
Name Shuffling
Introduzione
Le aziende affrontano la sfida di mantenere la privacy dei dati utilizzando comunque dati realistici per ambienti di test e sviluppo. È qui che entra in gioco il Name Shuffling e il data masking.
Fatto interessante: La SSA (Social Security Administration) rilascia dati sui nomi dei bambini dati ogni anno. In un anno tipico, ci sono circa 30.000 a 35.000 nomi unici usati per i neonati.
Questo articolo esplorerà il concetto di shuffling, la sua implementazione e i suoi benefici nella creazione di dati di test sicuri.
DataSunrise offre soluzioni di data masking all’avanguardia, caratterizzate da potenti tecniche di shuffling. La nostra piattaforma avanzata garantisce una protezione robusta dei dati mantenendo l’usabilità dei dati. Con DataSunrise, le organizzazioni possono conformarsi con fiducia alle regolamentazioni sulla privacy e proteggere le informazioni sensibili. Sperimenta il perfetto equilibrio tra sicurezza e usabilità nei tuoi processi di gestione dei dati.
DataSunrise consente la selezione casuale di valori da lessici definiti dall’utente. Questi lessici possono essere creati manualmente o popolati con valori dal database. Questo approccio implementa non solo lo shuffling ma anche la selezione casuale di valori.
Che Cos’è il Data Masking?
Prima di approfondire il name shuffling, affrontiamo brevemente il data masking. Il data masking è un metodo utilizzato per creare una versione strutturalmente simile ma inautentica dei dati di un’organizzazione. Sostituisce le informazioni sensibili con dati realistici ma falsi. Questo permette alle aziende di utilizzare dati mascherati per test, sviluppo e analisi senza rischiare l’esposizione di informazioni riservate.
Regolamentazioni e Conformità del Data Masking
I quadri normativi richiedono sempre più la protezione dei dati attraverso tecniche di masking. Il GDPR richiede adeguate misure di sicurezza per il trattamento dei dati personali. L’HIPAA impone la protezione delle informazioni sanitarie in ambienti non di produzione. Il PCI DSS vieta l’uso di dati reali dei titolari di carte per i test. Il CCPA dà ai consumatori il controllo sull’uso delle informazioni personali. Gli standard industriali spesso richiedono l’anonimizzazione dei dati di test. Le organizzazioni sanitarie devono affrontare rigidi requisiti di privacy dei dati dei pazienti. Le istituzioni finanziarie devono proteggere i dettagli finanziari dei clienti durante lo sviluppo. Le sanzioni per il mancato rispetto delle normative possono raggiungere milioni di dollari. Il data masking fornisce prove documentate di conformità alla privacy. Le norme spesso richiedono valutazioni formali del rischio per la gestione dei dati. Gli audit di conformità regolari verificano la corretta implementazione del masking. Le aziende devono dimostrare misure di sicurezza ragionevoli attraverso tecniche come lo shuffling.
Comprendere il Name Shuffling
Che Cos’è il Name Shuffling?
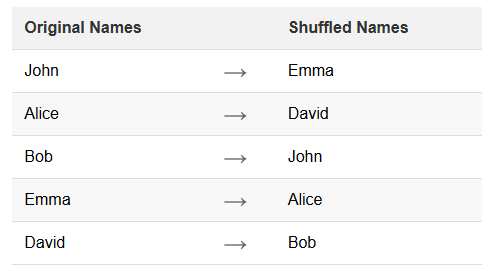
Il name shuffling è una tecnica specifica di data masking. Consiste nel riorganizzare i dati esistenti all’interno di un dataset. Questo metodo mantiene l’integrità e il realismo dei dati mentre oscura le identità individuali. Lo shuffling è particolarmente utile per proteggere le informazioni personali nei database.
