
Che Cos’è il Partitioning?
Il Partitioning è la divisione degli oggetti del database memorizzati (tabelle, indici, viste) in parti separate. Il Partitioning viene utilizzato per aumentare la governabilità, le prestazioni e la disponibilità di grandi oggetti del database.
- In alcuni casi, il partitioning migliora le prestazioni nell’accesso alle tabelle partizionate.
- Il partitioning può svolgere il ruolo di colonne principali negli indici, diminuendo la dimensione dell’indice e aumentando la possibilità di trovare gli indici più cercati nella memoria. Quando una grande parte di una sezione è utilizzata nel risultato, la scansione di questa sezione può essere eseguita molto più velocemente rispetto a un accesso occasionale ai dati sparsi per tutta la tabella mediante indice.
- Il caricamento e la cancellazione massiva dei dati possono essere eseguiti aggiungendo e cancellando sezioni, il che aiuta ad aumentare le prestazioni.
- I dati utilizzati raramente possono essere caricati su dispositivi di archiviazione dati più economici.
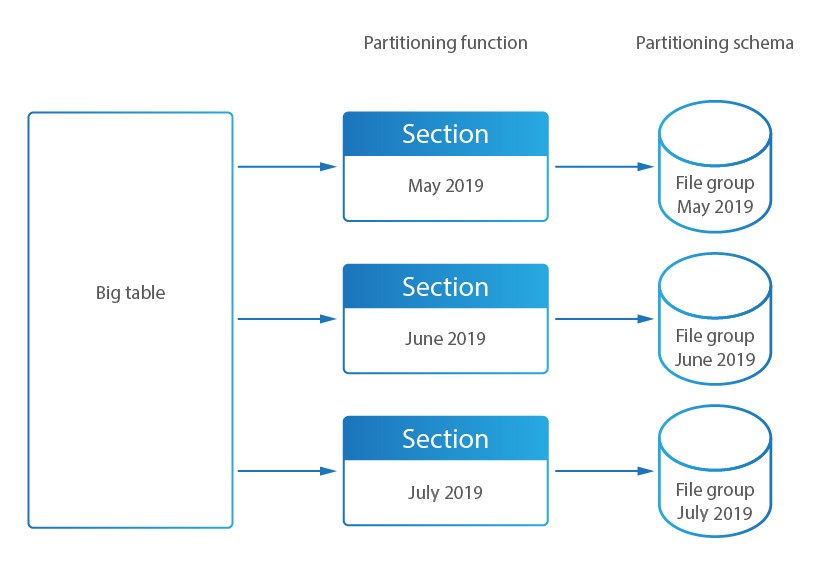
In DataSunrise, il partitioning viene utilizzato per dividere le tabelle del database dell’Audit Storage in sezioni (tabelle più piccole). L’Audit Storage è un database utilizzato per memorizzare i risultati del Database Activity Monitoring di DataSunrise.
- Rende più semplice l’amministrazione dell’Audit Storage, perché i dati partizionati sono distribuiti per partizioni secondo il momento del partitioning. L’amministratore del database può disabilitarne la consultazione delle partizioni, archiviarle ecc.
- Aumenta le prestazioni nell’accesso, nel recupero dei dati, scrittura dei dati nelle tabelle partizionate;
- Aumenta le prestazioni nella cancellazione dei dati di audit obsoleti dall’Audit Storage;
DataSunrise supporta il partitioning per i seguenti tipi di database dell’Audit Storage:
- PostgreSQL
- MySQL
- MS SQL Server
Parametri del Partitioning
Possono essere trovati nelle Impostazioni di Sistema -> Parametri aggiuntivi.
- Durata Partizioni (giorni) – durata della partizione, giorni (se AuditPartitionShort == 1, allora minuti). Può essere trovato in Impostazioni di Sistema -> Audit Storage. Se la Durata Partizioni viene cambiata, tutte le partizioni create in anticipo saranno cancellate e nuove partizioni saranno create con i nuovi parametri di Durata Partizioni.
- AuditPartitionCountCreatedInAdvance – numero di partizioni create in anticipo. In questo modo vengono create partizioni vuote da riempire in futuro. Questo permette a DataSunrise di scrivere i dati nelle partizioni esistenti senza ritardi;
- AuditPartitionFirstEndDateTime – data/ora della fine della prima partizione. Questo tempo è richiesto per l’aggiustamento dei confini delle partizioni attorno al valore “tondo”. Per esempio: lunedì 00:00:00 (per partizioni lunghe 7 giorni).
Gestione del Partitioning in DataSunrise
DataSunrise include meccanismi di gestione delle partizioni: DataSunrise crea le tabelle aggiuntive richieste per il funzionamento (per PostgreSQL), crea e mantiene aggiornate le funzioni di partitioning, schemi partizionati, gruppi di file e indici (per MS SQL), modifica chiavi e indici per essere conformi ai requisiti del partitioning (MySQL), abilita il partitioning, crea e cancella le partizioni.
I SELECT vengono eseguiti attraverso la tabella master. Gli INSERT/UPDATE vengono eseguiti direttamente sulla partizione (eccetto MS SQL Server). Questo aiuta ad aumentare la velocità di scrittura.
Nomi di Partizioni e Tabelle
Le partizioni per PostgreSQL sono organizzate come tabelle figlie denominate <table_name>_p<datetime>, dove <table_name> è la tabella master e <datetime> è il tempo di confine superiore della partizione nel formato seguente: YYYYMMDDhhmm.
Per MySQL, il partitioning è implementato utilizzando meccanismi nativi. I nomi delle partizioni sono formati secondo il seguente schema: p<datetime>, dove <datetime> è il tempo di confine superiore della partizione nel formato seguente: YYYYMMDDhhmm.
Per MS SQL Server, il partitioning è implementato attraverso schemi.
