
Nuove Capacità per la Discovery dei Dati Sensibili su Amazon S3 di DataSunrise
Introduzione
Secondo un recente sondaggio, oltre il 50% delle aziende ospitano una grande quantità di dati sensibili nell’archiviazione Cloud, come S3 di Amazon.
DataSunrise Sensitive Data Discovery è disponibile per la ricerca, classificazione e gestione rapida dei dati. La ricerca e l’analisi dei dati nei tuoi storage dati ti permettono di individuare tempestivamente i dati sensibili su Amazon S3 in maniera veloce e senza sforzo. Abbiamo aggiornato il nostro strumento. In precedenza potevamo scoprire dati semi-strutturati e non strutturati su S3 grazie alla funzionalità NLP, e ora possiamo fare ancora di più.
DataSunrise Sensitive Data Discovery
La Data Discovery per Amazon S3 ha nuove capacità per la rilevazione e la protezione dei dati sensibili. Ora la Data Discovery è disponibile per:
- Formati di file Apache Parquet;
- File semi-strutturati come XML, JSON, CSV;
- Formati di testo non strutturati come documenti Microsoft Word;
- Immagini.
La Data Discovery per S3 analizza non solo gli oggetti ma anche i loro nomi e i percorsi. DataSunrise collega le relazioni semantiche con il contesto dell’oggetto per una scoperta completa e comprensiva dei dati sensibili. Così non devi preoccuparti dei nomi specifici degli oggetti che contengono informazioni sensibili e private.
Template predefiniti e personalizzati per PII. DataSunrise dispone di molti template predefiniti per la ricerca di dati sensibili come numeri di carte di credito, passaporti, patenti di guida. Per una ricerca più flessibile, puoi sfruttare tipi di informazioni personalizzati (potrebbero essere impostati usando espressioni regolari, script Lua, ecc.). Grazie a questi filtri, avrai un quadro esauriente dei dati sensibili raccolti. La messa a punto della scoperta ti farà risparmiare tempo e altre risorse. La cosa più importante è che sarai sicuro che non ci siano dati sensibili non sotto il tuo controllo che potrebbero portare a una esposizione dei dati.
Data Discovery on-demand. Puoi creare e eseguire la Data Discovery non solo manualmente tramite la Web Console. Usa il terminale di sistema con l’Interfaccia a Riga di Comando per creare sistemi automatici che rispondano agli eventi di sicurezza senza intervento manuale.
Discovery dei Dati Sensibili nelle immagini. Le aziende che archiviare dati sensibili nelle immagini (patenti di guida, SSN, ecc.) saranno liete di usare DataSunrise Data Discovery con il riconoscimento ottico dei caratteri. L’uso della discovery delle immagini ti permette di cercare dati sensibili nelle immagini grazie al motore OCR. Estrae il testo dalle immagini, poi analizza queste informazioni e trova dati privati nei documenti. La nostra Image Data Discovery supporta i seguenti formati di file: JPG, PNG, GIF, TIFF, PSD.
Discovery dei Dati in file compressi e archiviati. Insieme agli oggetti e ai diversi formati di file, la Data Discovery per S3 può cercare dati sensibili anche in formati compressi e archiviati. I file compressi ti permettono di ridurre lo spazio utilizzato risparmiando sui costi. I file archiviati ti permettono di raccogliere e raggruppare i file in un unico luogo combinandoli. Indipendentemente dalla dimensione dell’archivio, i dati sensibili saranno scoperti.
Prestazioni della Data Discovery dei Dati Sensibili
La Data Discovery dei Dati Sensibili funziona a diversi livelli su S3. Prima di tutto, puoi scoprire i tuoi bucket e gli oggetti S3 per informazioni sensibili. È il modo più semplice per trovare informazioni private che devono essere protette. Ma quando hai molti bucket e oggetti S3, questo compito diventerà lungo e faticoso. Con DataSunrise sarai in grado di risparmiare tempo, budget e altre risorse poiché ora DataSunrise supporta diverse tecniche per aumentare le prestazioni.
Inventario di AWS S3. Mantiene tutti i metadata sui tuoi bucket S3 in un unico posto sotto forma di un file CSV archiviato. Per ridurre il consumo di traffico e i costi operativi, DataSunrise può ottenere questi metadata usando S3 Inventory senza chiamate API AWS.
