione, shuffling, crittografia preservante il formato)
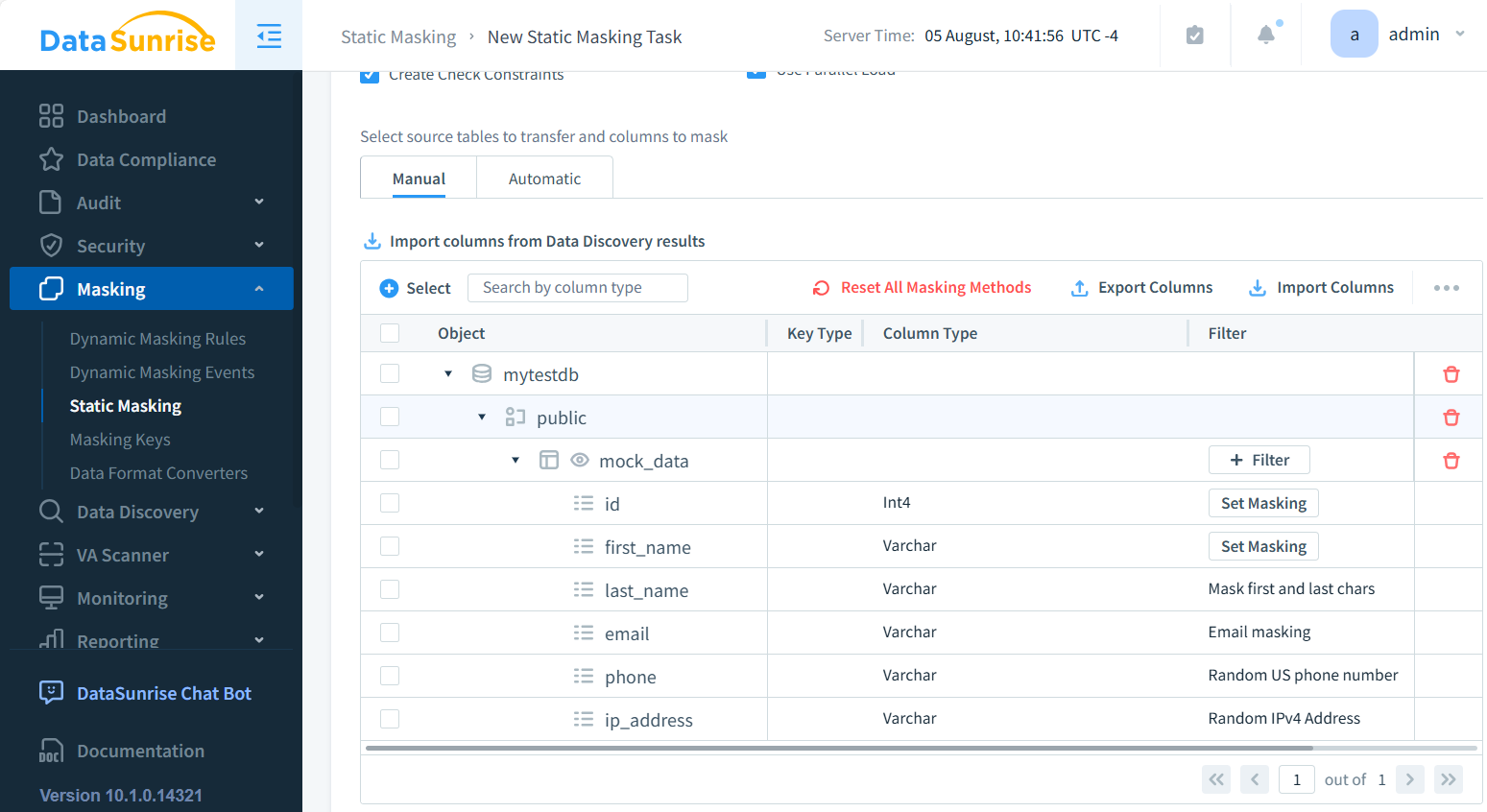
- Pianifica l’esecuzione del compito (Manuale di default)
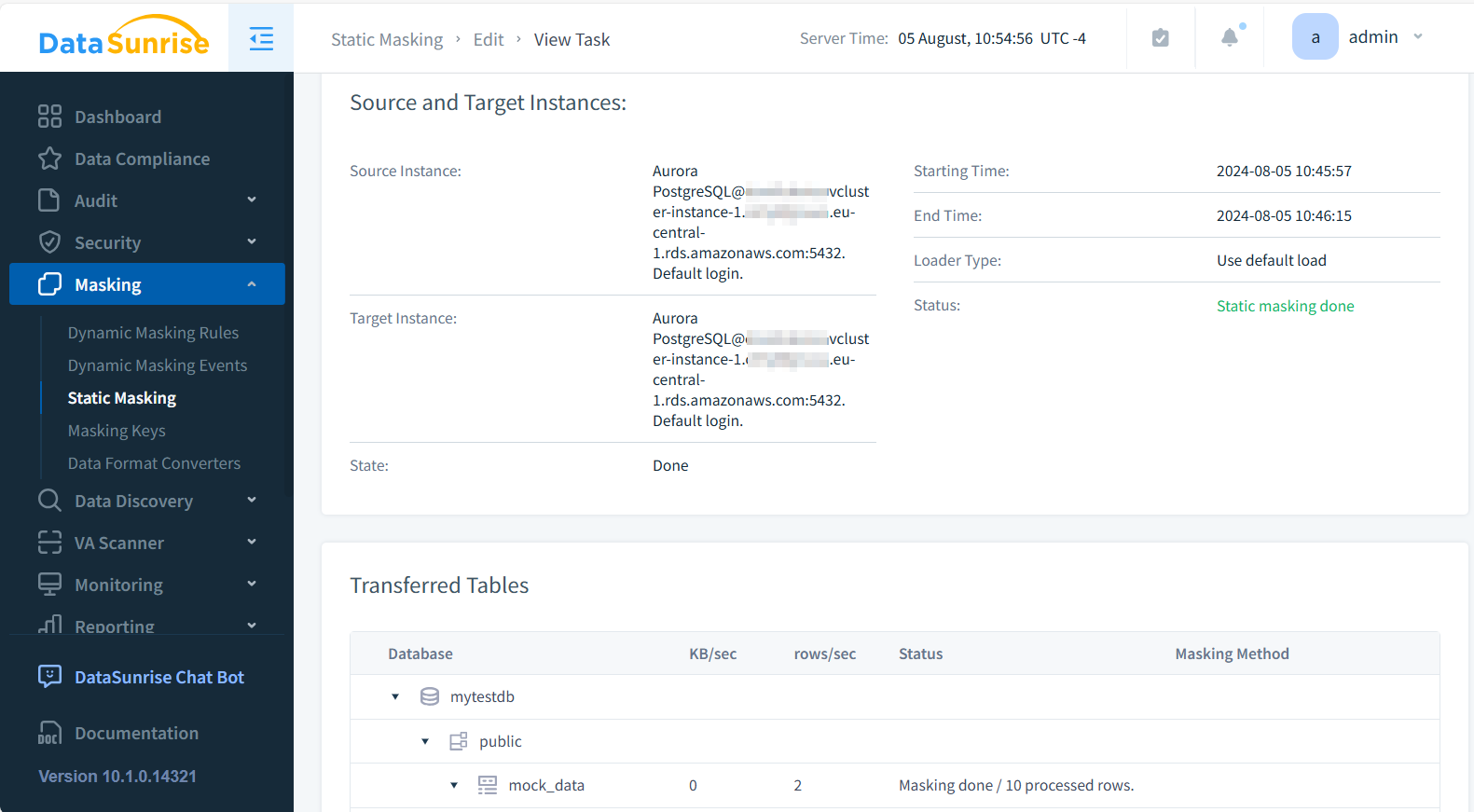
- Esegui il compito e verifica i risultati
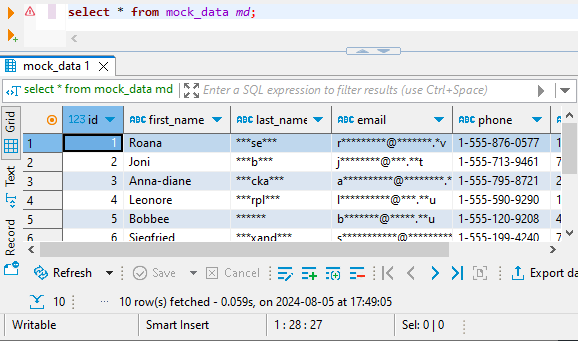
In DBeaver ora puoi interrogare i dati mascherati dal database di destinazione:
Monitorare i Risultati dell’Esecuzione
Dopo aver impostato un compito di mascheramento statico, è cruciale monitorarne l’esecuzione e verificarne i risultati. DataSunrise fornisce funzionalità complete di registrazione e reportistica a tale scopo:
- Controlla lo stato di esecuzione del compito nel cruscotto DataSunrise
- Rivedi i log dettagliati per eventuali errori o avvisi
- Confronta campioni di dati dai database di origine e di destinazione
- Genera report sulle colonne mascherate e la distribuzione dei dati
Approcci di Test delle Applicazioni Basati sui Dati
Quando si tratta di test delle applicazioni basati sui dati, sono disponibili due approcci principali:
1. Testing con Dati Mascherati
