
Migliorare la Gestione dei Dati e le Prestazioni con la Suddivisione dei Dati
Introduzione
L’esplosione delle tecnologie digitali, dei dispositivi Internet of Things (IoT) e delle interazioni online ha creato enormi quantità di dati che possono essere raccolti e analizzati. Nel mondo data-driven di oggi, gestire grandi dataset in modo efficiente è cruciale per aziende e ricercatori. Una tecnica potente che ha guadagnato importanza negli ultimi anni è la suddivisione dei dati. Questo articolo approfondirà il mondo della suddivisione dei dati, esplorandone i fondamenti, i benefici e le applicazioni pratiche. Esploreremo anche alcuni strumenti open-source e forniremo esempi per aiutarti a iniziare con questa tecnica essenziale di gestione dei dati.
Che Cos’è la Suddivisione dei Dati?
La suddivisione dei dati è il processo di creazione di una porzione più piccola e più gestibile di un dataset più grande mantenendo le sue caratteristiche e relazioni chiave. Questa tecnica consente agli utenti di lavorare con un campione rappresentativo di dati, rendendo più semplice la gestione, l’analisi e il test senza compromettere l’integrità del dataset originale.
Perché Dovrebbe Interessarti la Suddivisione?
La suddivisione dei dati sta diventando sempre più cruciale nella nostra era dei big data. Ecco perché dovresti prestare attenzione a questa tecnica:
- Gestione di Dataset Enormi: I dataset moderni possono essere enormi. Ad esempio, una piattaforma di social media potrebbe generare petabyte di dati giornalieri. Lavorare con quantità così vaste di dati può essere impraticabile o impossibile senza la suddivisione.
- Ottimizzazione delle Risorse: Elaborare dataset completi richiede spesso risorse computazionali significative. La suddivisione consente di lavorare con una frazione dei dati, risparmiando tempo e riducendo i requisiti hardware.
- Riduzione dei Costi: I costi di cloud computing e storage sono direttamente legati al volume dei dati. Lavorando con subset, è possibile ridurre significativamente queste spese.
- Cicli di Sviluppo più Rapidi (test del software): Nello sviluppo software, utilizzare dataset di produzione completi per il testing può rallentare il processo di sviluppo. I subset consentono iterazioni più rapide e un’identificazione più veloce dei bug.
- Conformità alla Privacy dei Dati: Con regolamenti come GDPR e CCPA, utilizzare dataset completi con informazioni sensibili per il testing o l’analisi può essere rischioso. La suddivisione aiuta a creare dataset anonimizzati e conformi.
- Miglioramento della Qualità dei Dati: I dataset più piccoli sono più facili da pulire e convalidare, portando potenzialmente a dati di qualità superiore per le tue analisi o modelli.
Quanto Grandi Possono Essere i Dataset? Un Esempio Reale
Per comprendere la scala dei dataset moderni, consideriamo alcuni esempi:
- Data Warehouse di Walmart: Nel 2019, si stimava che il data warehouse di Walmart contenesse oltre 2,5 petabyte di dati. È l’equivalente di 167 volte tutti i libri nella Biblioteca del Congresso degli Stati Uniti.
- Dati Utente di Facebook: Facebook elabora oltre 500 terabyte di dati ogni giorno. Questo include post degli utenti, foto, video e dati di interazione.
- Large Hadron Collider di CERN: L’LHC genera enormi quantità di dati equivalenti a oltre 20.000 anni di registrazione video in HD 24/7.
- Dati Genomici: Il genoma umano consiste di circa 3 miliardi di paia di basi. Sequenziare e memorizzare questi dati per milioni di individui crea dataset nell’ordine dei petabyte.
- Scienza del Clima: Il Center for Climate Simulation (NCCS) della NASA gestisce oltre 32 petabyte di dati provenienti da varie missioni di scienze della Terra.
Per mettere tutto in prospettiva, 1 petabyte equivale a 20 milioni di schedari a quattro cassetti pieni di testo. Immagina ora di provare a analizzare o elaborare questa quantità di dati nella sua interezza – ed è qui che la suddivisione dei dati diventa inestimabile.
Ad esempio, se fossi un data scientist presso Walmart che cerca di analizzare il comportamento dei clienti, lavorare con l’intero dataset di 2,5 petabyte sarebbe impraticabile. Invece, potresti creare un subset di dati per un periodo di tempo specifico, una regione o una categoria di prodotto, forse riducendo il tuo dataset di lavoro a un più gestibile 50 gigabyte.
Perché la Suddivisione dei Dati è Utile?
La suddivisione dei dati offre numerosi vantaggi per i professionisti dei dati e le organizzazioni:
- Miglioramento delle Prestazioni: Lavorare con dataset più piccoli riduce il tempo di elaborazione e i requisiti delle risorse.
- Conveniente: La suddivisione può ridurre i costi di archiviazione e computazione associati ai big data.
- Testing Potenziato: Permette test più rapidi ed efficienti delle applicazioni data-driven.
