Guida Completa su Come Cercare Dati Sensibili nelle Immagini Ospitate su AWS S3
Per fornire ai nostri clienti un potente strumento di scoperta dei dati, tempo fa abbiamo presentato la funzionalità OCR (Optical Character Recognition) integrata nel nostro modulo Data Discovery. Questa funzionalità consente di cercare dati sensibili come dati personali, numeri di carte di credito, patenti di guida, ecc. contenuti nei file di immagini. Il processo di scoperta viene eseguito automaticamente senza bisogno di alcun intervento umano. OCR Data Discovery funziona solo con AWS S3 per il momento.
L’OCR DD di DataSunrise è basato sul motore Tesseract che utilizza la tecnologia delle reti neurali per il riconoscimento dei caratteri. Tesseract utilizza la libreria Leptonica per leggere le immagini con uno dei seguenti formati:
- PNG
- JPEG
- TIFF
- JPEG 2000
- GIF
- WebP (inclusi WebP animati)
- BMP
- PNM
Come Funziona
Una volta avviato un task di OCR Data Discovery, il processo di scoperta passa attraverso le seguenti fasi:
- DataSunrise esamina i contenuti del bucket S3 specificato per le immagini.
- Il preprocessore del motore OCR prepara le immagini scoperte per ulteriori elaborazioni rendendole più contrastate e nitide.