Incremental Data Discovery. Con l’Incremental Data Discovery, non è necessario riscoprire ripetutamente gli stessi oggetti e bucket per la presenza di dati sensibili. La modalità di scansione incrementale salta i bucket e gli oggetti scoperti in precedenza. Scansiona solo i nuovi o aggiornati oggetti, confrontandoli con l’ultima scansione. Ti aiuta a risparmiare tempo e denaro mentre lavoro su grandi volumi di dati. Inoltre, la scansione incrementale è opzionale, quindi puoi disabilitarla quando ne hai bisogno.
Parallel Data Discovery. Per la ricerca rapida di dati sensibili in grandi volumi di dati, puoi utilizzare l’implementazione del multiprocessing. Permette l’uso di più server DataSunrise per la discovery parallela dei dati. Con la discovery parallela, sarai in grado di ottimizzare l’uso della CPU e della memoria. L’uso del multiprocessing semplifica il lavoro di data discovery quando devi elaborare grandi volumi di dati. Inoltre, riduce il carico sul server e non influisce sui processi paralleli che hai. Con il multiprocessing, puoi scegliere più attributi di ricerca ed escludere oggetti specifici dalla scansione.
Random Data Discovery. Consente di scansionare file casuali nei bucket S3 per accelerare il processo di Data Discovery. È possibile scegliere la percentuale di dati sensibili da scoprire in grandi volumi di dati.
Divisione dei file grandi in pezzi. Gli oggetti grandi consumano spazio aggiuntivo durante i calcoli in memoria. Ora possiamo dividere qualsiasi oggetto in pezzi per aumentare le prestazioni e ottimizzare l’uso della memoria. Con parametri aggiuntivi come “DataDiscoveryChunkSize” e altri, possiamo facilmente scoprire questi pezzi e trovare qualsiasi informazione sensibile.
Impostazioni e Personalizzazione della Data Discovery dei Dati Sensibili
Puoi ottimizzare il processo di discovery regolando alcuni parametri aggiuntivi.
DataSunrise ha oltre 25 parametri personalizzabili. Ad esempio:
- “DataDiscoveryMatchesSaveStrategy” permette di salvare le occorrenze della Data Discovery nel Dizionario a seconda delle tue esigenze particolari: salvare le prime corrispondenze, tutte le corrispondenze, o corrispondenze uniche;
- “DataDiscoveryChunkSize” permette il download parziale dei file per la Data Discovery per evitare il sovraccarico della memoria. Puoi impostare la dimensione del chunk e il limite della somma dei chunk;
- “DataDiscoveryMaxFileSizeForChunkProcessing” è per la dimensione del file intera da scansionare come somma dei chunk. La scansione dei chunk avviene fino al raggiungimento del valore di questo parametro;
- “DataDiscoveryS3FilePartToRead” è per la dimensione massima del file (Mb) per la Data Discovery su S3. Questo parametro funziona in combinazione con DataDiscoveryFilesThreadPools. Definisce il numero di thread utilizzati per l’elaborazione dei file. Ogni thread elabora un file alla volta. Quindi, il valore di questo parametro dipende dalle risorse di sistema disponibili.
- “DataDiscoveryBatchSplitFactor” identifica in quante parti sarà suddiviso il batch non riuscito per una successiva riesecuzione del compito di data discovery.
Reporting della Data Discovery dei Dati Sensibili
DataSunrise fornisce una protezione multilivello per AWS S3. Di conseguenza, DataSunrise opera su una grande quantità di dati. Ti permette di ottenere tutte le informazioni più dettagliate sui tuoi database e sui dati in essi contenuti creando report personalizzati in formato CSV o PDF.