- Conformità alla Privacy: La suddivisione aiuta a creare dataset anonimizzati per la conformità normativa.
- Analisi Semplificate: I dataset più piccoli sono più facili da esplorare e analizzare, soprattutto nelle fasi iniziali di un progetto.
Applicazioni Pratiche della Suddivisione
Esploriamo alcuni scenari reali in cui la suddivisione dei dati si dimostra inestimabile:
1. Sviluppo e Test del Software
Spesso gli sviluppatori devono lavorare con dati realistici per testare le applicazioni. Tuttavia, l’uso di dataset di produzione completi può essere impraticabile e rischioso. La suddivisione consente la creazione di dataset di test più piccoli e rappresentativi che mantengono la complessità dei dati del mondo reale senza esporre informazioni sensibili.
2. Analisi ed Esplorazione dei Dati
Quando si tratta di dataset enormi, l’analisi esplorativa dei dati iniziale può richiedere tempo. Creando un subset, gli analisti possono ottenere rapidamente idee e testare ipotesi prima di scalarle al dataset completo.
3. Sviluppo di Modelli di Machine Learning
Durante le prime fasi di sviluppo del modello, i data scientist possono usare subset per iterare rapidamente su diversi algoritmi e iperparametri prima di addestrare il modello sul dataset completo.
4. Ottimizzazione dei Database
Amministratori di database possono usare la suddivisione per creare versioni più piccole dei database di produzione per ambienti di sviluppo e test, garantendo prestazioni ottimali senza il sovraccarico di gestire repliche a grandezza naturale.
Strumenti e Tecniche per la Suddivisione dei Dati
Ora che comprendiamo l’importanza della suddivisione dei dati, diamo un’occhiata a alcuni strumenti e tecniche popolari per implementarla efficacemente.
SQL per la Suddivisione dei Dati
SQL è un linguaggio potente per la manipolazione dei dati e ottimo per la suddivisione di database relazionali. Ecco un esempio di come creare un subset di dati utilizzando SQL:
-- Creare un subset di dati dei clienti per l'anno 2023 CREATE TABLE customer_subset_2023 AS SELECT * FROM customers WHERE EXTRACT(YEAR FROM order_date) = 2023 LIMIT 10000;
Questa query crea una nuova tabella customer_subset_2023 contenente fino a 10.000 record di clienti dall’anno 2023. Il risultato è un dataset più piccolo e gestibile per analisi o scopi di testing.
Python per la Suddivisione dei Dati
Con il suo ricco ecosistema di librerie di manipolazione dei dati, Python offre strumenti potenti per la suddivisione dei dati.
Dispone di un tipo di dati incorporato chiamato ‘set’, che è utile per memorizzare elementi unici e eseguire operazioni matematiche di set. Tuttavia, mentre i set sono efficienti per determinati compiti, generalmente non sono utilizzati per operazioni di big data. Per gestire grandi dataset in Python, librerie specializzate come pandas, NumPy, o PySpark sono più comunemente impiegate grazie alle loro prestazioni ottimizzate e capacità avanzate di manipolazione dei dati.
Vediamo un esempio utilizzando pandas:
import pandas as pd
import numpy as np
# Caricare il dataset completo
full_dataset = pd.read_csv('large_dataset.csv')
# Creare un subset basato su una condizione e campionamento casuale
subset = full_dataset[full_dataset['category'] == 'electronics'].sample(n=1000, random_state=42)
# Salvare il subset in un nuovo file CSV
subset.to_csv('electronics_subset.csv', index=False)Questo script carica un grande dataset, lo filtra per includere solo articoli elettronici, poi seleziona casualmente 1.000 righe per creare un subset. Il risultato viene salvato come un nuovo file CSV.
Inoltre, in Pandas puoi fare il filtraggio dei dati con affermazioni come la seguente:
filtered_df_loc = df.loc[df['age'] > 25, ['name', 'city']]
oppure
filtered_df = df[df['age'] > 25]
Filtraggio dei Dati Basato su Condizioni in R
R è un altro potente linguaggio per la manipolazione e l’analisi dei dati, ampiamente utilizzato nel computing statistico e nella data science. Mentre Python è spesso preferito per il deep learning, R ha capacità forti nel machine learning tradizionale e nell’apprendimento statistico. Questo può essere vantaggioso quando la tua suddivisione dei dati coinvolge approcci basati su modelli o quando devi analizzare le proprietà statistiche dei tuoi subset.
Puoi eseguire questo codice nella versione Posit Cloud di RStudio con un account gratuito.