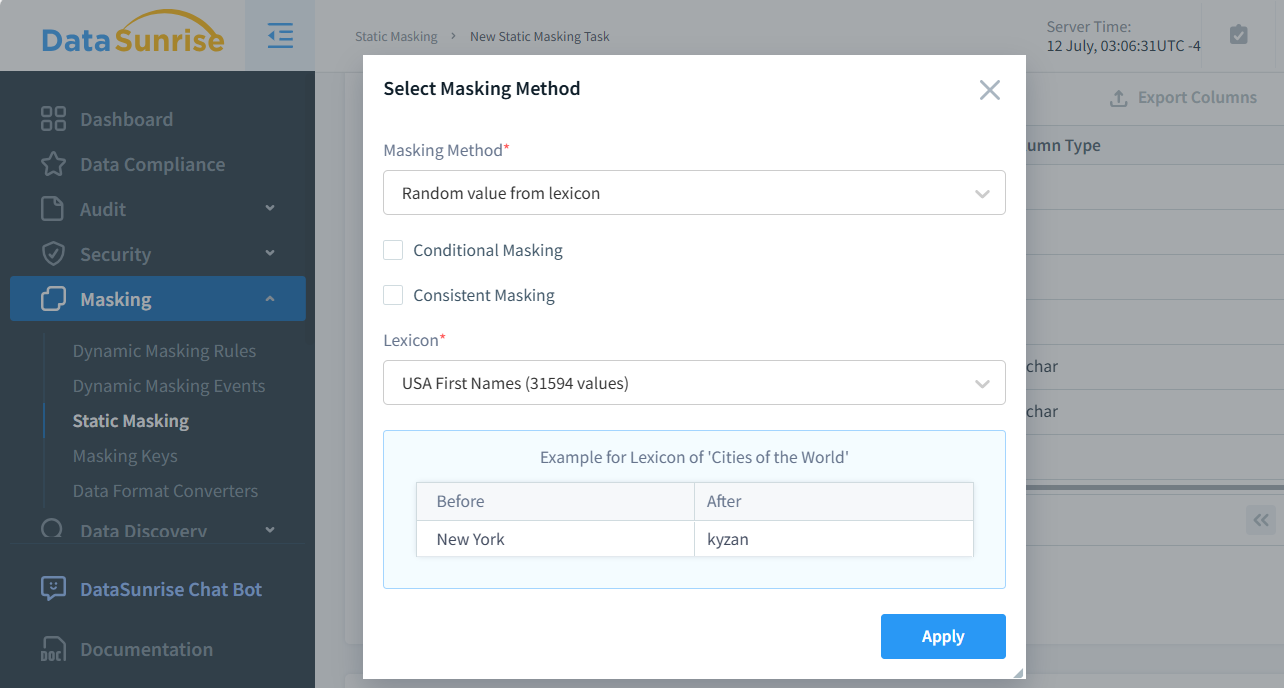
Come menzionato nell’Introduzione, DataSunrise consente di creare lessici basati su selezione casuale di valori per il masking. La figura seguente mostra la selezione di questo metodo di masking nell’interfaccia utente di DataSunrise. Come puoi vedere, sono disponibili 31.594 valori, che è molto più affidabile rispetto a semplicemente riorganizzare un determinato set. Questa affidabilità aumentata è dovuta al fatto che, quando ci sono n valori unici in una colonna, la probabilità che un singolo valore venga mappato a se stesso è 1/n.
