How To Offload The Audit Database Data To AWS S3 And Read It Using AWS Athena Service
Audit Archiving is an optional feature of the Audit Database Cleanup Task in DataSunrise Database Security. This feature allows a DataSunrise installation administrator to remove older audited data and store it in AWS S3 service to provide a better, more cost-efficient way of storing expired data. With the use of AWS Athena Service Security Team and External Auditors are able to examine the historical data needed for audits and incidents investigations. Aside from that, using Audit Archiving lets DataSunrise clients to maintain larger datasets of audited events without storing everything in the single Audit Storage database and experiencing the increased report timings. Moreover, using S3 for cold data is a more cost-efficient solution, which can help to optimize the budget on the project by keeping the Audit Database Size under control.
For Audit Archiving DataSunrise team provides the dedicated script for Linux deployments which can be adjusted to put the removed data to a customizable S3 location. It is coming as a part of the default DataSunrise installation bundle, so you do not need to download it from anywhere additionally.
This article is going to walk you through the process of Setting up and the Audit Cleanup task, offloading the removed data to the S3 Bucket location of your choice and setting up the environment in the AWS Athena for the forensics.
Configure a Clean Audit Data Task with Audit Archiving Option
- Open the DataSunrise Web-UI and navigate to Configuration → Periodic Tasks. Click on the New Task button and provide the General information like Name, Task Type (e.g. Clean Audit Data), and select the server to execute the task on in case you are using a Cluster of DataSunrise nodes.
- Set the Archive Options in the Clean Audit Data section:
- Check the Archive Removed Data option before Cleaning.
- Specify the Archive Folder path where the audit data should be temporarily stored before moving to S3.
- Specify the path to the script that uploads the data to AWS S3 using the “Execute Command After Archiving” input field. Default path – /opt/datasunrise/scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
(required) - Provide extra parameters for the script to adjust the behavior (see below for the option script arguments).
- Adjust the Task Frequency in the “Startup Frequency” section, use can set how often the task should run (e.g., daily, weekly, monthly) based on the organization’s needs for audit data retention and archiving.
- Save the task after configuring all the necessary settings.
- Start the task manually or automatically, If the user configured the task to start manually, the user can start it by selecting the task and clicking Start Now. If it’s set to start based on a schedule, it will run automatically at the specified times.
- After performing the task, an archive folder will be created on the DataSunrise Server filesystem where the task was run (on Linux distributions, the default path will be /opt/datasunrise/).
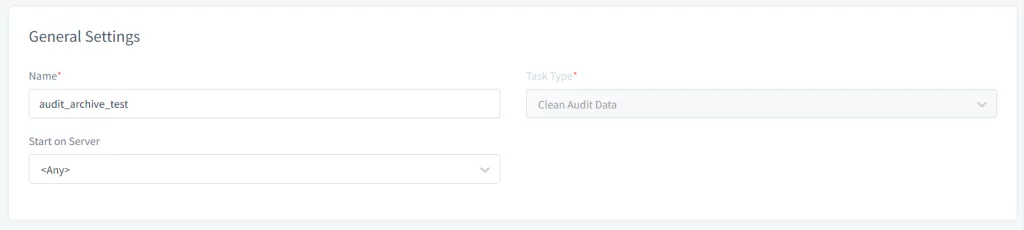
Picture 1. General Settings
Note: if you are running DataSunrise on AWS ECS Fargate, use the ecs_upload_ds_audit_to_aws_s3.sh instead located in the same directory.
Note: you can provide paths relative to DataSunrise installation folder (i.e. ./scripts/aws/cf_upload_ds_audit_to_aws_s3.sh
Note: if you provide the default Archive Folder name the script expects (i.e. /ds-audit-folder), then you do not need to specify it in the script arguments.