Questo approccio utilizza il mascheramento statico dei dati per creare un ambiente di test realistico con dati di produzione anonimizzati. È ideale per mantenere le relazioni e la distribuzione dei dati proteggendo al contempo le informazioni sensibili.
2. Testing con Dati Sintetici
I dati sintetici sono generati artificialmente per imitare le caratteristiche dei dati reali. Questo approccio offre maggiore flessibilità ma potrebbe non rappresentare appieno tutti i casi limite presenti nei dati di produzione.
Entrambi i metodi hanno i loro meriti, e la scelta dipende dai requisiti specifici di test e dai livelli di sensibilità dei dati.
Migliori Pratiche per il Mascheramento Statico dei Dati in Amazon Aurora
Per massimizzare l’efficacia del mascheramento statico dei dati per Amazon Aurora, consideri queste migliori pratiche:
- Identifica tutti gli elementi di dati sensibili nel tuo database
- Scegli tecniche di mascheramento appropriate per ciascun tipo di dato
- Mantieni la consistenza dei dati tra tabelle correlate
- Aggiorna regolarmente le regole di mascheramento per affrontare nuovi tipi di dati o regolamenti
- Combina mascheramento statico con mascheramento dinamico per una protezione completa
- Implementa controlli di accesso rigorosi per i database mascherati
Conclusione
Il mascheramento statico dei dati per Amazon Aurora è una tecnica cruciale per proteggere i dati sensibili garantendo al contempo processi di test e sviluppo efficaci. Utilizzando strumenti come DataSunrise, le organizzazioni possono implementare strategie di mascheramento robusto che bilanciano l’utilità dei dati con i requisiti di sicurezza e conformità.
Poiché le violazioni dei dati continuano a rappresentare rischi significativi, l’implementazione di forti misure di protezione dei dati, incluso il mascheramento statico dei dati, non è più facoltativa—è una necessità per una gestione responsabile dei dati.
DataSunrise offre strumenti all’avanguardia per la sicurezza nel database, inclusi audit, scoperta dei dati e capacità avanzate di mascheramento. La nostra interfaccia facile da usare rende semplice implementare strategie complete di protezione dei dati per Amazon Aurora e altre piattaforme di database. Visiti il nostro sito web per una demo online e per esplorare come possiamo aiutare a proteggere i tuoi preziosi asset di dati.