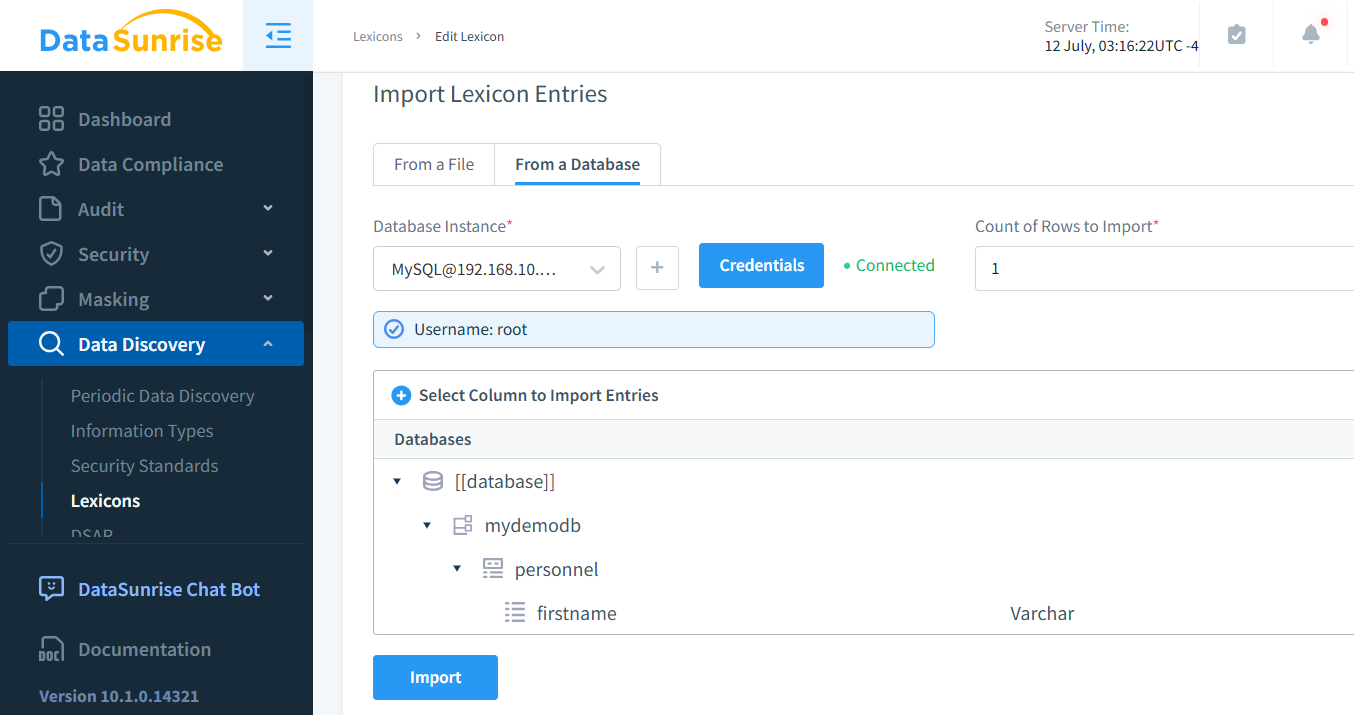
Se preferisci mappare con valori esistenti, puoi facilmente farlo creando un lessico personalizzato. Questo approccio è particolarmente vantaggioso in situazioni in cui i valori riorganizzati non sono nomi americani, poiché consente un data masking più contestualmente appropriato.
Come Funziona il Name Shuffling?
Il processo è semplice:
- Selezionare una colonna contenente nomi (nomi di battesimo, cognomi o entrambi).
- Riorganizzare casualmente i valori all’interno di quella colonna.
- Sostituire i valori originali con quelli riorganizzati.
Questa tecnica preserva la distribuzione e le caratteristiche dei dati originali. Tuttavia, interrompe la connessione tra individui e le loro informazioni.
Implementare il Name Shuffling in R e Python
Esploriamo come implementare il name shuffling più semplice in due popolari linguaggi di programmazione: Python e R.
È importante notare che il livello di usabilità offerto da DataSunrise è impareggiabile in questo contesto. Creare una soluzione flessibile e all-in-one con solo poche righe di codice non è fattibile utilizzando linguaggi di programmazione standard. Il nostro obiettivo qui è evidenziare le capacità di strumenti specializzati come DataSunrise rispetto ai linguaggi di programmazione generici.
Name Shuffling in Python
Python offre modi semplici ed efficienti per riorganizzare i dati. Ecco un esempio utilizzando pandas, una potente libreria per la manipolazione dei dati:
import pandas as pd
import numpy as np
# Creare un dataset di esempio
data = pd.DataFrame({
'FirstName': ['John', 'Alice', 'Bob', 'Emma', 'David'],
'LastName': ['Smith', 'Johnson', 'Williams', 'Brown', 'Jones'],
'Age': [32, 28, 45, 36, 51],
'Salary': [50000, 60000, 75000, 65000, 80000]
})
# Riorganizzare la colonna FirstName
data['FirstName'] = np.random.permutation(data['FirstName'])
# Riorganizzare la colonna LastName
data['LastName'] = np.random.permutation(data['LastName'])
print(data)Questo script crea un dataset di esempio e riorganizza le colonne FirstName e LastName. Il risultato mantiene i nomi originali ma ne randomizza l’ordine, mascherando efficacemente le identità individuali.
Name Shuffling in R
R fornisce anche metodi semplici per lo shuffling dei dati. Ecco un esempio:
# Creare un dataset di esempio
data <- data.frame(
FirstName = c("John", "Alice", "Bob", "Emma", "David"),
LastName = c("Smith", "Johnson", "Williams", "Brown", "Jones"),
Age = c(32, 28, 45, 36, 51),
Salary = c(50000, 60000, 75000, 65000, 80000)
)
# Riorganizzare la colonna FirstName
data$FirstName <- sample(data$FirstName)
# Riorganizzare la colonna LastName
data$LastName <- sample(data$LastName)
print(data)Questo script in R ottiene lo stesso risultato dell’esempio in Python. Riorganizza le colonne FirstName e LastName, mantenendo l’integrità dei dati mentre maschera le identità individuali.
Benefici del Name Shuffling
Il name shuffling offre diversi vantaggi:
- Mantiene Realismo dei Dati: I dati riorganizzati conservano le caratteristiche del dataset originale.
- Preserva la Distribuzione dei Dati: La frequenza dei nomi rimane la stessa, utile per l’analisi statistica.
- Implementazione Semplice: È facile da applicare e capire.
- Reversibile: Se necessario, il processo può essere invertito con la chiave giusta.
Sfide e Considerazioni
Sebbene il name shuffling sia efficace, è importante considerare:
- Unicità: Nomi rari potrebbero essere ancora identificabili.
- Consistenza: Assicurarsi che lo shuffling sia consistente tra tabelle correlate.
- Informazioni Contestuali: Altri campi di dati potrebbero ancora rivelare identità.
Migliori Pratiche per il Name Shuffling
Per massimizzare l’efficacia del name shuffling:
- Utilizzare Grandi Dataset: Più grande è il dataset, più efficace sarà lo shuffling.
- Combinare Tecniche: Utilizzare il name shuffling insieme ad altri metodi di masking per una protezione migliore.
- Applicazione Consistente: Applicare lo shuffling in modo consistente su tutti i dati correlati.
- Aggiornamenti Regolari: Riorganizzare periodicamente i dati per prevenire il reverse engineering.
Utilizzo del Name Shuffling nella Creazione di Dati di Test
Il name shuffling è particolarmente prezioso nella creazione di dati di test. Permette a sviluppatori e tester di lavorare con dati realistici senza compromettere la privacy. Ecco perché è cruciale:
- Test Realistici: I nomi riorganizzati mantengono le caratteristiche dei dati reali.
- Conformità alla Privacy: Aiuta a rispettare le regolamentazioni sulla protezione dei dati.
- Sviluppo Semplificato: Gli sviluppatori possono utilizzare dati che imitano da vicino gli ambienti di produzione.
Conclusione
Il name shuffling è una potente tecnica di data masking. Offre un equilibrio tra l’utilità dei dati e la protezione della privacy. Implementando il name shuffling, le organizzazioni possono creare dati di test realistici mentre proteggono le informazioni sensibili. Con l’aumento delle preoccupazioni sulla privacy dei dati, metodi come lo shuffling diventeranno sempre più importanti nella gestione dei dati.
Per coloro che cercano soluzioni avanzate di data masking, DataSunrise offre strumenti user-friendly e flessibili per la sicurezza del database. Il nostro mascheramento dinamico dei dati e statico include robuste capacità di shuffling e di crittografia. Visita il sito web di DataSunrise per una demo online ed esplora come le nostre soluzioni possano migliorare le tue strategie di protezione dei dati.
