
Semplificazione del Flusso di Lavoro dei Dati
Per aziende data-driven, un’elaborazione efficiente dei dati è cruciale per ottenere insight e prendere decisioni informate. Tuttavia, quando si gestiscono informazioni sensibili, è essenziale bilanciare velocità ed efficienza con la privacy e la sicurezza dei dati. Questo articolo esamina modi per semplificare i flussi di lavoro dei dati usando metodi ETL ed ELT, proteggendo al contempo la privacy dei dati.
Capire gli Approcci di Semplificazione del Processo dei Dati
Prima di approfondire ETL ed ELT, esaminiamo gli approcci comuni di semplificazione del processo dei dati:
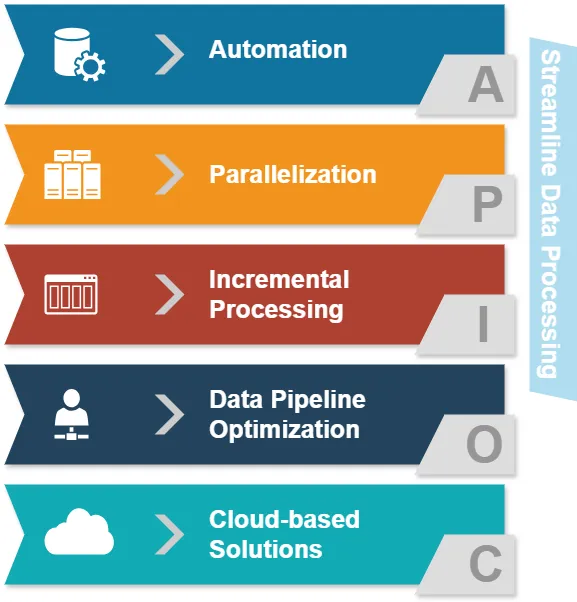
- Automazione: Riduzione delle interventi manuali nei compiti di elaborazione dei dati.
- Parallelizzazione: Elaborazione simultanea di più flussi di dati.
- Elaborazione incrementale: Aggiornamento solo dei dati modificati anziché di interi dataset.
- Ottimizzazione della pipeline dei dati: Assicurare un flusso di dati fluido tra le diverse fasi.
- Soluzioni basate su Cloud: Sfruttare un’infrastruttura scalabile per l’elaborazione dei dati.
Questi approcci mirano a migliorare l’efficienza dell’elaborazione dei dati. Ora esploriamo come ETL ed ELT si inseriscono in questo contesto.
Confronto Sintetico tra ETL ed ELT
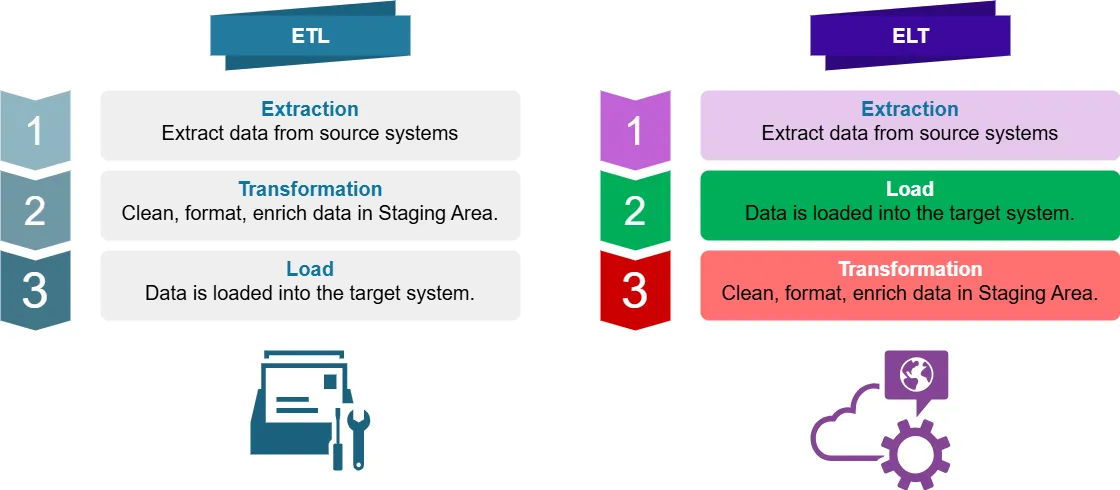
Che Cos’è ETL?
