
Data Bottleneck Test

The efficiency of data processing and transfer is crucial for optimal system performance. A data bottleneck test is an essential tool for identifying and addressing performance limitations in various computing environments. This article will delve into the fundamentals of data bottleneck tests and explore methods for obtaining suitable test data.
While the market offers a plethora of tools for database and application bottleneck testing, many of these solutions demand extensive expertise to implement effectively. DataSunrise, however, stands out by providing a user-friendly yet powerful platform that simplifies the complex process of data bottleneck testing.
Why Data Bottleneck Tests Matter
Imagine you’re trying to pour water through a funnel. The water flow is smooth until it reaches the narrow part of the funnel, where it slows down. This is similar to how data bottlenecks work in computing systems. Data bottlenecks can significantly impact system performance, leading to slower processing times and reduced efficiency.
Data bottleneck tests find system weak points, so you can improve performance and efficiency. Whether you’re a software developer, database administrator, or IT professional, understanding and conducting data bottleneck tests is crucial for maintaining high-performing systems.
Understanding Data Bottlenecks
What is a Data Bottleneck?
A data bottleneck occurs when the flow of data in a system is constrained, leading to delays and reduced performance. These constraints can happen at various points: CPU processing, Memory access, Storage I/O, Network transmission.
The Impact of Data Bottlenecks
Data bottlenecks can have far-reaching consequences: slower application response times, reduced system throughput, increased resource utilization, poor user experience.
By identifying and addressing these bottlenecks, you can significantly improve your system’s performance and reliability.
Conducting a Data Bottleneck Test
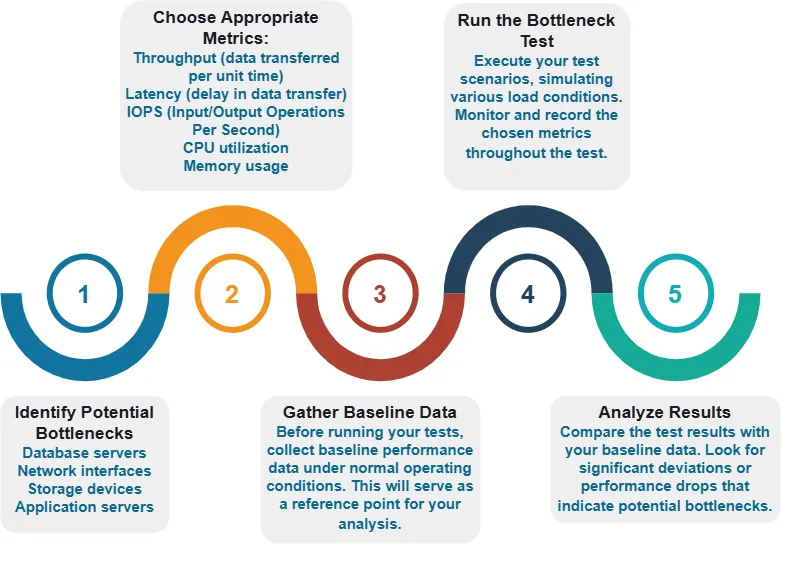
Sourcing Test Data for Bottleneck Tests
One of the challenges in conducting data bottleneck tests is obtaining suitable test data. Let’s explore some methods for acquiring or generating test data.
Using Production Data (with Caution)
While using real production data can provide the most accurate results, it comes with significant risks:
- Privacy concerns
- Regulatory compliance issues
- Potential for data breaches
If you choose to use production data, ensure you have proper authorization and implement robust security measures.
Synthetic Data Generation
DataSunrise stands out as a leader in database security and data management solutions, offering cutting-edge synthetic test data capabilities for a wide range of databases and data warehouses. Our advanced tools significantly streamline the process of generating high-quality test data, saving organizations valuable time and resources.
With support for dozens of popular database platforms, DataSunrise provides unparalleled flexibility and efficiency in creating realistic, privacy-compliant test datasets. This makes it an invaluable asset for companies looking to conduct thorough data bottleneck tests without compromising sensitive information.