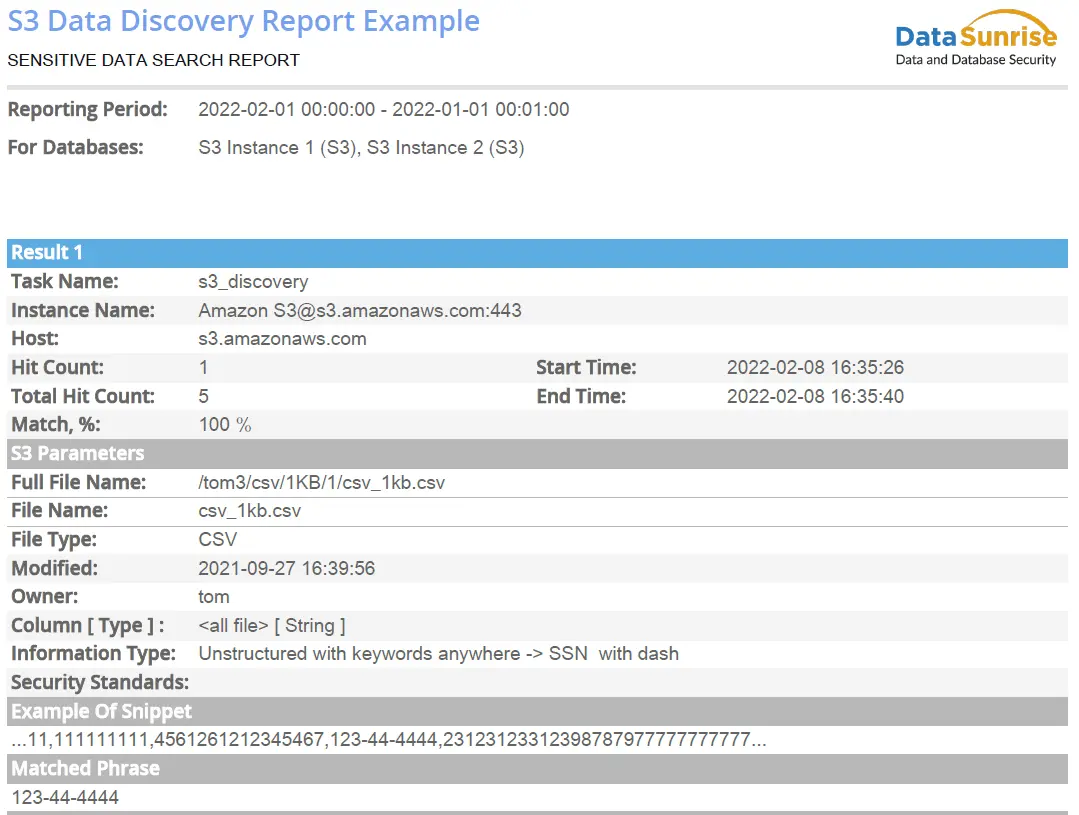
Immagine 1: Esempio di Report PDF di Sensitive Data Discovery
Disponibilità dei report. Ora la generazione dei report è possibile durante il processo di Discovery, non è necessario aspettare il completamento del compito. Ti permette di visualizzare risultati intermedi e usarli per l’analisi.
Uso dei report. Tramite i risultati dei report, puoi raccogliere analisi e ottenere statistiche sulla velocità di elaborazione dei dati e sugli attributi e utilizzare i dati ricevuti per scopi specifici, inclusa l’apprendimento del tuo AI.
Con un sistema flessibile di report personalizzabili, non è più necessario monitorare manualmente le informazioni sui livelli di protezione dei tuoi database.
Conclusione
Il Sensitive Data Discovery ti permette di sapere dove risiedono i dati sensibili nei tuoi bucket AWS S3 e sfruttare i mezzi di protezione dei dati rispettivamente.
DataSunrise fornisce una grande varietà di formati e modalità di scoperta dei dati sensibili su AWS S3 dovunque essi risiedano. Con le prestazioni migliorate, la Data Discovery richiederà meno tempo. Puoi fidelizzare DataSunrise Sensitive Data Discovery per evitare ricerche ripetute non necessarie tra grandi volumi di dati. I modelli di ricerca modificabili ti permettono di effettuare una ricerca mirata per qualsiasi dato specifico. Con il reporting puoi ottenere le informazioni più dettagliate che ti permetteranno di vedere risultati intermedi per l’analisi, l’apprendimento dell’AI, e altri processi aziendali.
Per iniziare con DataSunrise su Amazon, visita DataSunrise nel Marketplace AWS.
