
Data Discovery
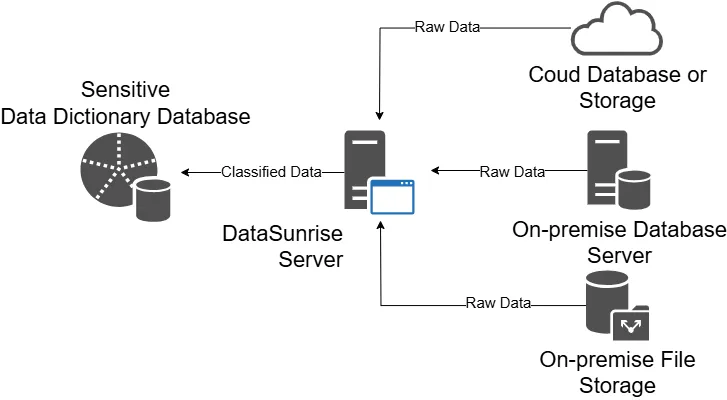
Have you ever asked yourself, what metrics are available in your data? Are there metrics for Churn Rate and Retention Rate available? Or maybe you are struggling with compliance procedures, asking yourself, ‘Am I in danger of sensitive data leakage?’ Data discovery is a crucial process that helps businesses and organizations make sense of their vast data assets. It includes looking at data from different places to find trends, patterns, and types of data.
Companies can discover important insights and improve business intelligence by understanding their data better. This also helps with data security, governance, and privacy. When data pipeline failed data discovery helps with finding what’s wrong with the data.
The Power of Data Discovery
Organizations today may have an overwhelming amount of data to handle. This can result in “dark data” that remains unused. Dark data can potentially create legal and security risks. There are several reasons to implement data discovery.

Analysts can use data catalogs and dictionaries to find and organize scattered data. They can then clean and combine the data to discover important insights.
Enhancing Data Discovery with AI and Machine Learning
DataSunrise makes great use of ML tools for data security. Artificial Intelligence (AI) is transforming data discovery processes in data governance. By harnessing AI and machine learning, organizations can streamline their data exploration efforts. This leads to faster insights and more efficient decision-making.
AI enhances data discovery in several key ways:
- Automating data classification
- Identifying patterns and anomalies
- Suggesting relevant data sources
Machine learning algorithms excel at categorizing vast amounts of information. This automated data classification saves time and reduces human error. It’s particularly useful when dealing with large datasets.
Data Discovery in Data Science
Data discovery forms the foundation of successful data science projects. It’s the process of finding and understanding available data sources. Through this exploration, data scientists uncover valuable insights and patterns. Effective data discovery involves several key steps:
- Identifying relevant data sources
- Assessing data quality and completeness
- Performing initial data analysis
Data classification plays a vital role in this process. By categorizing information, scientists can better organize and prioritize their work. This classification helps in handling sensitive data appropriately.
DataSunrise offers excellent support for data storage and warehouses commonly used in data science, including Snowflake, Amazon Redshift, and Athena, just to mention a few.
Since data science heavily utilizes semi-structured data, DataSunrise supports data discovery in raw formats (CSV, JSON) located in storages like S3 or in your filesystem.
Empowering Business Intelligence with Data Discovery
Data discovery plays a vital role in empowering business intelligence initiatives.
Giving analysts the right tools and techniques helps organizations make better decisions, improve processes, and find opportunities for growth.
The dashboards can be changed to suit different groups of people, such as executives and front-line employees. This way, everyone can easily find the information they need to make decisions.
Data Security and Compliance with Python-based Data Discovery
Okay, you may say, there are tens of open-source Python tools available on the market. All I need to do is take a couple and create my own data discovery toolchain.
And this is a totally fine idea for a couple of reasons. You will know everything about your tools, and you will be able to implement any data discovery you want in the future. Moreover, this simple toolchain total cost of ownership is only your time to write some code.
The possible drawback is the following: it may take a while to implement all the variations you want. You may struggle with the difficulty of scalability and supporting your system as new databases come out and change their driver behavior.