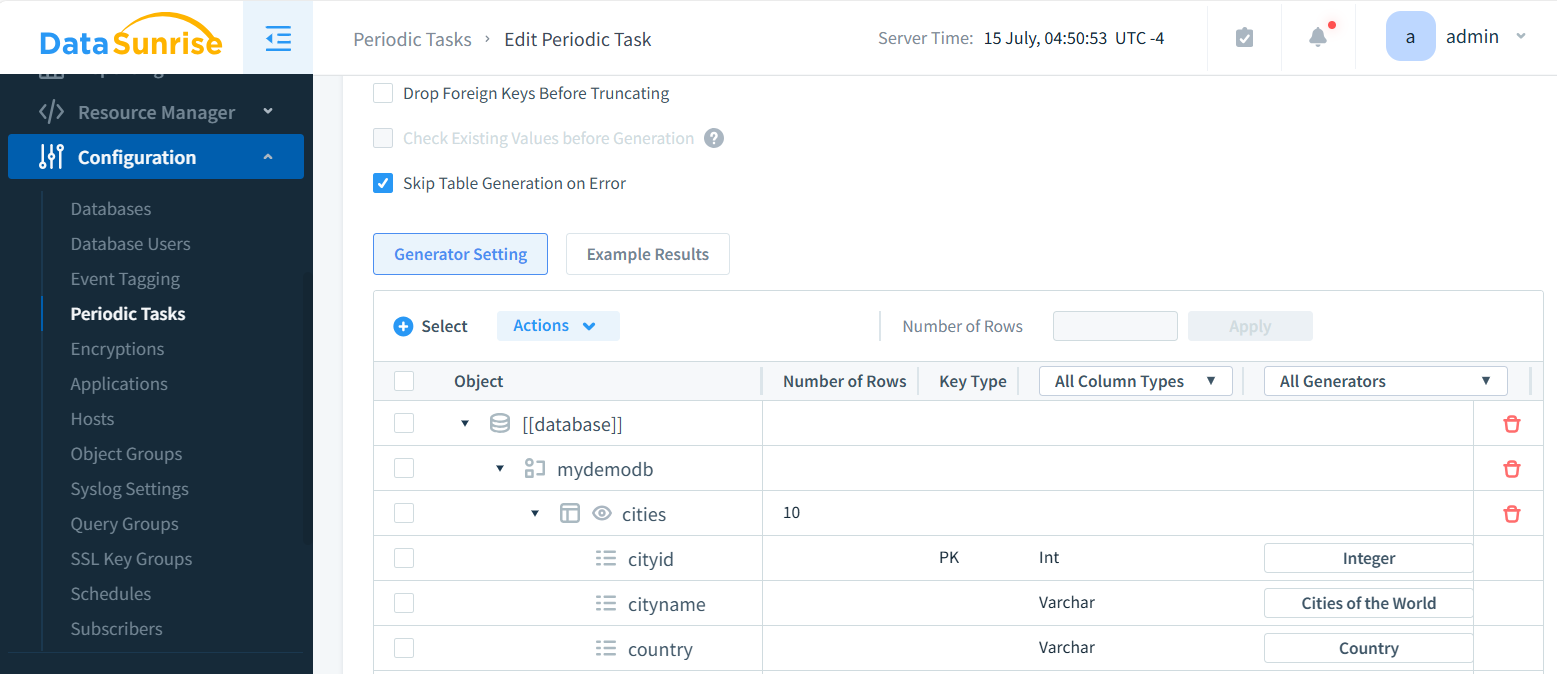
Synthetic data offers a safe alternative to production data. It artificially mimics the characteristics of real data without exposing sensitive information.
Benefits of Synthetic Data:
- No privacy risks
- Customizable to specific test scenarios
- Scalable to large volumes
Methods for Generating Synthetic Data:
- Random Data Generation: Create data using random number generators and predefined rules.
- Pattern-Based Generation: Generate data that follows specific patterns or distributions observed in real data.
- Model-Based Generation: Use machine learning models to create data that closely resembles real-world datasets.