ETL sta per Extract, Transform, Load. È un processo tradizionale di integrazione dei dati dove i dati vengono:
- Estratti dai sistemi di origine dei dati
- Trasformati (puliti, formattati, arricchiti) in un’area di staging
- Caricati nel sistema di destinazione (es. data warehouse)
Che Cos’è ELT?
ELT sta per Extract, Load, Transform. È un approccio moderno in cui i dati vengono:
- Estratti dai sistemi di origine
- Caricati direttamente nel sistema di destinazione
- Trasformati all’interno del sistema di destinazione
Le Principali Differenze nell’Ottimizzazione dell’Elaborazione dei Dati
Per l’intelligence aziendale, la principale differenza tra ETL ed ELT risiede nel luogo e nel momento in cui avviene la trasformazione dei dati. Questo influisce sull’ottimizzazione dell’elaborazione dei dati in diversi modi:
- Potenza di elaborazione: ETL si affida a server di trasformazione separati, mentre ELT sfrutta la potenza del sistema di destinazione.
- Flessibilità dei dati: ELT preserva i dati grezzi, permettendo trasformazioni più agili.
- Tempo di elaborazione: ELT può essere più veloce per grandi dataset grazie alle capacità di elaborazione parallela.
- Privacy dei dati: ETL può offrire un maggiore controllo sui dati sensibili durante la fase di trasformazione.
Applicazioni di ETL e ELT
ETL è comunemente utilizzato in:
- Data warehousing tradizionale
- Sistemi con capacità di archiviazione o elaborazione limitate
- Scenari che richiedono complesse trasformazioni dei dati prima del caricamento
ELT è spesso preferito per:
- Data warehouse basati su Cloud
- Ambienti Big Data
- Elaborazione dati in tempo reale o quasi reale
- Situazioni in cui la preservazione dei dati grezzi è cruciale
Semplificazione dei Flussi di Lavoro dei Dati: Esempi con Python e Pandas
Esaminiamo alcuni esempi di elaborazione dei dati semplificata e non, utilizzando Python e Pandas.
Approccio Non Semplificato
import pandas as pd
# Lettura dei dati da CSV
df = pd.read_csv('large_dataset.csv')
# Esecuzione di trasformazioni multiple
df['new_column'] = df['column_a'] + df['column_b']
df = df[df['category'] == 'important']
df['date'] = pd.to_datetime(df['date'])
# Scrittura dei dati trasformati in un nuovo CSV
df.to_csv('transformed_data.csv', index=False)Questo approccio legge l’intero dataset in memoria, esegue le trasformazioni, e poi scrive il risultato. Per grandi dataset, questo può essere molto dispendioso in termini di memoria e lento.
Approccio Semplificato
import pandas as pd
# Utilizzo dei chunk per elaborare grandi dataset
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
# Esecuzione delle trasformazioni su ciascun chunk
chunk['new_column'] = chunk['column_a'] + chunk['column_b']
chunk = chunk[chunk['category'] == 'important']
chunk['date'] = pd.to_datetime(chunk['date'])
# Aggiunta del chunk trasformato al file di output
chunk.to_csv('transformed_data.csv', mode='a', header=False, index=False)Questo approccio semplificato elabora i dati a piccoli pezzi (chunks), riducendo l’uso della memoria e consentendo l’elaborazione parallela. È più efficiente per grandi dataset e può essere facilmente integrato in flussi di lavoro ETL o ELT.
Privacy dei Dati con ETL ed ELT
Quando si gestiscono dati sensibili, la privacy è fondamentale. Sia ETL che ELT possono essere progettati per gestire in modo sicuro le informazioni sensibili:
ETL e Privacy dei Dati
- Mascheramento dei dati: Applicare tecniche di mascheramento durante la fase di trasformazione.