Here is the code to discover emails in a PostgreSQL database. It should work with your database connection parameters. You may notice that while it’s not rocket science, it still requires some knowledge of infrastructure and Python. And this code doesn’t store the search results.
import psycopg2
import re
# Define connection parameters
db_params = {
'dbname': 'mydatabase01',
'user': 'postgres',
'password': 'pass',
'host': 'localhost'
}
# Connect to the database
try:
conn = psycopg2.connect(**db_params)
print("Connected to the database")
except Exception as e:
print(f"Unable to connect to the database: {e}")
exit()
# Function to find email addresses in a schema
def find_emails_in_schema(schema):
try:
cursor = conn.cursor()
# Query to find all tables in the specified schema
cursor.execute(f"""
SELECT table_name
FROM information_schema.tables
WHERE table_schema = '{schema}'
""")
tables = cursor.fetchall()
email_pattern = re.compile(r'[\w\.-]+@[\w\.-]+')
for table in tables:
table_name = table[0]
# Query to select all columns from the table
cursor.execute(f"""
SELECT column_name
FROM information_schema.columns
WHERE table_schema = '{schema}'
AND table_name = '{table_name}'
""")
columns = cursor.fetchall()
# Select all data from the table
cursor.execute(f'SELECT * FROM {schema}.{table_name}')
rows = cursor.fetchall()
for row in rows:
for column, value in zip(columns, row):
if value and isinstance(value, str):
if email_pattern.search(value):
print(f'Found email: {value} in table: {table_name}, column: {column[0]}')
except Exception as e:
print(f"Error finding emails: {e}")
finally:
cursor.close()
# Specify the schema to search
schema_name = 'public'
find_emails_in_schema(schema_name)
# Close the connection
conn.close()
The code prints lines like following:
Found email: sclutten0@facebook.com in table: mock_data, column: email
DataSunrise Tools
DataSunrise includes all the features you need for sensitive (or any) data discovery. Below, we provide a couple of examples from its UI.
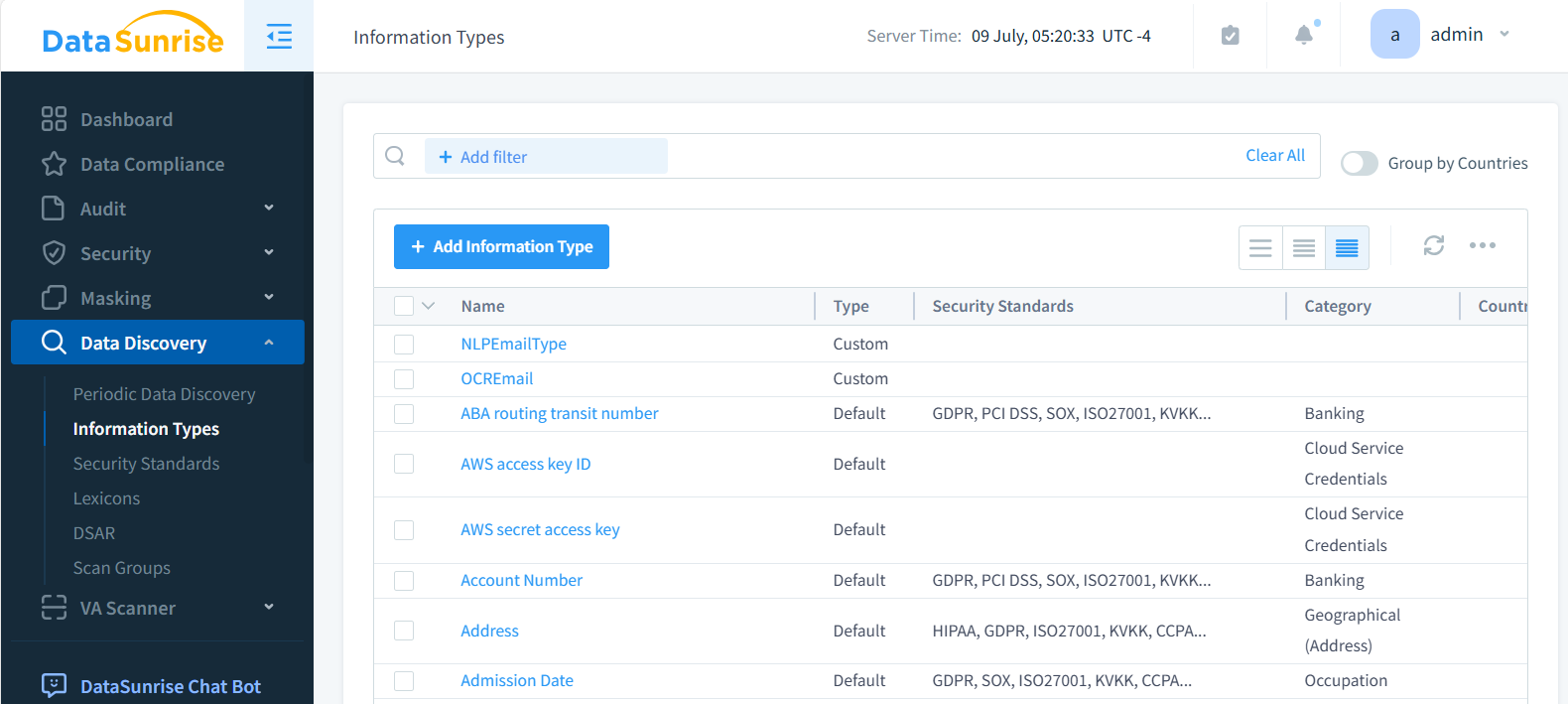
The following is an Information Types listing. You can create as many custom information types as you want, each with one or several attributes for discovery. You can also use dozens of built-in types if you prefer.
