
Cluster Data: How They Work & How To Use Them

Cluster data is a powerful technique that helps uncover hidden patterns and trends in large datasets. It groups similar objects together, making it easier to analyze and understand complex information. Data scientists use clustering to quickly identify themes, detect anomalies, and gain valuable insights from massive amounts of data.
What is Data Clustering?
At its core, data clustering is an unsupervised machine learning method. It doesn’t require labeled data or predefined categories. Instead, the algorithm finds natural groupings within the dataset based on similarity. We put similar objects in the same group and separate different objects.
The process is flexible and can work with various types of data:
- Documents
- Points on a graph
- Survey responses
- Genetic sequences
As long as there’s a way to measure similarity between two objects, clustering can be applied. This variety makes it a go-to tool for exploration data analytics across industries.
Data Cluster Analyzing in Action
Imagine you run an e-commerce site with thousands of products. You want to understand customer behavior better and personalize recommendations. By clustering your product data, you might discover interesting groups:
- Bestsellers that are frequently bought together
- Niche items appealing to specific demographics
- Seasonal trends around holidays or events
These insights can inform marketing strategies, inventory management, and website design. You can highlight popular product bundles, tailor email campaigns to customer segments, and optimize navigation based on browsing patterns.
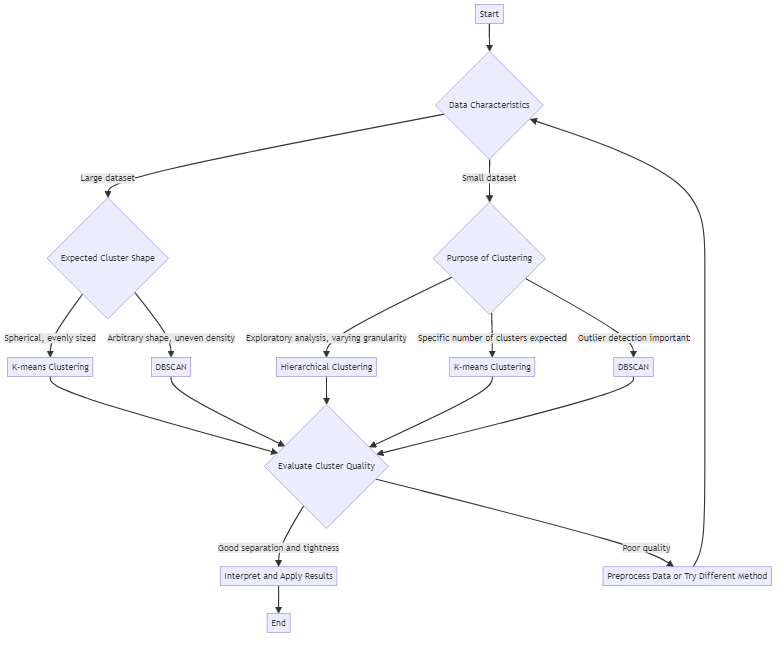
Choosing the Right Clustering Algorithm
Different clustering algorithms suit different purposes. Some common ones include:
- K-means: Divides data into a predefined number (k) of data clusters. Works well when you have a sense of how many groups to expect.
- Hierarchical clustering: Builds nested data clusters in a tree-like structure. Useful for visualizing data at varying levels of granularity.
- DBSCAN: Identifies clusters of arbitrary shape and marks outliers. Handles datasets with noise and uneven density.
The right choice depends on factors like data size, expected cluster shape, and tolerance for outliers. Trying multiple approaches is often worth it to see which yields the most meaningful results.
Evaluating Data Cluster Quality
Not all clusters are created equal. A good clustering result has tight, well-separated groups. Objects within a cluster should be highly similar, while objects in different clusters should be distinct. Silhouette scores and visualization techniques can help assess data cluster quality.
Validating clusters against domain knowledge is crucial in ensuring the accuracy and relevance of the clustering results. We can see if the clusters align with expert opinions or business goals. This will help us determine if they are suitable for the specific domain or industry. This validation process helps to confirm that the clusters are meaningful and useful for decision-making purposes.
Clustering helps find patterns in data, but it’s just the beginning. Humans must interpret the results of clustering to extract actionable insights and make informed decisions. By using both numbers and expert opinions, we can better understand the data and how it affects the business.
In summary, validating clusters against domain knowledge and interpreting the results are essential steps in the clustering process. We make sure the groups are useful and practical by using knowledge and judgment in a specific field. This will ultimately contribute to the success of the business.
Applications of Cluster Data
The use cases for cluster data span diverse domains:
- Customer segmentation for targeted marketing
- Anomaly detection in fraud prevention
- Image compression and pattern recognition
- Bioinformatics and gene expression analysis
- Social network analyzing and community detection
Wherever there’s complex data to untangle, clustering provides a valuable starting point. It simplifies the data landscape and surfaces key structures for further investigation.
Cluster Data Best Practices
To get the most out of cluster data, keep these tips in mind:
- Preprocess and normalize data to ensure fair comparisons
- Experiment with different distance metrics and algorithms
- Validate results using statistical measures and domain expertise
- Visualize data clusters to communicate insights effectively
- Iterate and refine the process as new data becomes available
With proper implementation, cluster data can be a game-changer. It turns overwhelming datasets into actionable intelligence, empowering organizations to make smarter decisions.
Putting Cluster Data to Work
Unlock the power of your data with clustering. Cluster analyzing is a crucial tool for marketers, researchers, and data scientists. It helps you gain insights from customers, explore gene networks, and solve complex problems. Start exploring the world of data clustering and discover hidden patterns today.