# Caricare la libreria necessaria
library(dplyr)
# Supponiamo di avere un grande dataset chiamato 'full_dataset'
# Per questo esempio, creeremo un dataset di esempio
set.seed(123) # per la riproducibilità
full_dataset <- data.frame(
id = 1:1000,
category = sample(c("A", "B", "C"), 1000, replace = TRUE),
value = rnorm(1000)
)
# Creare un subset basato su una condizione e campionamento casuale
subset_data <- full_dataset %>%
filter(category == "A") %>%
sample_n(100)
# Visualizzare le prime righe del subset
head(subset_data)
# Salvare il subset in un file CSV
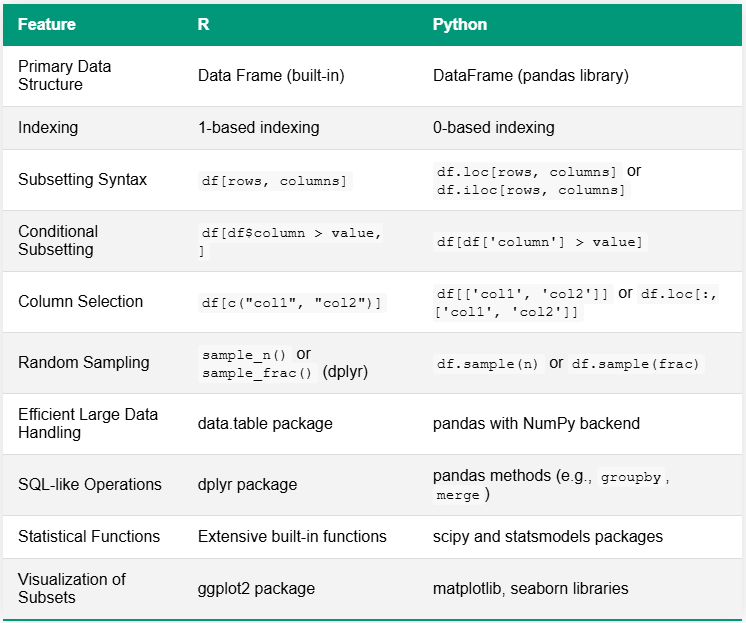
write.csv(subset_data, "category_A_subset.csv", row.names = FALSE)La tabella seguente confronta R e Python per i compiti di suddivisione dei dati, evidenziando le differenze chiave nella sintassi e nella funzionalità. Una distinzione notevole risiede nei loro ecosistemi: R ha spesso funzioni incorporate o si affida a pochi pacchetti completi, mentre Python utilizza tipicamente una varietà di librerie specializzate per capacità simili.
Strumenti Open-Source per la Suddivisione dei Dati
Sono disponibili diversi strumenti open-source per esigenze più avanzate:
- Jailer: Uno strumento di suddivisione dei database che preserva l’integrità referenziale.
- Benerator CE: Un framework open-source per generare e suddividere dati di test.
- Subsetter: Una libreria Python per la suddivisione dei database relazionali mantenendo l’integrità referenziale.
Questi strumenti offrono caratteristiche più sofisticate come il mantenimento di relazioni complesse tra le tabelle e la generazione di dati sintetici per completare i subset.
Best Practices per una Suddivisione dei Dati Efficace
Per sfruttare al meglio la suddivisione dei dati, considera queste best practices:
- Mantenere l’Integrità dei Dati: Assicurati che il tuo subset mantenga le relazioni e i vincoli del dataset originale.
- Usare Campioni Rappresentativi: Cerca di creare subset che rappresentino accuratamente le caratteristiche del dataset completo.
- Considerare la Sensibilità dei Dati: Quando suddividi per test o sviluppo, sii consapevole delle informazioni sensibili e applica tecniche di anonimizzazione appropriate.
- Documentare il Processo: Tieni registri chiari di come sono stati creati i subset per garantire la riproducibilità.
- Convalidare i Subset: Controlla regolarmente che i tuoi subset rappresentino ancora accuratamente il dataset completo man mano che evolve nel tempo.
Le Sfide della Suddivisione dei Dati
Sebbene l’elaborazione dei dati offra molti benefici, non è priva di sfide:
- Mantenimento delle Relazioni dei Dati: In database complessi, preservare l’integrità referenziale può essere difficile.
- Garantire Campioni Rappresentativi: Creare subset che rappresentino accuratamente tutti gli aspetti del dataset completo può essere impegnativo.
- Gestione dei Dati Temporali: Suddividere i dati temporali mantenendo i modelli temporali richiede considerazioni attente.
- Scala con i Big Data: Man mano che i dataset crescono, anche creare subset può diventare intensivo dal punto di vista computazionale.
Conclusione
La suddivisione dei dati è una tecnica potente che può migliorare significativamente le tue pratiche di gestione dei dati. Creando dataset più piccoli e gestibili, puoi migliorare le prestazioni, ridurre i costi e semplificare i tuoi processi di sviluppo e testing. Che tu stia utilizzando SQL, Python, o strumenti specializzati, padroneggiare la suddivisione dei dati è un’abilità essenziale per qualsiasi professionista dei dati.
Quando inizi il tuo viaggio nella suddivisione dei dati, ricorda che la chiave del successo risiede nel mantenimento dell’integrità dei dati, nel garantire rappresentatività e nella scelta degli strumenti giusti per le tue esigenze specifiche.