- DataSunrise, con l’ausilio della tecnologia OCR di Tesseract, riconosce il testo non strutturato presente nelle immagini e applica algoritmi di Data Discovery in rispetto di tale testo secondo le impostazioni del Task di Data Discovery.
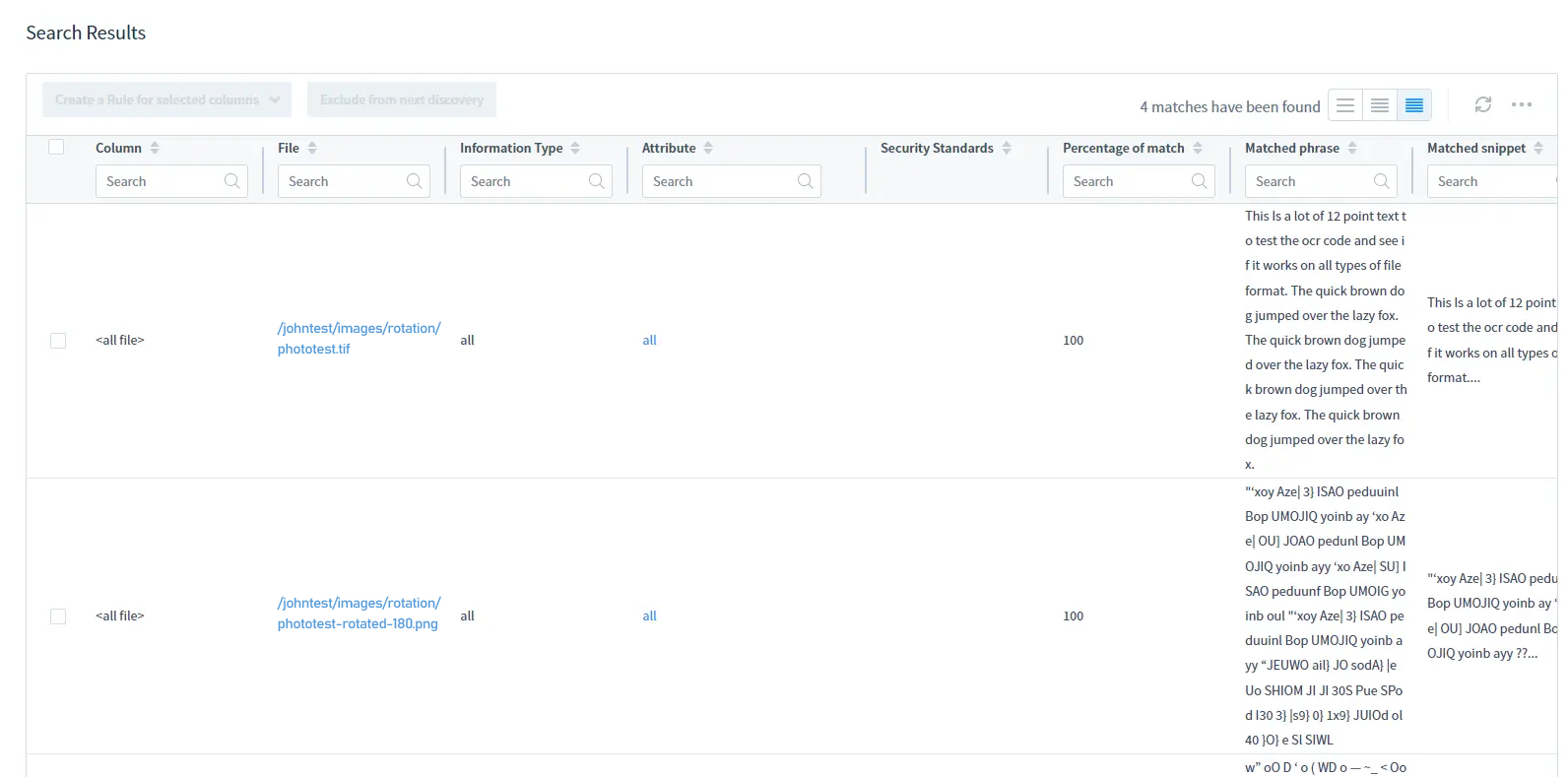
Come risultato, ottiene i nomi e la posizione dei file immagine che contengono dati sensibili e quei dati in un report DD.
Configurare un Task OCR in DataSunrise
Ora diamo uno sguardo al processo di creazione di un task OCR Data Discovery.
Innanzitutto, è importante notare che OCR Data Discovery con NLP Data Discovery richiede Java 1.8+
Per utilizzare OCR Data Discovery, è necessario seguire i seguenti passaggi:
- Prima di procedere al passaggio successivo, crea un’istanza S3 DB in DataSunrise (fare riferimento alla Guida utente di DataSunrise per i dettagli).
- Vai a Data Discovery → Periodic Data Discovery
- Crea un task di Data Discovery per il tuo bucket S3:
Compila le Impostazioni Generali:

- Nomina il task
- Seleziona il Server DS su cui avviare il task
- Se desidera eseguire Data Discovery per più istanze DB, seleziona la casella corrispondente e seleziona le istanze di interesse
- Seleziona la casella Genera Report per creare un report in formato PDF o CSV.
Nella sezione Parametri di Ricerca:
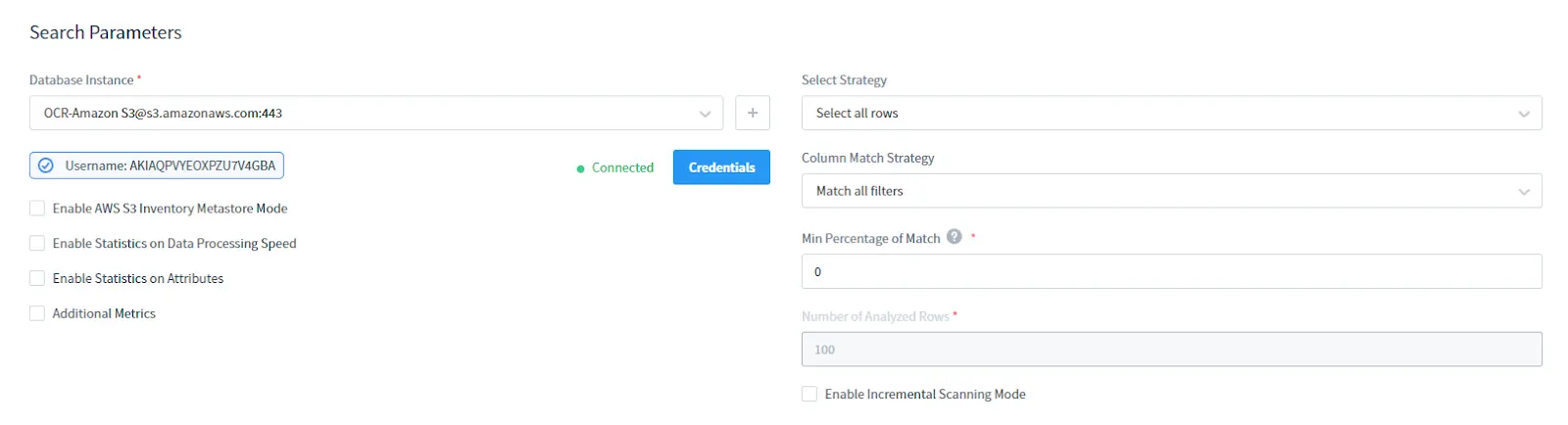