- Crittografia: Crittografare i dati sensibili prima di caricarli nel sistema di destinazione.
- Controllo degli accessi: Implementare controlli rigorosi sugli accessi al server di trasformazione.
Esempio di mascheramento dei dati in ETL:
import pandas as pd
def mask_sensitive_data(df):
df['email'] = df['email'].apply(lambda x: x.split('@')[0][:3] + '***@' + x.split('@')[1])
df['phone'] = df['phone'].apply(lambda x: '***-***-' + x[-4:])
return df
# Processo ETL
df = pd.read_csv('source_data.csv')
df = mask_sensitive_data(df)
# Ulteriori trasformazioni...
df.to_csv('masked_data.csv', index=False)ELT e Privacy dei Dati
- Crittografia a livello di colonna: Crittografare le colonne sensibili prima del caricamento.
- Mascheramento dinamico dei dati: Applicare regole di mascheramento nel sistema di destinazione.
- Controllo degli accessi basato sui ruoli: Implementare politiche di accesso granulare nel data warehouse.
Esempio di crittografia a livello di colonna in ELT:
import pandas as pd
from cryptography.fernet import Fernet
def encrypt_column(df, column_name, key):
f = Fernet(key)
df[column_name] = df[column_name].apply(lambda x: f.encrypt(x.encode()).decode())
return df
# Generare una chiave di crittografia (nella pratica, conservare e gestire questa chiave in modo sicuro)
key = Fernet.generate_key()
# Processo ELT
df = pd.read_csv('source_data.csv')
df = encrypt_column(df, 'sensitive_column', key)
# Caricare i dati nel sistema di destinazione
df.to_sql('target_table', engine) # Supponendo che 'engine' sia la connessione al database
# Trasformare i dati all'interno del sistema di destinazioneOttimizzazione dei Flussi di Lavoro per Dati Sensibili
Per semplificare i flussi di lavoro dei dati mantenendo la privacy dei dati, considerare queste best practice:
- Classificazione dei dati: Identificare e categorizzare i dati sensibili all’inizio del processo.
- Minimizzare i movimenti dei dati: Ridurre il numero di volte in cui i dati sensibili vengono trasferiti tra i sistemi.
- Utilizzare protocolli sicuri: Impiegare crittografia per i dati in transito e a riposo.
- Implementare la governance dei dati: Stabilire politiche chiare per la gestione e l’accesso ai dati.
- Audit regolari: Condurre revisioni periodiche dei flussi di lavoro di elaborazione dei dati.
Conclusione
Semplificare i flussi di lavoro dei dati è importante. Dobbiamo anche garantire che le informazioni sensibili siano protette con misure di privacy solide. Entrambi gli approcci, ETL e ELT, hanno vantaggi unici e le organizzazioni possono ottimizzarli per prestazioni e sicurezza.
Questo articolo discute modi in cui le organizzazioni possono creare flussi di lavoro dei dati sicuri. Questi flussi di lavoro proteggono le informazioni sensibili e consentono di ottenere informazioni preziose. Le organizzazioni possono utilizzare strategie e best practice per raggiungere questo obiettivo.
Ricordati, la scelta tra ETL ed ELT dipende dal tuo caso d’uso specifico, dal volume di dati e dai requisiti di privacy. È importante rivedere e aggiornare regolarmente le tue strategie di elaborazione dei dati. Questo garantirà che esse siano in linea con le esigenze del tuo business in evoluzione e conformi alle leggi sulla protezione dei dati.
Per strumenti facili da usare che migliorano la sicurezza e la conformità dei database nei tuoi processi di dati, dai un’occhiata alle opzioni di DataSunrise. Visita il nostro sito web su DataSunrise per vedere una demo e scoprire come possiamo migliorare l’elaborazione dei tuoi dati. Prioritizziamo la sicurezza e la protezione dei tuoi dati.