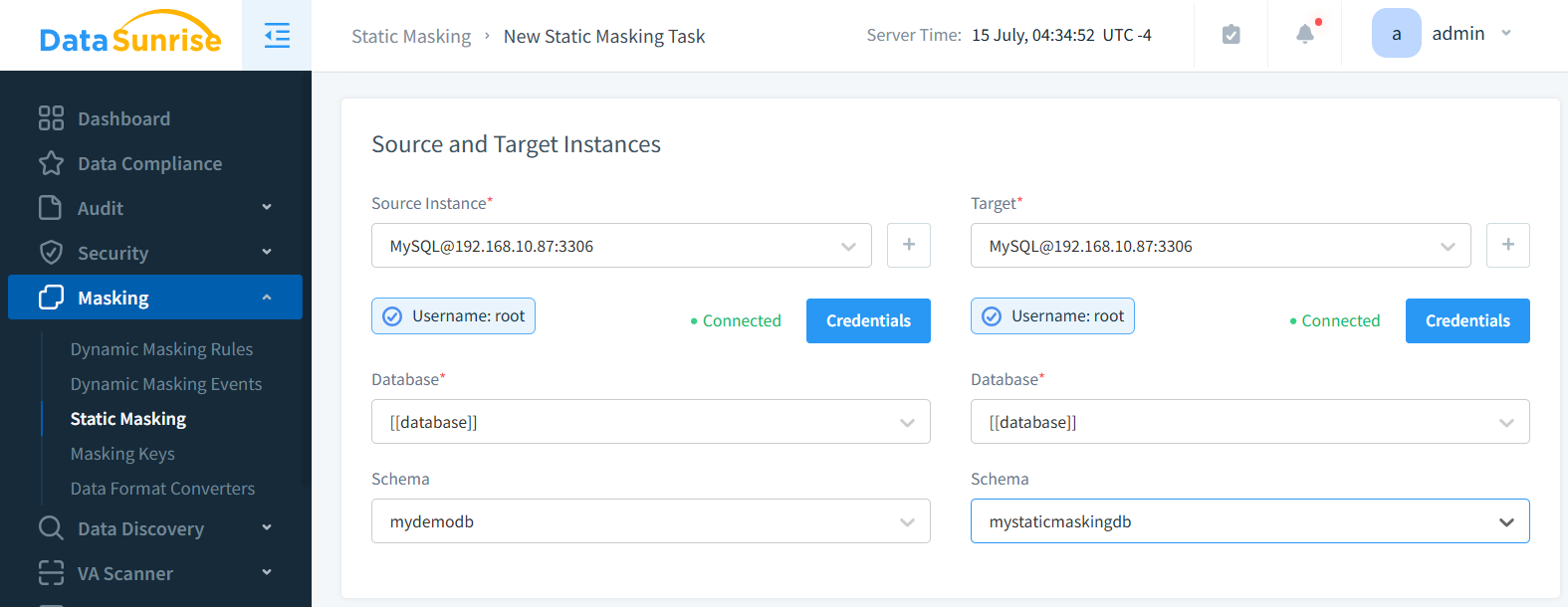
Data Masking
Data masking involves modifying sensitive information in a dataset while maintaining its format and statistical properties. This method allows you to use production-like data without exposing confidential information.
DataSunrise’s data masking solution stands out as a powerful and versatile tool in the realm of data privacy and security. This feature-rich implementation offers organizations a robust way to protect sensitive information while maintaining data utility for testing, development, and analytics purposes.
Common Data Masking Techniques:
- Substitution: Replace sensitive values with fictitious but realistic alternatives.
- Shuffling: Rearrange data within a column to break the association between records.
- Encryption: Transform data using encryption algorithms.
Open-Source Datasets
Many organizations and institutions provide open-source datasets that can be used for testing purposes. These datasets often come from real-world scenarios but have been anonymized and cleared for public use.
Sources for Open-Source Datasets:
- Government data portals
- Academic research repositories
- Data science competition platforms (e.g., Kaggle)
Creating Custom Test Data
Using Python and the Faker library, you can easily generate random data with function calls like these:
fake.name()
fake.email()
You can find some examples on data generation in our articles on synthetic data and AI data generators.
Best Practices for Data Bottleneck Testing
To ensure the effectiveness of your data bottleneck tests, consider these best practices:
- Start Small: Begin with simple test scenarios and gradually increase complexity.
- Isolate Components: Test individual system components before running end-to-end tests.
- Use Realistic Data Volumes: Ensure your test data reflects real-world usage patterns.
- Monitor Resource Utilization: Keep an eye on CPU, memory, and I/O usage during tests.
- Repeat Tests: Run multiple iterations to account for variability and confirm results.
- Document Everything: Keep detailed records of test configurations, results, and observations.
Tools for Data Bottleneck Testing and DataSunrise
Several tools can assist in conducting data bottleneck tests:
- Apache JMeter: Open-source tool for load testing and performance measurement.
- Gatling: Scala-based load testing tool for analyzing and measuring system performance.
- Locust: Python-based tool for distributed load testing.
- iperf3: Network performance measurement tool.
DataSunrise Solution
Key advantages of DataSunrise’s approach to bottleneck testing include:
- Intuitive Interface: Designed with user experience in mind, allowing even non-experts to set up and run sophisticated tests.
- Highly Customizable: Offers a wide range of parameters and scenarios that can be easily adjusted to match specific testing requirements.
- Comprehensive Coverage: Capable of testing various aspects of database performance, from query execution to data transfer rates.
- Automated Test Generation: Intelligently creates test scenarios based on actual database usage patterns, reducing manual configuration time.
- Real-time Monitoring: Provides live insights during test execution, allowing for immediate identification of bottlenecks.
- Detailed Reporting: Generates in-depth, easy-to-understand reports that highlight performance issues and suggest optimizations.
- Integration Capabilities: Seamlessly works with various database systems and can be integrated into existing development and testing workflows.
- Scalability: Handles testing for databases of all sizes, from small applications to large enterprise systems.
Interpreting Test Results
After conducting your data bottleneck tests, careful analysis is crucial. Look for:
- Unexpected spikes in resource utilization
- Consistent performance degradation under specific conditions
- Discrepancies between components that should have similar performance
Remember, the goal is not just to identify bottlenecks but to understand their root causes and develop effective solutions.
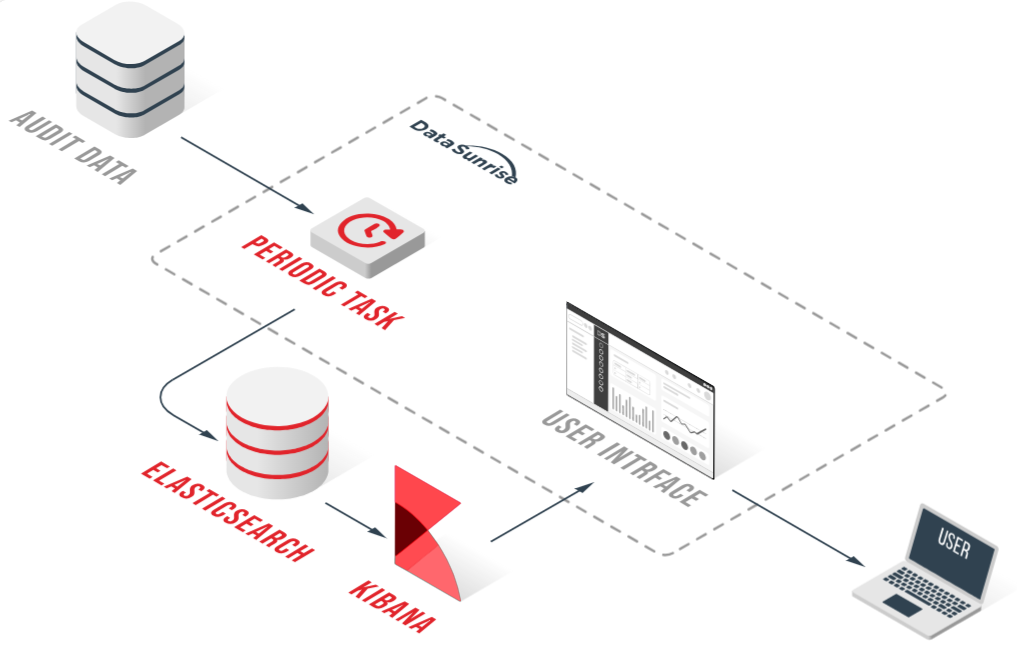
By leveraging DataSunrise’s Audit integration, organizations can gain deep, actionable insights into their database performance, enabling proactive optimization and efficient bottleneck identification.
Conclusion
Data bottleneck tests are invaluable tools for optimizing system performance. Learn the basics of tests and find the right data to identify and fix performance issues in your systems effectively. When testing, make sure the data accurately reflects real-life situations and keeps secure.
You can use synthetic data, masked production data, or custom-generated datasets for this purpose. You can use synthetic data, masked production data, or custom-generated datasets for this purpose.
As you embark on your data bottleneck testing journey, remember that it’s an iterative process. Continual testing and optimization will help you maintain peak system performance in the face of evolving data processing demands.
For those seeking user-friendly and flexible tools for database security, including highly useful synthetic data and data masking capabilities, consider exploring DataSunrise’s offerings. Our comprehensive suite of tools can greatly simplify the process of generating and managing test data for your bottleneck tests while ensuring data privacy and compliance. Visit the DataSunrise website to see a demo. You can also learn how our solutions can help you with data management and testing.