- Seleziona la tua istanza DB AWS S3. Fornisci le credenziali per il tuo S3
- Scegli la Strategia di Selezione: seleziona tutte le righe o solo le righe principali
- Seleziona la Strategia di Corrispondenza delle Colonne: tipo di filtraggio delle colonne
- Imposta la Percentuale Minima di Corrispondenza: è la percentuale minima di righe in una colonna che corrispondono alle condizioni del filtro di ricerca per considerare la colonna contenente i dati sensibili richiesti
- Seleziona il Numero di Righe Analizzate: numero di righe analizzate da scegliere come SELECTed
In Parametri di Multiprocessing:

Seleziona la Strategia di Esecuzione: singolo Server DS o più Server DS per il calcolo parallelo
Seleziona gli oggetti del DB attraverso cui cercare:

Utilizza l’albero degli oggetti per specificare gli oggetti che devono essere esaminati durante l’esecuzione del Task
Puoi escludere determinati oggetti dalla ricerca utilizzando l’albero degli oggetti corrispondente:

In Impostazioni di Ricerca:
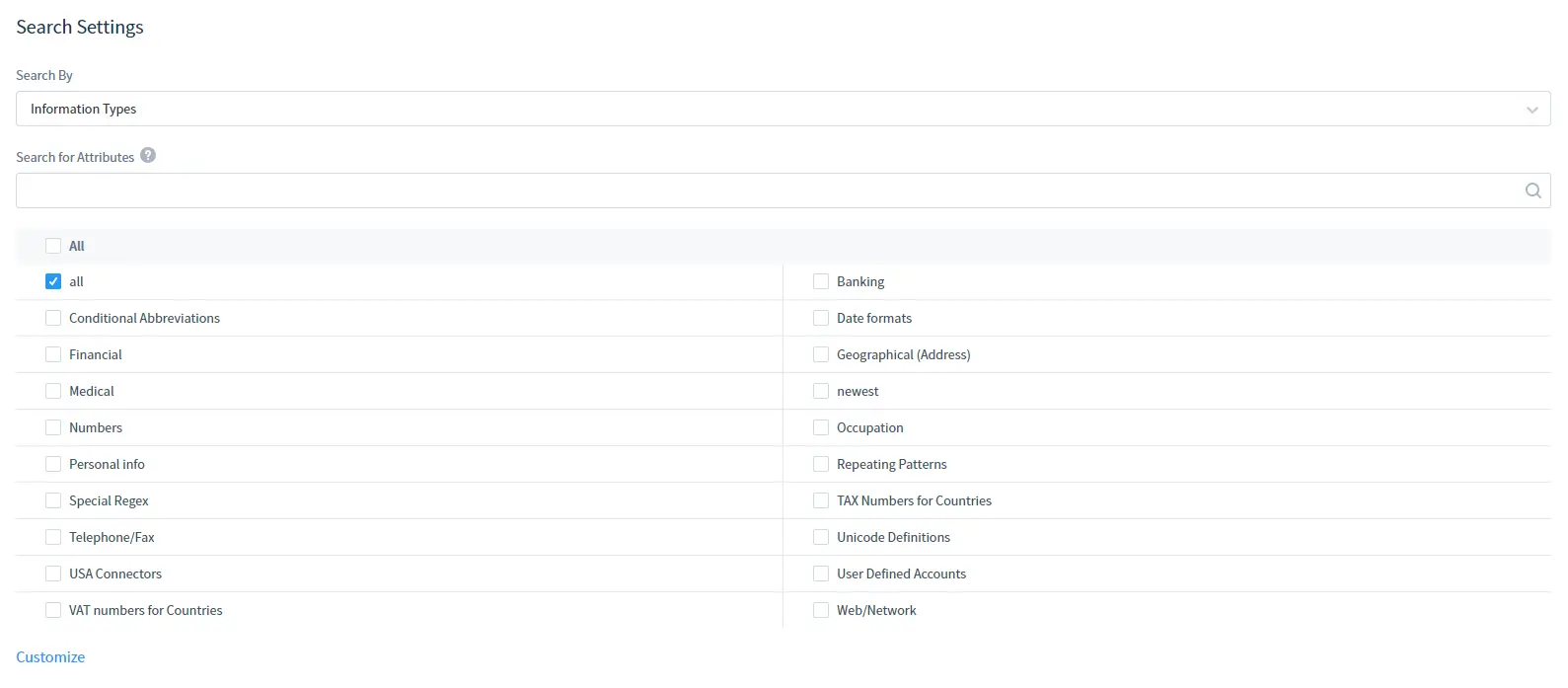
Seleziona il Tipo di Informazione o gli Standard di Sicurezza da ricercare. Nota che puoi anche utilizzare la Ricerca per Attributi per trovare un Tipo di Informazione o una Normativa di Sicurezza necessario per attributo.