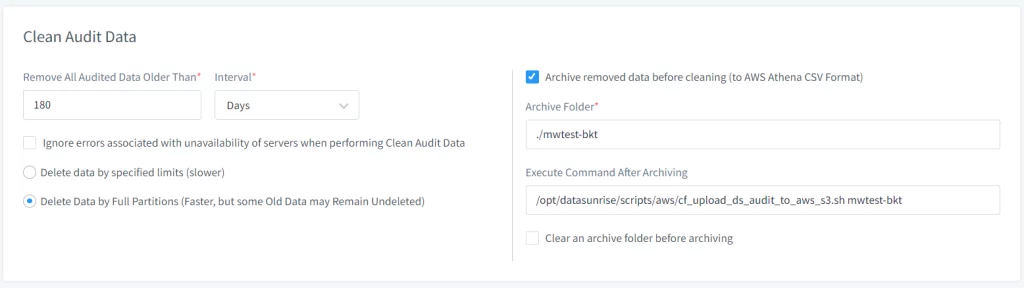
Picture 2. Extra Commands for the Clean Audit Task
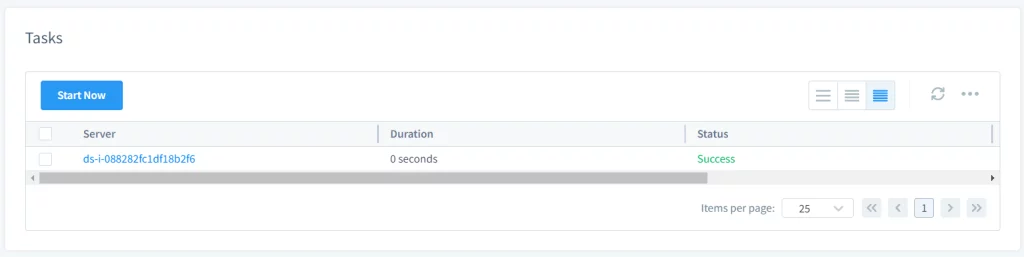
Picture 3. Start the Task
Note: The above steps can also be used to manage the audit data retention in DataSunrise, users can utilize the “Periodic Clean Audit” feature to regularly remove outdated audit data. This ensures the efficiency of the DataSunrise server by preventing storage overflow with outdated data.
The Archived Audit Data Uploader Script
To upload the archive folder to an AWS S3 bucket use the script provided by DataSunrise located in the
To define a bucket to push archived audit data to, provide your AWS S3 bucket name without s3:// scheme:
./scripts/aws/cf_upload_ds_audit_to_aws_s3.sh datasunrise-audit-archive
To customize the archiving process, you can use the following optional flags:
- –-archive-folder: provide your own path on the DataSunrise Server to put the archived audit data files. By default, the ds-audit-archive folder will be created at the /opt/datasunrise/ location. You do not need to provide this option if you define the Audit Archive folder as ds-audit-archive within the DataSunrise root installation directory.
- –folder-in-bucket: provide your own prefix to put the audited data to. By default the script unloads data to the
/ds-audit-archive prefix. - –predefined-credentials: In case you are running DataSunrise outside AWS, to be able to upload data to S3, you will need either a credentials file or the ACCESS/SECRET Key pair for the IAM User authorized to access the desired S3 Bucket. Does not require any inputs.
Note: The folder size is monitored during the audit unload, and when it exceeds a certain threshold, the command is executed. If no script is specified, an error occurs when the threshold is exceeded. The threshold is set using “AuditArchiveFolderSizeLimit” Additional Parameter, with a default value of 1 GB. A user can pre-clean an archive folder using the “Clear an archive folder before archiving” option.