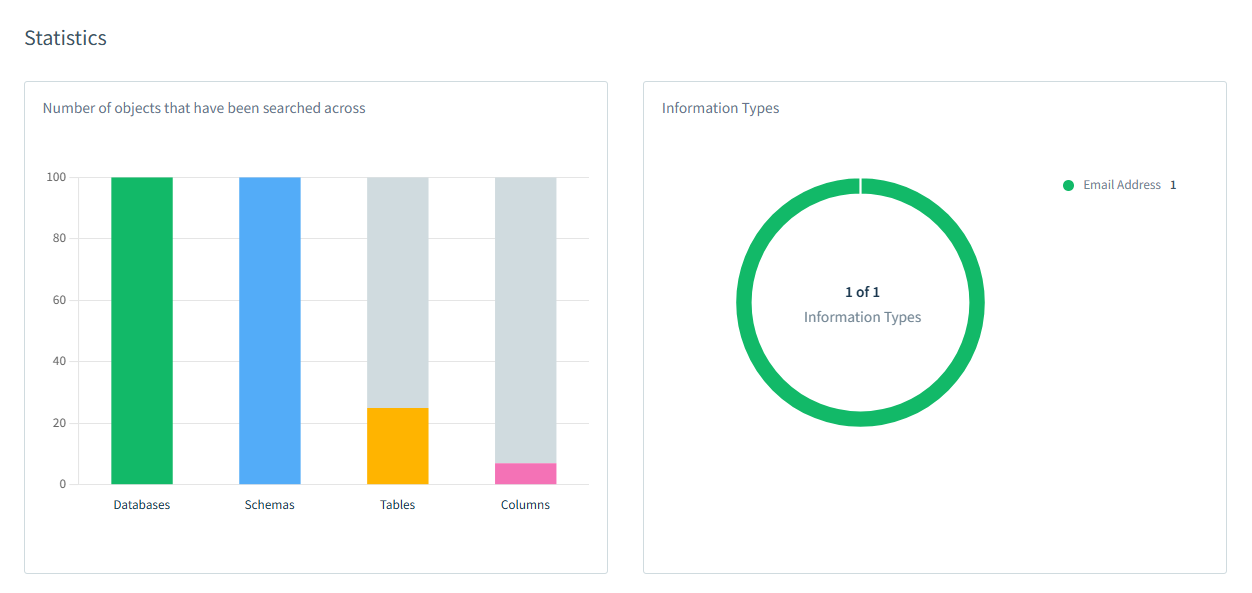
After the discovery task finishes, you can see detailed information on the findings. Additionally, you can estimate the amount of discovered data relative to the total amount in your schemas, tables, or columns. The picture below shows that email addresses were found in 100% of the target databases, 100% of schemas, 22% of tables, and less than 5% of columns.
Conclusion
Data discovery is a critical process that enables organizations to unlock the full potential of their data assets.
Businesses can use advanced technologies like AI, machine learning, and data analytics to better understand their data. Businesses can use analyzing data to find patterns and trends, helping them make better decisions and promote innovation.
These technologies can also help businesses generate new ideas by uncovering hidden opportunities and predicting future market trends.
In addition, advanced technologies can help businesses protect sensitive information by implementing robust security measures such as encryption, access controls, and threat detection systems. Protecting data helps businesses avoid data breaches and cyber attacks, keeping their information safe and secure.
Using advanced technologies can help businesses use their data better, be more innovative, and protect their sensitive information. This can lead to better performance and a competitive edge in the market.
As data grows, it’s important for organizations to invest in tools for data discovery to stay ahead.
DataSunrise provides a wide variety of means to discover data. Contact our team to book a demo and learn how to do it now.