In Frequenza di Avvio:
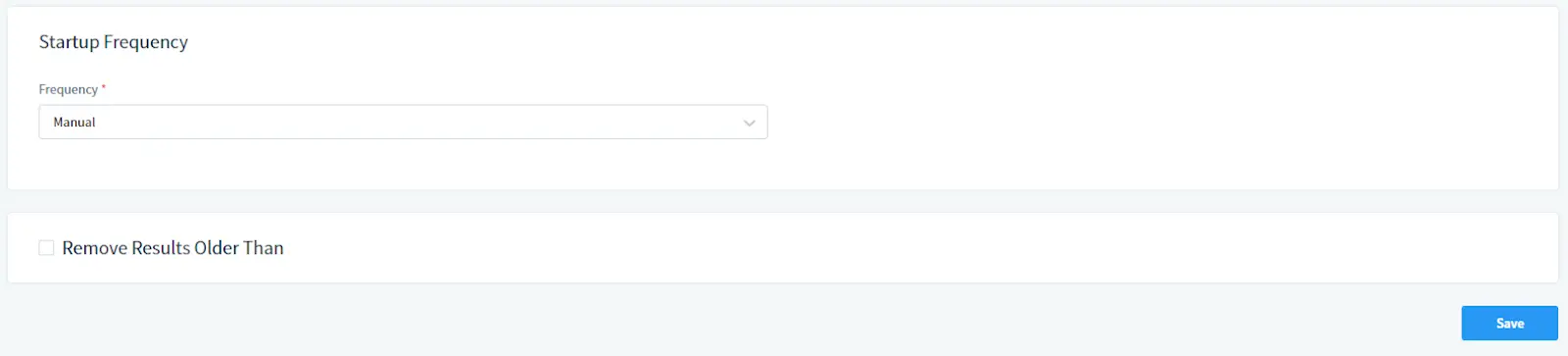
Seleziona la frequenza di esecuzione del Task. Seleziona Manuale per l’avvio manuale o imposta una pianificazione.
Importante: è necessario abilitare il parametro aggiuntivo imageDataDiscovery prima di avviare il task. Puoi farlo nelle Impostazioni Aggiuntive (Impostazioni di Sistema -> Parametri Aggiuntivi) o nella sottosezione Impostazioni Aggiuntive Personalizzate della pagina del task.
Seleziona imageDataDiscovery nell’elenco e abilitalo come mostrato di seguito:
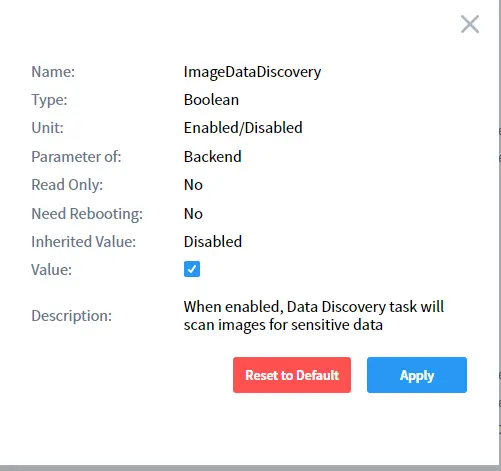
Esegui il task manualmente o secondo la pianificazione e DataSunrise eseguirà automaticamente la scoperta OCR:

Per i risultati della ricerca, fai riferimento alla tabella dei Risultati della Ricerca: