
Tipi di Mascheramento dei Dati: Come Proteggere i Dati Sensibili

Proteggere i dati sensibili è fondamentale per qualsiasi organizzazione. Il mascheramento dei dati emerge come una tecnica cruciale per garantire la privacy e la sicurezza dei dati. Questo articolo analizza i vari tipi di mascheramento dei dati, spiegandone le applicazioni e le differenze. Comprendendo questi metodi, le aziende possono meglio proteggere le loro informazioni critiche dall’accesso non autorizzato.
Il mascheramento dei dati consiste nella creazione di una versione fittizia dei dati di un’azienda per mantenere al sicuro le informazioni importanti. Questa tecnica è cruciale per conformarsi alle leggi sulla privacy e proteggere i dati negli ambienti che richiedono test e analisi.
Tipi di Mascheramento dei Dati
Mascheramento Statico dei Dati (SDM)
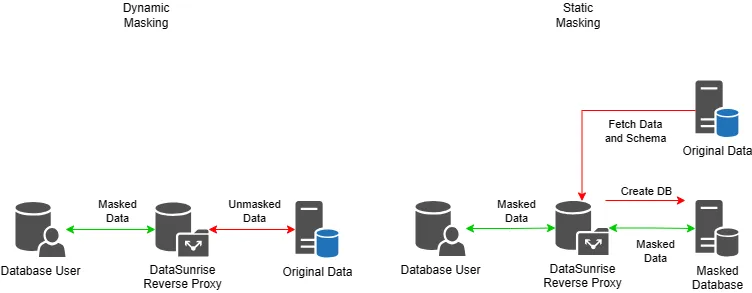
Il Mascheramento Statico dei Dati prevede la creazione di una copia dei dati e l’applicazione di tecniche di trasformazione per mascherare le informazioni sensibili. Questa copia sostituisce poi i dati originali negli ambienti non di produzione. I dati rimangono sicuri anche se l’ambiente è compromesso perché vengono trasformati prima di lasciare il database.
Esempio di Mascheramento Statico dei Dati: Immagina un database sanitario con i record dei pazienti. Prima di utilizzare questi dati per i test software, un processo di mascheramento statico sostituisce tutti i nomi e gli ID dei pazienti con voci fittizie ma realistiche. La struttura e il formato dei dati rimarranno gli stessi, quindi le applicazioni possono funzionare normalmente senza rivelare i dati effettivi dei pazienti.
Mascheramento Dinamico dei Dati (DDM)
Il sistema applica il Mascheramento Dinamico dei Dati in tempo reale mentre elabora le richieste di dati. A differenza dell’SDM, non crea una copia fisica dei dati. Quando si interroga il database, il sistema applica le regole di mascheramento dei dati per assicurarsi che i dati originali nel database rimangano inalterati.
Esempio di Mascheramento Dinamico dei Dati: Un analista finanziario interroga un database contenente i record finanziari dei clienti. Il DDM nasconde automaticamente i numeri di conto e i saldi nei risultati delle query. Questo garantisce che gli analisti possano vedere solo le informazioni necessarie per la loro analisi, prevenendo l’esposizione di dati sensibili.
Mascheramento dei Dati in Loco
Sebbene non sia un tipo di mascheramento autonomo, il mascheramento in loco merita menzione come caso eccezionale per il mascheramento statico. Il mascheramento in loco si verifica quando il database di produzione sorgente e il database mascherato di destinazione sono lo stesso. Ciò significa che parti sensibili dei dati esistenti vengono intenzionalmente rimosse o mascherate. Questa procedura comporta rischi e dovrebbe essere tentata solo se l’amministratore del database è sicuro del risultato finale.
Quando Avviene il Mascheramento?
- Il Mascheramento Statico dei Dati maschera i dati prima di spostarli in un ambiente non di produzione.
- Il Mascheramento Dinamico dei Dati avviene in tempo reale, durante il recupero dei dati.
Natura Delle Modifiche Dei Dati nel Mascheramento
Il mascheramento dei dati può essere reversibile o irreversibile a seconda del metodo utilizzato:
- Mascheramento Reversibile: È spesso utilizzato quando è necessario tornare ai dati originali, tipicamente in condizioni sicure.
- Mascheramento Irreversibile: Questo metodo è utilizzato quando non è necessario accedere ai dati originali di nuovo, migliorando la sicurezza.