Audit Archive Folder Structure
The structure of the archive folder where DataSunrise stores audit data typically follows a hierarchical format that is organized by date. This organization helps in managing the data efficiently and makes it easier to locate specific audit records based on the date. Here’s a general outline of what the structure might look like:
Generalized Folder Structure Templa
Base Directory: /opt/datasunrise/ds-audit-archive/
└── Year: {YYYY}/
└── Month: {MM}/
└── Day: {DD}/
└── Audit Files: audit_data_{YYYY}-{MM}-{DD}.csv.gzOnce the audit data is uploaded to the S3, the structure is preserved the same way it is staged on the DataSunrise Server:
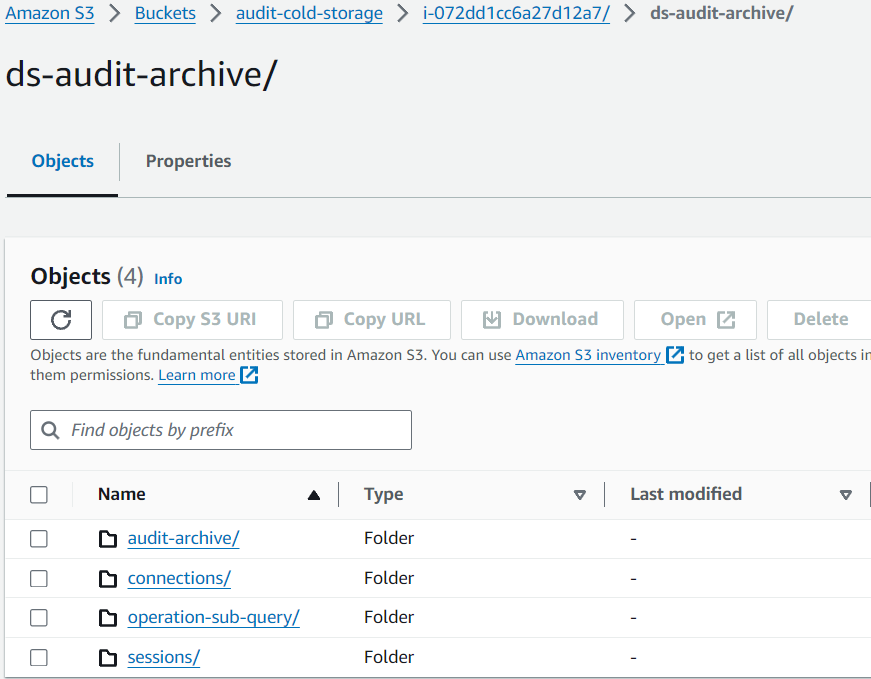
Picture 4. Data in the Amazon S3 Bucket
Using AWS Athena for reading Audit Archive Data From S3
Once the audit data is uploaded to the S3, you can create the Audit Database schema in AWS Athena Service for further analysis. Proceed to AWS Athena in AWS Management Console to set up a Database and Tables to read your archived data. To be able to fully use AWS Athena service, we recommend using AmazonAthenaFullAccess AWS Managed IAM Policy for the IAM User created to work with the Archived Audit data.
Create Audit Archive tables in AWS Athena
The SQL scripts assume the following for the LOCATION clause of the CREATE EXTERNAL TABLE queries:
– The S3 Bucket name is datasunrise-audit
The DDL SQL file for AWS Athena Audit Archive tables is also available from the DataSunrise distribution with the default path: /opt/datasunrise/scripts/aws/aws-athena-create-audit-archive-tables.sql.
CREATE DATABASE IF NOT EXISTS datasunrise_audit;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.audit_archive (
operations__id STRING,
operations__session_id STRING,
operations__begin_time STRING,
operations__end_time STRING,
operations__type_name STRING,
operations__sql_query STRING,
operations__exec_count STRING,
sessions__user_name STRING,
sessions__db_name STRING,
sessions__service_name STRING,
sessions__os_user STRING,
sessions__application STRING,
sessions__begin_time STRING,
sessions__end_time STRING,
connections__client_host_name STRING,
connections__client_port STRING,
connections__server_port STRING,
connections__sniffer_id STRING,
connections__proxy_id STRING,
connections__db_type_name STRING,
connections__client_host STRING,
connections__server_host STRING,
connections__instance_id STRING,
connections__instance_name STRING,
operation_rules__rule_id STRING,
operation_rules__rule_name STRING,
operation_rules__chain STRING,
operation_rules__action_type STRING,
operation_exec__row_count STRING,
operation_exec__error STRING,
operation_exec__error_code STRING,
operation_exec__error_text STRING,
operation_group__query_str STRING,
operations__operation_group_id STRING,
operations__all_exec_have_err STRING,
operations__total_affected_rows STRING,
operations__duration STRING,
operations__type_id STRING,
connections__db_type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/audit-archive/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
-- The next query loads partitions to be able to query data.