Si noti che software dedicati come DataSunrise non cambiano i dati a riposo per il mascheramento dinamico dei dati. Questo tipo di mascheramento funziona in modalità reverse proxy. Invece del database reale, le query al database vengono elaborate dal proxy di DataSunrise. Il software lato utente funziona con la connessione al database come al solito.
Nel caso del mascheramento statico, DataSunrise copia i dati in un database diverso per impostazione predefinita. Questo minimizza il rischio di perdita di dati.
Metodi di Mascheramento
Questi non sono tipi di mascheramento ma è necessario prestare attenzione ai metodi di mascheramento in alcune situazioni. I dati fittizi devono imitare il formato non solo per depistare l’attaccante. Questo è anche un modo per supportare i vecchi software sensibili al formato dei dati.
Sostituzione
La sostituzione prevede la sostituzione dei dati originali con valori fittizi ma realistici. È necessario generare dati fittizi in anticipo. Questa tecnica mantiene il formato e la struttura dei dati assicurando che i valori mascherati non siano reversibili. Esempio:
Dati Originali: John Doe Dati Mascherati: James Smith
Rimescolamento
Il rimescolamento riorganizza i valori all’interno di una colonna, rompendo la relazione tra i dati mascherati e i dati originali. Questa tecnica è utile quando è necessario mantenere la distribuzione e l’unicità dei dati. Esempio:
Dati Originali: John Doe, Jane Smith, Alice Johnson Dati Mascherati: Alice Johnson, John Doe, Jane Smith
Crittografia
La crittografia prevede la conversione dei dati originali in un formato illeggibile utilizzando un algoritmo crittografico e una chiave segreta. È possibile decifrare i dati mascherati solo con la chiave corrispondente, rendendoli reversibili. La crittografia è comunemente usata quando è necessario recuperare i dati originali. Esempio:
Dati Originali: John Doe Dati Mascherati: Xk9fTm1pR2w=
Tokenizzazione
La tokenizzazione sostituisce i dati sensibili con un token unico, generato casualmente. Il sistema conserva in modo sicuro i dati originali in una cassaforte di token. Il token serve come riferimento per recuperare i dati quando necessario.
Le aziende utilizzano comunemente la tokenizzazione per proteggere i numeri di carta di credito e altri dati finanziari sensibili. Esempio:
Dati Originali: 1234-5678-9012-3456 Dati Mascherati: TOKEN1234
Nell’immagine sottostante potete vedere la selezione dei metodi di mascheramento in DataSunrise. Questo appare quando si crea una regola di Mascheramento Dinamico utilizzando l’interfaccia Web-based di DataSunrise. I metodi di mascheramento disponibili possono variare attraverso ‘Stringa Vuota’ fino a formati più avanzati ‘FF3 Encryptions’.
Mascheramento con Strumenti Nativi DBMS: Pro e Contro
I sistemi di gestione dei database (DBMS) spesso forniscono strumenti nativi, come viste e stored procedure. Possono essere utilizzati per implementare il mascheramento dei dati. Sebbene questi strumenti offrano alcuni vantaggi, presentano anche limitazioni rispetto alle soluzioni di mascheramento dedicate. Esploriamo i pro e i contro dell’utilizzo degli strumenti nativi DBMS per creare il mascheramento.
Pro
Familiarità: Gli amministratori di database (DBA) e gli sviluppatori sono spesso ben esperti nell’uso degli strumenti nativi DBMS. Questa familiarità può rendere più facile per loro implementare il mascheramento utilizzando questi strumenti senza richiedere formazione aggiuntiva.
Integrazione: Il sistema di database integra nativamente gli strumenti DBMS. Ciò consente un’interazione fluida con i dati. Questa integrazione può semplificare il processo di implementazione e garantire la compatibilità con le operazioni di database esistenti.
Prestazioni: È possibile eseguire viste e stored procedure direttamente all’interno del motore del database. Ciò fornisce migliori prestazioni rispetto alle soluzioni di mascheramento esterne. Questo è particolarmente utile quando si trattano grandi dataset o regole di mascheramento complesse.
Contro
Funzionalità Limitata: Gli strumenti nativi DBMS potrebbero non offrire lo stesso livello di funzionalità delle soluzioni di mascheramento dedicate. Possono mancare di tecniche di mascheramento avanzate come la crittografia che preserva il formato o il mascheramento condizionale. Questo può limitare l’efficacia del processo di mascheramento.
Manutenzione Impegnativa: Implementare il mascheramento utilizzando viste e stored procedure richiede sviluppo personalizzato e manutenzione continua. Man mano che lo schema del database evolve, è necessario aggiornare le viste e le stored procedure di conseguenza. Questo può essere dispendioso in termini di tempo e soggetto a errori, soprattutto in ambienti di database complessi.
Sfide di Scalabilità: Quando si utilizzano strumenti nativi DBMS per il mascheramento, la logica del mascheramento è strettamente legata allo schema del database. Scalare la soluzione di mascheramento su più database o adattarsi ai cambiamenti nella struttura dei dati può essere difficile. Le soluzioni di mascheramento dedicate spesso offrono maggiore flessibilità e scalabilità nella gestione di fonti di dati diverse e requisiti in evoluzione.
Problemi di Sicurezza: Le viste e le stored procedure fanno parte del sistema di database. Gli utenti con privilegi appropriati possono accedervi. Se non sono adeguatamente sicure, c’è il rischio di accesso non autorizzato alla logica di mascheramento o ai dati non mascherati. Le soluzioni di mascheramento dedicate spesso forniscono misure di sicurezza aggiuntive e controlli di accesso per mitigare questi rischi.
Coerenza e Standardizzazione: Affidandosi agli strumenti nativi DBMS, l’implementazione del mascheramento può variare tra differenti database e team. Questa mancanza di coerenza può portare a disparità nei dati mascherati e rendere difficile mantenere un approccio standardizzato al mascheramento in tutta l’organizzazione. Le soluzioni di mascheramento dedicate offrono un approccio centralizzato e coerente al mascheramento, garantendo uniformità e conformità alle politiche di protezione dei dati.
Creare Regole di Mascheramento in DataSunrise
Per implementare il mascheramento dei dati con DataSunrise, è possibile utilizzare l’interfaccia GUI Web-based o la Command Line Interface (CLI).
Esempio di utilizzo della CLI per una regola di mascheramento dinamico (singola linea):
executecommand.bat addMaskRule -name script-rules -instance aurora -login aurorauser -password aurorauser -dbType aurora -maskType fixedStr -fixedVal XXXXXXXX -action mask -maskColumns 'test.table1.column2;test.table1.column1;'
Questo comando crea una regola di mascheramento chiamata “script-rules” che sostituisce i valori nelle colonne “test.table1.column2” e “test.table1.column1” della tabella “table1”. Vedere la Guida CLI di DataSunrise per ulteriori dettagli.
Conclusione e Sommario
Il mascheramento dei dati è una misura di sicurezza vitale che aiuta le organizzazioni a proteggere le informazioni sensibili. Comprendere i diversi tipi di mascheramento dei dati e quando utilizzarli può migliorare significativamente la strategia di sicurezza dei dati. Il Mascheramento Statico e Dinamico dei Dati hanno entrambi un ruolo a seconda della sensibilità dei dati.
Sebbene gli strumenti nativi DBMS come viste e stored procedure possano essere utilizzati per creare il mascheramento, presentano limitazioni rispetto alle soluzioni di mascheramento dedicate. Le organizzazioni dovrebbero valutare attentamente i propri requisiti di mascheramento, considerando fattori come funzionalità, scalabilità, sicurezza e manutenibilità, prima di decidere sull’approccio appropriato.
Le soluzioni di mascheramento dedicate, come DataSunrise, offrono funzionalità complete, flessibilità e facilità d’uso. Questo le rende una scelta preferita per le organizzazioni che cercano di implementare pratiche di mascheramento dei dati robuste e affidabili. DataSunrise fornisce una vasta gamma di tecniche di mascheramento, supporta più database e offre una console di gestione centralizzata Web-based per definire e applicare le regole di mascheramento in maniera coerente in tutta l’azienda.
Unisciti al nostro team per una dimostrazione online per vedere come le nostre soluzioni possono proteggere efficacemente i tuoi dati.
Nota su DataSunrise: Gli strumenti eccezionali e flessibili di DataSunrise non solo forniscono una solida sicurezza, ma garantiscono anche conformità e gestione efficiente dei dati. Unisciti a noi per una demo online per esplorare come possiamo assistere nella protezione dei tuoi beni informativi.