MSCK REPAIR TABLE datasunrise_audit.audit_archive;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.sessions (
partition_id STRING,
id STRING,
connection_id STRING,
host_name STRING,
user_name STRING,
scheme STRING,
application STRING,
thread_id STRING,
process_id STRING,
begin_time STRING,
end_time STRING,
error_str STRING,
params STRING,
db_name STRING,
service_name STRING,
os_user STRING,
external_user STRING,
domain STRING,
realm STRING,
sql_state STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/sessions/'
TBLPROPERTIES ('has_encrypted_data'='false','skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.sessions;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.connections (
partition_id STRING,
id STRING,
interface_id STRING,
client_host STRING,
client_port STRING,
begin_time STRING,
end_time STRING,
client_host_name STRING,
instance_id STRING,
instance_name STRING,
proxy_id STRING,
sniffer_id STRING,
server_host STRING,
server_port STRING,
db_type_id STRING,
db_type_name STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/connections/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.connections;
----------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.operation_sub_query (
operation_sub_query__operation_id STRING,
operation_sub_query__session_id STRING,
operation_sub_query__type_name STRING,
operations__begin_time STRING,
operation_sub_query__type_id STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/operation-sub-query/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.operation_sub_query;
----------------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.col_objects (
operation_id STRING,
session_id STRING,
obj_id STRING,
name STRING,
tbl_id STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/col-objects/' -- path to S3 folder
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.col_objects;
---------------------------------------------------------------------
CREATE EXTERNAL TABLE IF NOT EXISTS datasunrise_audit.tbl_objects (
tbl_objects__operation_id STRING,
tbl_objects__session_id STRING,
tbl_objects__obj_id STRING,
tbl_objects__sch_id STRING,
tbl_objects__db_id STRING,
tbl_objects__tbl_name STRING,
tbl_objects__sch_name STRING,
tbl_objects__db_name STRING,
operations__begin_time STRING
)
PARTITIONED BY (
`year` STRING,
`month` STRING,
`day` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
LOCATION 's3://datasunrise-audit/tbl-objects/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');
MSCK REPAIR TABLE datasunrise_audit.tbl_objects;
Query the data in AWS Athena Console using standard SQL queries:
--running SELECT against the audit_archive table with the filters by year, month and day
SELECT * FROM audit_archive WHERE year = '2024' and month = '05' and day = '16';
--selecting data from multiple tables through JOIN clause
SELECT
r.operations__type_name,
s.operation_sub_query__type_name,
r.operations__sql_query
FROM audit_archive AS r
JOIN operation_sub_query AS s
ON
r.operations__id = s.operation_sub_query__operation_id
AND
r.operations__session_id = s.operation_sub_query__session_id;
–-Extract 100 rows without filters applied
select * from audit_archive LIMIT 100;
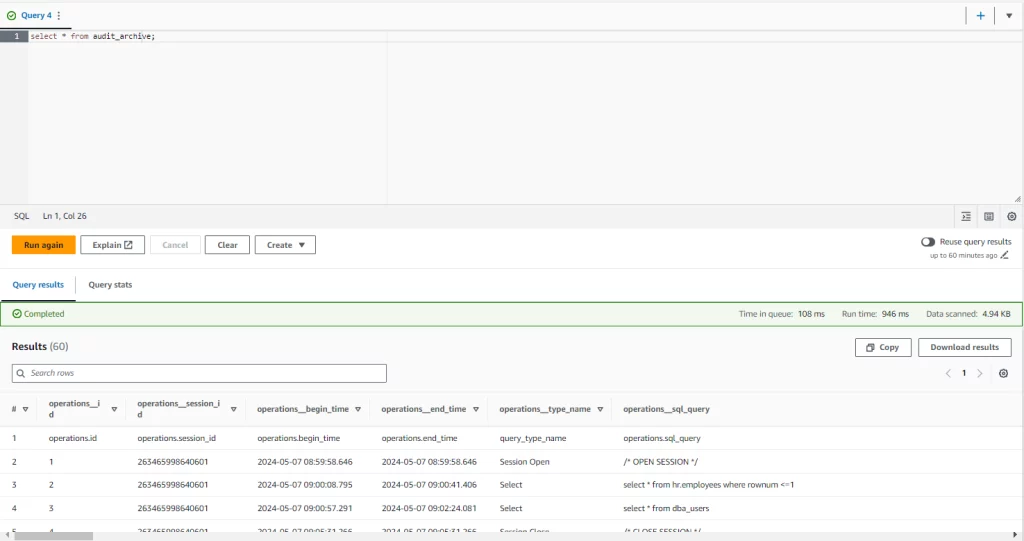
Picture 5. Audit Archive
Conclusion
A long data retention period for the sensitive data like Audited events can be a real challenge and an additional load on the budget for maintaining large datasets within the Database files. DataSunrise Audit Archiving provides an efficient and secure solution for keeping the older data readable, offloading the Database Storage layer and allowing our clients a resilient and cost-efficient solution based on AWS S3 Athena Services to keep the old data within your Organization and accessible for auditing and compliance.